 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Jul 17, 2025Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
AI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Jun 26, 2024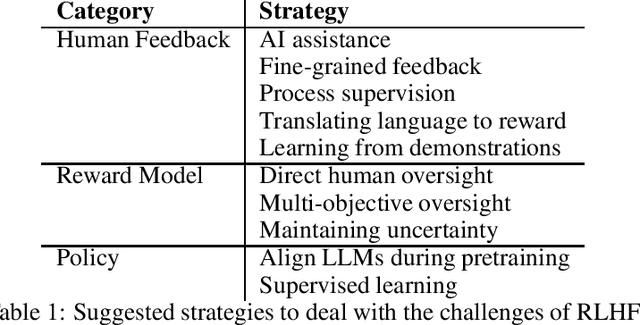
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
ACROCPoLis: A Descriptive Framework for Making Sense of Fairness
Apr 19, 2023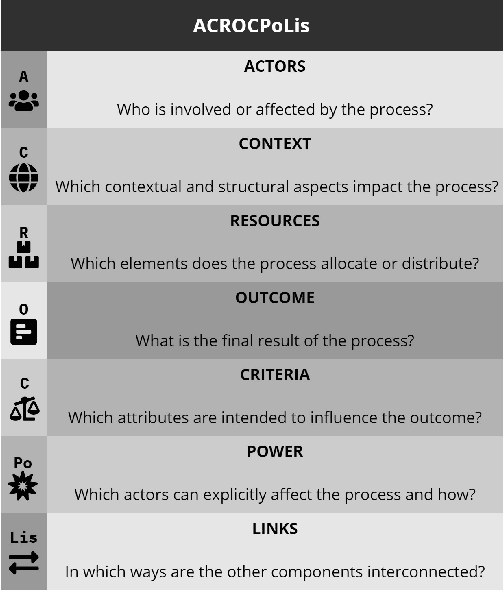
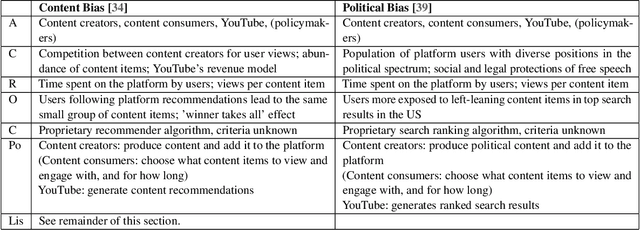
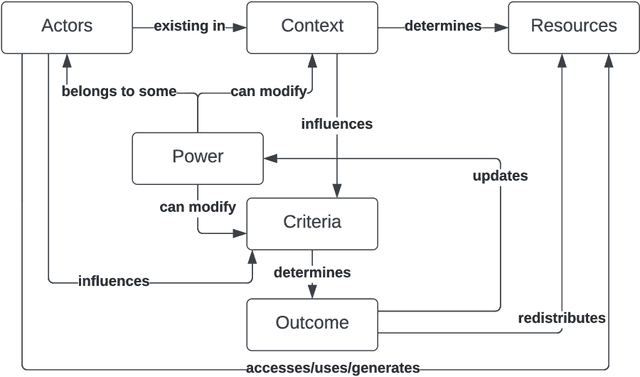
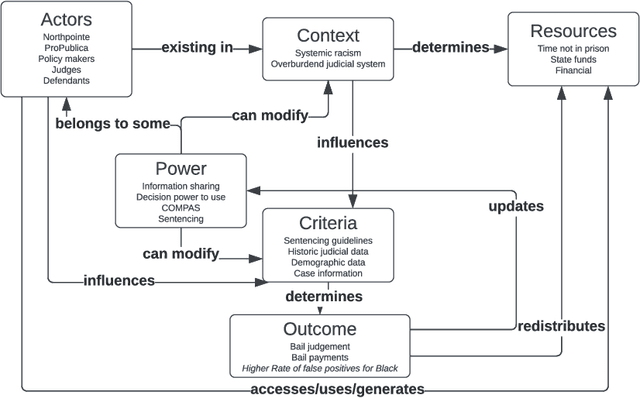
Fairness is central to the ethical and responsible development and use of AI systems, with a large number of frameworks and formal notions of algorithmic fairness being available. However, many of the fairness solutions proposed revolve around technical considerations and not the needs of and consequences for the most impacted communities. We therefore want to take the focus away from definitions and allow for the inclusion of societal and relational aspects to represent how the effects of AI systems impact and are experienced by individuals and social groups. In this paper, we do this by means of proposing the ACROCPoLis framework to represent allocation processes with a modeling emphasis on fairness aspects. The framework provides a shared vocabulary in which the factors relevant to fairness assessments for different situations and procedures are made explicit, as well as their interrelationships. This enables us to compare analogous situations, to highlight the differences in dissimilar situations, and to capture differing interpretations of the same situation by different stakeholders.
CLEVR-Math: A Dataset for Compositional Language, Visual and Mathematical Reasoning
Aug 10, 2022


