 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficiency of Pre-training with Objective Masking in Pseudo Labeling for Semi-Supervised Text Classification
May 10, 2025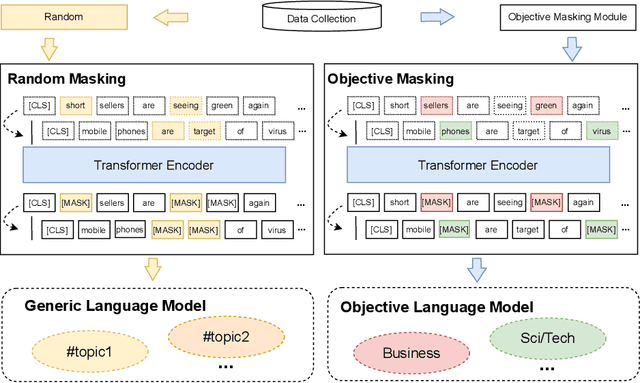

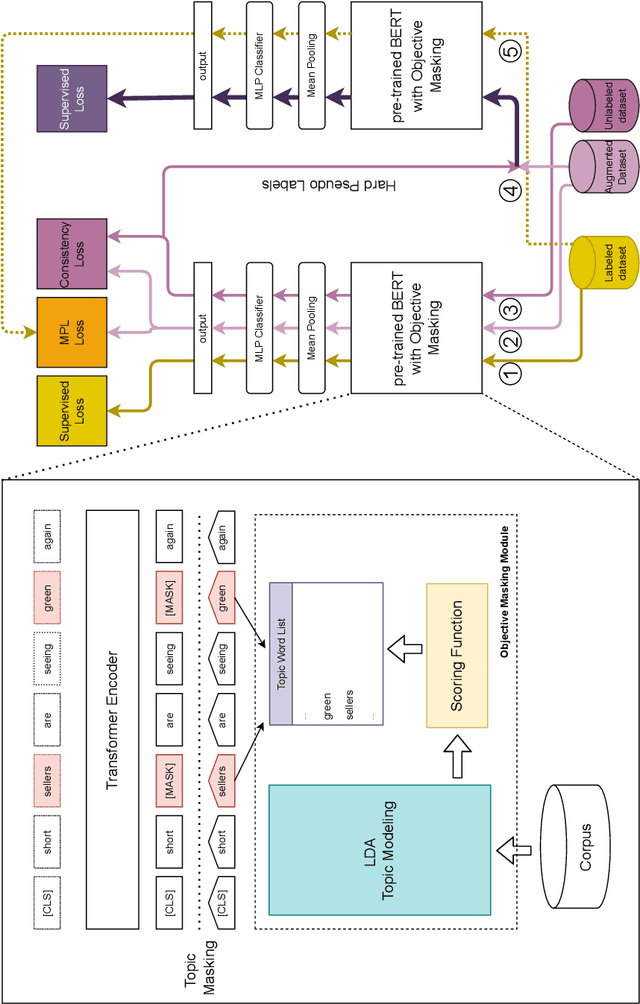

We extend and study a semi-supervised model for text classification proposed earlier by Hatefi et al. for classification tasks in which document classes are described by a small number of gold-labeled examples, while the majority of training examples is unlabeled. The model leverages the teacher-student architecture of Meta Pseudo Labels in which a ''teacher'' generates labels for originally unlabeled training data to train the ''student'' and updates its own model iteratively based on the performance of the student on the gold-labeled portion of the data. We extend the original model of Hatefi et al. by an unsupervised pre-training phase based on objective masking, and conduct in-depth performance evaluations of the original model, our extension, and various independent baselines. Experiments are performed using three different datasets in two different languages (English and Swedish).
Generating Semantic Graph Corpora with Graph Expansion Grammar
Sep 15, 2023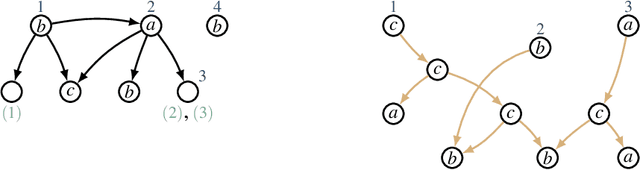
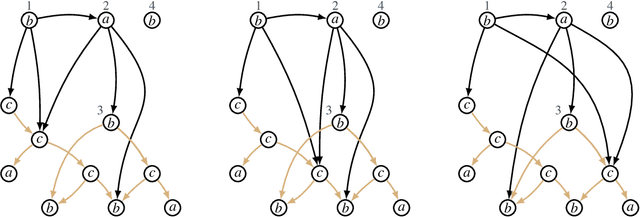

