 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Precision to Perception: User-Centred Evaluation of Keyword Extraction Algorithms for Internet-Scale Contextual Advertising
Apr 30, 2025



Keyword extraction is a foundational task in natural language processing, underpinning countless real-world applications. A salient example is contextual advertising, where keywords help predict the topical congruence between ads and their surrounding media contexts to enhance advertising effectiveness. Recent advances in artificial intelligence, particularly large language models, have improved keyword extraction capabilities but also introduced concerns about computational cost. Moreover, although the end-user experience is of vital importance, human evaluation of keyword extraction performances remains under-explored. This study provides a comparative evaluation of three prevalent keyword extraction algorithms that vary in complexity: TF-IDF, KeyBERT, and Llama 2. To evaluate their effectiveness, a mixed-methods approach is employed, combining quantitative benchmarking with qualitative assessments from 552 participants through three survey-based experiments. Findings indicate a slight user preference for KeyBERT, which offers a favourable balance between performance and computational efficiency compared to the other two algorithms. Despite a strong overall preference for gold-standard keywords, differences between the algorithmic outputs are not statistically significant, highlighting a long-overlooked gap between traditional precision-focused metrics and user-perceived algorithm efficiency. The study highlights the importance of user-centred evaluation methodologies and proposes analytical tools to support their implementation.
How ChatGPT Changed the Media's Narratives on AI: A Semi-Automated Narrative Analysis Through Frame Semantics
Aug 12, 2024The recent explosion of attention to AI is arguably one of the biggest in the technology's media coverage. To investigate the effects it has on the discourse, we perform a mixed-method frame semantics-based analysis on a dataset of more than 49,000 sentences collected from 5846 news articles that mention AI. The dataset covers the twelve-month period centred around the launch of OpenAI's chatbot ChatGPT and is collected from the most visited open-access English-language news publishers. Our findings indicate that during the half year succeeding the launch, media attention rose tenfold$\unicode{x2014}$from already historically high levels. During this period, discourse has become increasingly centred around experts and political leaders, and AI has become more closely associated with dangers and risks. A deeper review of the data also suggests a qualitative shift in the types of threat AI is thought to represent, as well as the anthropomorphic qualities ascribed to it.
Generating Semantic Graph Corpora with Graph Expansion Grammar
Sep 15, 2023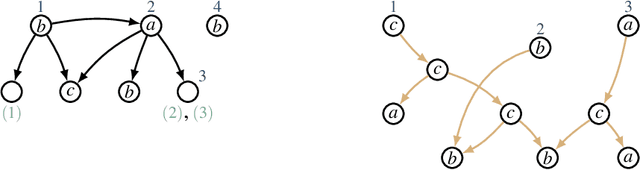
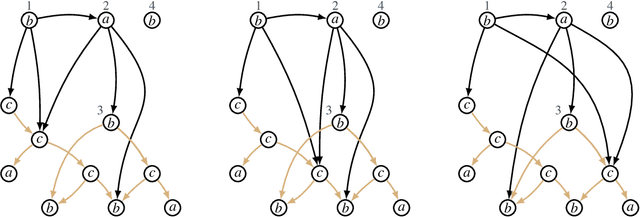

We introduce Lovelace, a tool for creating corpora of semantic graphs. The system uses graph expansion grammar as a representational language, thus allowing users to craft a grammar that describes a corpus with desired properties. When given such grammar as input, the system generates a set of output graphs that are well-formed according to the grammar, i.e., a graph bank. The generation process can be controlled via a number of configurable parameters that allow the user to, for example, specify a range of desired output graph sizes. Central use cases are the creation of synthetic data to augment existing corpora, and as a pedagogical tool for teaching formal language theory.
* In Proceedings NCMA 2023, arXiv:2309.07333
AI-Driven Contextual Advertising: A Technology Report and Implication Analysis
May 02, 2022
Programmatic advertising consists in automated auctioning of digital ad space. Every time a user requests a web page, placeholders on the page are populated with ads from the highest-bidding advertisers. The bids are typically based on information about the user, and to an increasing extent, on information about the surrounding media context. The growing interest in contextual advertising is in part a counterreaction to the current dependency on personal data, which is problematic from legal and ethical standpoints. The transition is further accelerated by developments in Artificial Intelligence (AI), which allow for a deeper semantic understanding of context and, by extension, more effective ad placement. In this article, we begin by identifying context factors that have been shown in previous research to positively influence how ads are received. We then continue to discuss applications of AI in contextual advertising, where it adds value by, e.g., extracting high-level information about media context and optimising bidding strategies. However, left unchecked, these new practices can lead to unfair ad delivery and manipulative use of context. We summarize these and other concerns for consumers, publishers and advertisers in an implication analysis.
An Algebraic Approach to Learning and Grounding
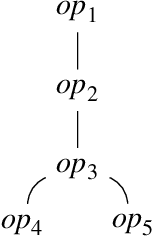
Apr 06, 2022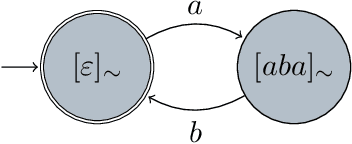