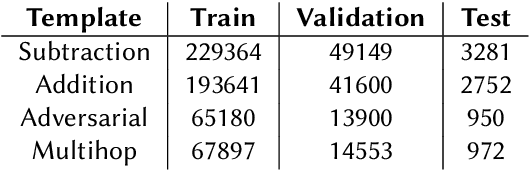
We introduce CLEVR-Math, a multi-modal math word problems dataset consisting of simple math word problems involving addition/subtraction, represented partly by a textual description and partly by an image illustrating the scenario. The text describes actions performed on the scene that is depicted in the image. Since the question posed may not be about the scene in the image, but about the state of the scene before or after the actions are applied, the solver envision or imagine the state changes due to these actions. Solving these word problems requires a combination of language, visual and mathematical reasoning. We apply state-of-the-art neural and neuro-symbolic models for visual question answering on CLEVR-Math and empirically evaluate their performances. Our results show how neither method generalise to chains of operations. We discuss the limitations of the two in addressing the task of multi-modal word problem solving.
An Algebraic Approach to Learning and Grounding
Apr 06, 2022

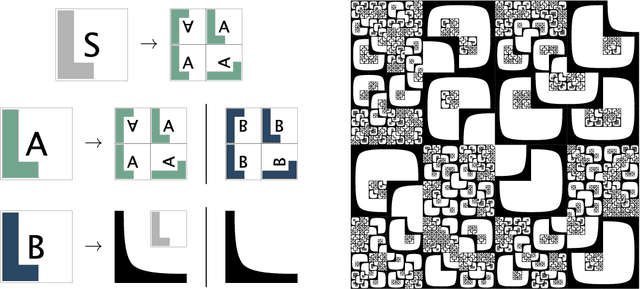
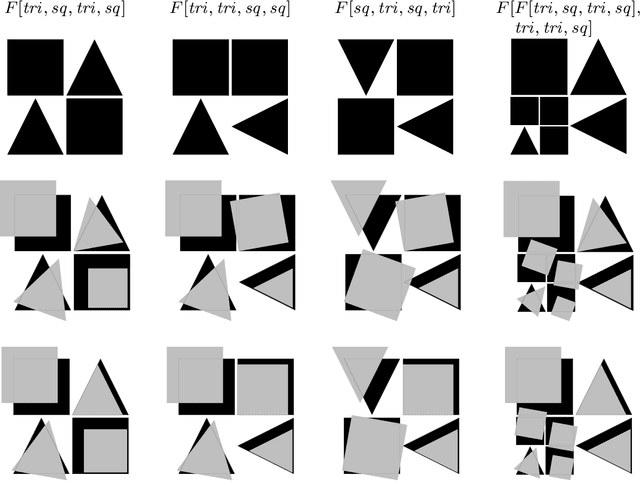
We consider the problem of learning the semantics of composite algebraic expressions from examples. The outcome is a versatile framework for studying learning tasks that can be put into the following abstract form: The input is a partial algebra A and a finite set of samples ({\phi}1, O1), ({\phi}2, O2), ..., each consisting of an algebraic term {\phi}i and a set of objects Oi. The objective is to simultaneously fill in the missing algebraic operations in A and ground the variables of every {\phi}i in Oi, so that the combined value of the terms is optimised. We demonstrate the applicability of this framework through case studies in grammatical inference, picture-language learning, and the grounding of logic scene descriptions.
Probing Multimodal Embeddings for Linguistic Properties: the Visual-Semantic Case
Feb 22, 2021
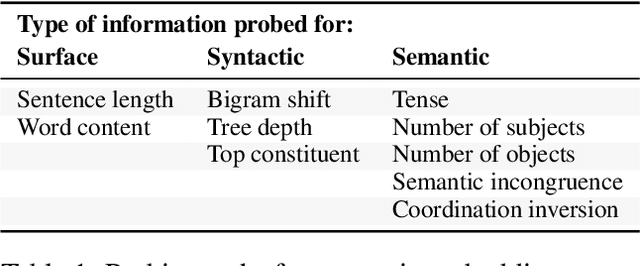

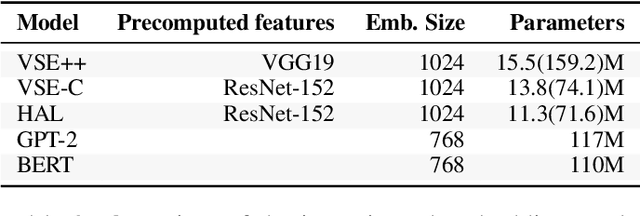
Semantic embeddings have advanced the state of the art for countless natural language processing tasks, and various extensions to multimodal domains, such as visual-semantic embeddings, have been proposed. While the power of visual-semantic embeddings comes from the distillation and enrichment of information through machine learning, their inner workings are poorly understood and there is a shortage of analysis tools. To address this problem, we generalize the notion of probing tasks to the visual-semantic case. To this end, we (i) discuss the formalization of probing tasks for embeddings of image-caption pairs, (ii) define three concrete probing tasks within our general framework, (iii) train classifiers to probe for those properties, and (iv) compare various state-of-the-art embeddings under the lens of the proposed probing tasks. Our experiments reveal an up to 12% increase in accuracy on visual-semantic embeddings compared to the corresponding unimodal embeddings, which suggest that the text and image dimensions represented in the former do complement each other.