 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Jun 26, 2024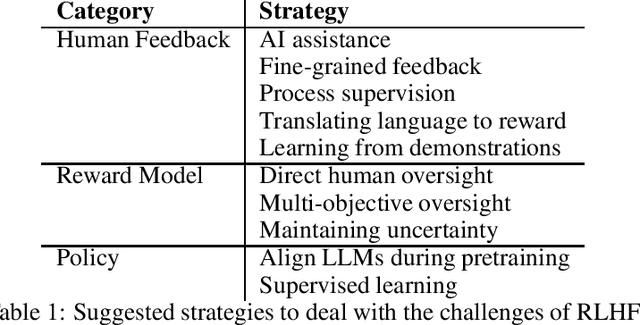
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
AI-as-exploration: Navigating intelligence space
Feb 05, 2024Artificial Intelligence is a field that lives many lives, and the term has come to encompass a motley collection of scientific and commercial endeavours. In this paper, I articulate the contours of a rather neglected but central scientific role that AI has to play, which I dub `AI-as-exploration'.The basic thrust of AI-as-exploration is that of creating and studying systems that can reveal candidate building blocks of intelligence that may differ from the forms of human and animal intelligence we are familiar with. In other words, I suggest that AI is one of the best tools we have for exploring intelligence space, namely the space of possible intelligent systems. I illustrate the value of AI-as-exploration by focusing on a specific case study, i.e., recent work on the capacity to combine novel and invented concepts in humans and Large Language Models. I show that the latter, despite showing human-level accuracy in such a task, most probably solve it in ways radically different, but no less relevant to intelligence research, to those hypothesised for humans.
ACROCPoLis: A Descriptive Framework for Making Sense of Fairness
Apr 19, 2023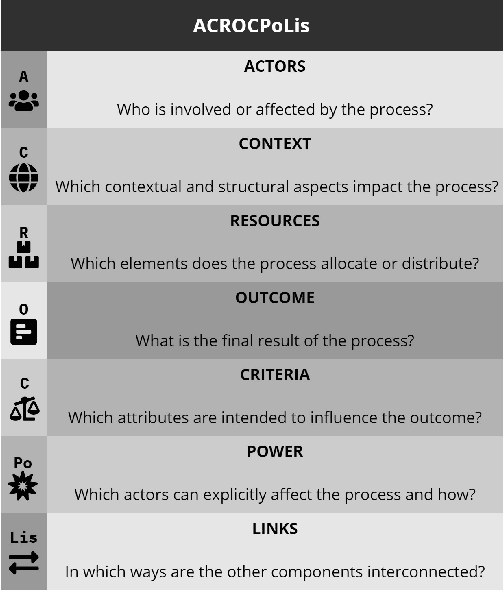
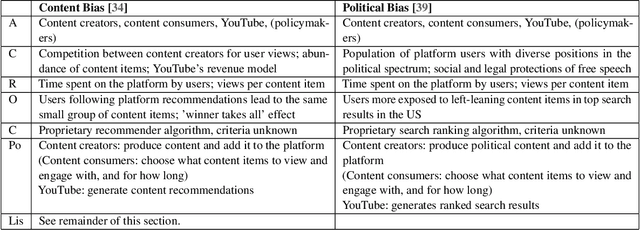
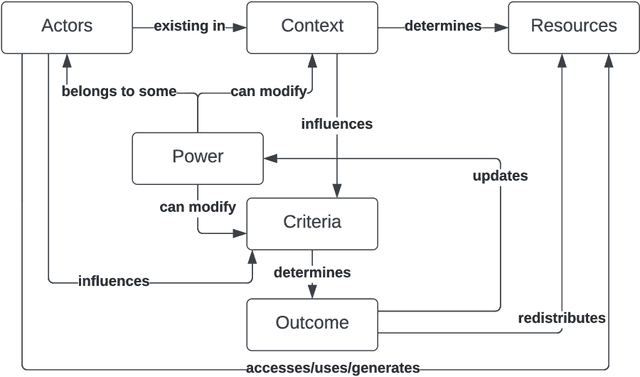
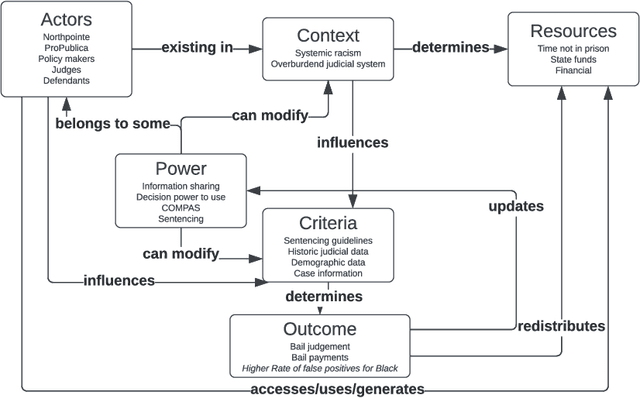
Fairness is central to the ethical and responsible development and use of AI systems, with a large number of frameworks and formal notions of algorithmic fairness being available. However, many of the fairness solutions proposed revolve around technical considerations and not the needs of and consequences for the most impacted communities. We therefore want to take the focus away from definitions and allow for the inclusion of societal and relational aspects to represent how the effects of AI systems impact and are experienced by individuals and social groups. In this paper, we do this by means of proposing the ACROCPoLis framework to represent allocation processes with a modeling emphasis on fairness aspects. The framework provides a shared vocabulary in which the factors relevant to fairness assessments for different situations and procedures are made explicit, as well as their interrelationships. This enables us to compare analogous situations, to highlight the differences in dissimilar situations, and to capture differing interpretations of the same situation by different stakeholders.
The Vector Grounding Problem
Apr 04, 2023The remarkable performance of large language models (LLMs) on complex linguistic tasks has sparked a lively debate on the nature of their capabilities. Unlike humans, these models learn language exclusively from textual data, without direct interaction with the real world. Nevertheless, they can generate seemingly meaningful text about a wide range of topics. This impressive accomplishment has rekindled interest in the classical 'Symbol Grounding Problem,' which questioned whether the internal representations and outputs of classical symbolic AI systems could possess intrinsic meaning. Unlike these systems, modern LLMs are artificial neural networks that compute over vectors rather than symbols. However, an analogous problem arises for such systems, which we dub the Vector Grounding Problem. This paper has two primary objectives. First, we differentiate various ways in which internal representations can be grounded in biological or artificial systems, identifying five distinct notions discussed in the literature: referential, sensorimotor, relational, communicative, and epistemic grounding. Unfortunately, these notions of grounding are often conflated. We clarify the differences between them, and argue that referential grounding is the one that lies at the heart of the Vector Grounding Problem. Second, drawing on theories of representational content in philosophy and cognitive science, we propose that certain LLMs, particularly those fine-tuned with Reinforcement Learning from Human Feedback (RLHF), possess the necessary features to overcome the Vector Grounding Problem, as they stand in the requisite causal-historical relations to the world that underpin intrinsic meaning. We also argue that, perhaps unexpectedly, multimodality and embodiment are neither necessary nor sufficient conditions for referential grounding in artificial systems.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.