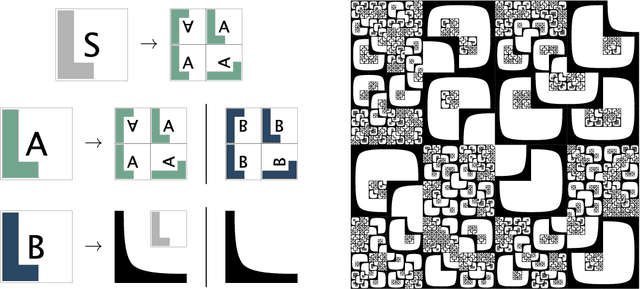
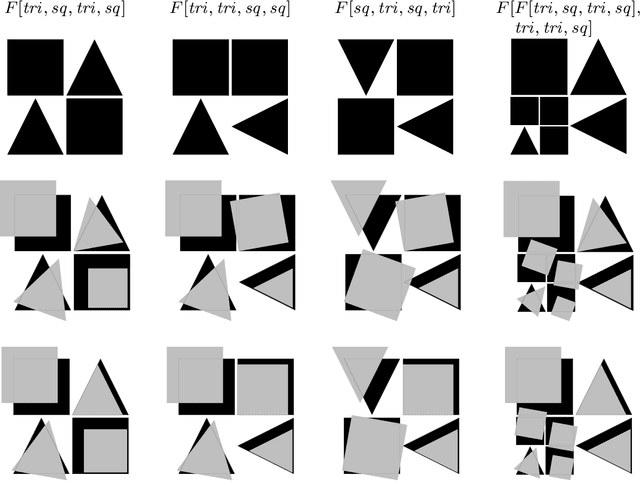
We consider the problem of learning the semantics of composite algebraic expressions from examples. The outcome is a versatile framework for studying learning tasks that can be put into the following abstract form: The input is a partial algebra A and a finite set of samples ({\phi}1, O1), ({\phi}2, O2), ..., each consisting of an algebraic term {\phi}i and a set of objects Oi. The objective is to simultaneously fill in the missing algebraic operations in A and ground the variables of every {\phi}i in Oi, so that the combined value of the terms is optimised. We demonstrate the applicability of this framework through case studies in grammatical inference, picture-language learning, and the grounding of logic scene descriptions.
Polynomial Graph Parsing with Non-Structural Reentrancies
May 07, 2021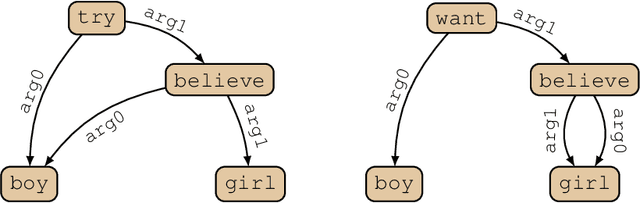

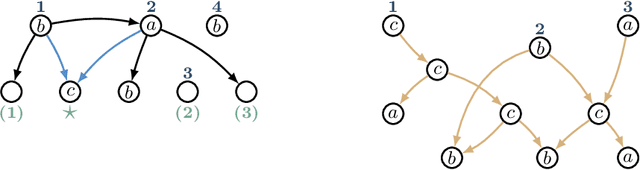
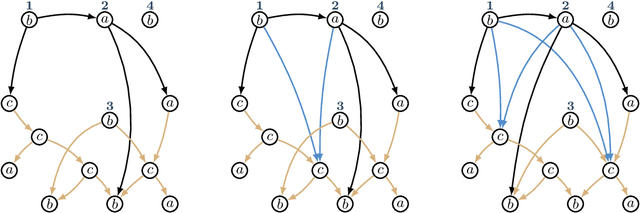
Graph-based semantic representations are valuable in natural language processing, where it is often simple and effective to represent linguistic concepts as nodes, and relations as edges between them. Several attempts has been made to find a generative device that is sufficiently powerful to represent languages of semantic graphs, while at the same allowing efficient parsing. We add to this line of work by introducing graph extension grammar, which consists of an algebra over graphs together with a regular tree grammar that generates expressions over the operations of the algebra. Due to the design of the operations, these grammars can generate graphs with non-structural reentrancies; a type of node-sharing that is excessively common in formalisms such as abstract meaning representation, but for which existing devices offer little support. We provide a parsing algorithm for graph extension grammars, which is proved to be correct and run in polynomial time.
Probing Multimodal Embeddings for Linguistic Properties: the Visual-Semantic Case
Feb 22, 2021
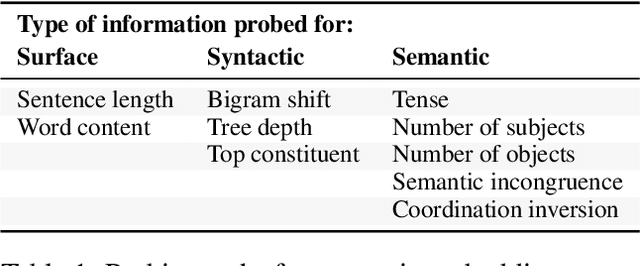

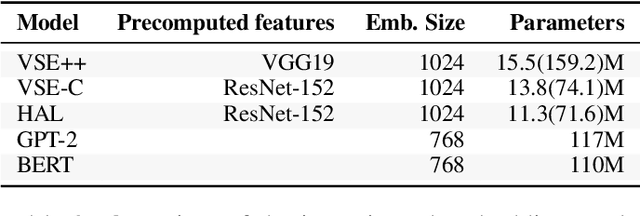
Semantic embeddings have advanced the state of the art for countless natural language processing tasks, and various extensions to multimodal domains, such as visual-semantic embeddings, have been proposed. While the power of visual-semantic embeddings comes from the distillation and enrichment of information through machine learning, their inner workings are poorly understood and there is a shortage of analysis tools. To address this problem, we generalize the notion of probing tasks to the visual-semantic case. To this end, we (i) discuss the formalization of probing tasks for embeddings of image-caption pairs, (ii) define three concrete probing tasks within our general framework, (iii) train classifiers to probe for those properties, and (iv) compare various state-of-the-art embeddings under the lens of the proposed probing tasks. Our experiments reveal an up to 12% increase in accuracy on visual-semantic embeddings compared to the corresponding unimodal embeddings, which suggest that the text and image dimensions represented in the former do complement each other.