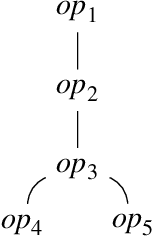
We introduce Lovelace, a tool for creating corpora of semantic graphs. The system uses graph expansion grammar as a representational language, thus allowing users to craft a grammar that describes a corpus with desired properties. When given such grammar as input, the system generates a set of output graphs that are well-formed according to the grammar, i.e., a graph bank. The generation process can be controlled via a number of configurable parameters that allow the user to, for example, specify a range of desired output graph sizes. Central use cases are the creation of synthetic data to augment existing corpora, and as a pedagogical tool for teaching formal language theory.
* In Proceedings NCMA 2023, arXiv:2309.07333
An Algebraic Approach to Learning and Grounding
Apr 06, 2022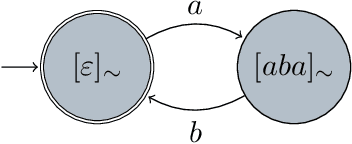

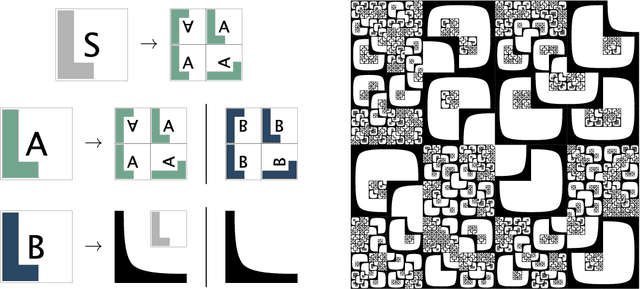
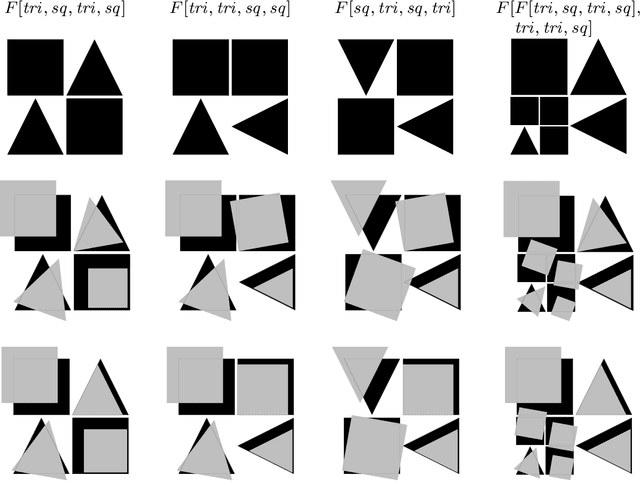
We consider the problem of learning the semantics of composite algebraic expressions from examples. The outcome is a versatile framework for studying learning tasks that can be put into the following abstract form: The input is a partial algebra A and a finite set of samples ({\phi}1, O1), ({\phi}2, O2), ..., each consisting of an algebraic term {\phi}i and a set of objects Oi. The objective is to simultaneously fill in the missing algebraic operations in A and ground the variables of every {\phi}i in Oi, so that the combined value of the terms is optimised. We demonstrate the applicability of this framework through case studies in grammatical inference, picture-language learning, and the grounding of logic scene descriptions.
Polynomial Graph Parsing with Non-Structural Reentrancies
May 07, 2021

Graph-based semantic representations are valuable in natural language processing, where it is often simple and effective to represent linguistic concepts as nodes, and relations as edges between them. Several attempts has been made to find a generative device that is sufficiently powerful to represent languages of semantic graphs, while at the same allowing efficient parsing. We add to this line of work by introducing graph extension grammar, which consists of an algebra over graphs together with a regular tree grammar that generates expressions over the operations of the algebra. Due to the design of the operations, these grammars can generate graphs with non-structural reentrancies; a type of node-sharing that is excessively common in formalisms such as abstract meaning representation, but for which existing devices offer little support. We provide a parsing algorithm for graph extension grammars, which is proved to be correct and run in polynomial time.
Probing Multimodal Embeddings for Linguistic Properties: the Visual-Semantic Case
Feb 22, 2021

Semantic embeddings have advanced the state of the art for countless natural language processing tasks, and various extensions to multimodal domains, such as visual-semantic embeddings, have been proposed. While the power of visual-semantic embeddings comes from the distillation and enrichment of information through machine learning, their inner workings are poorly understood and there is a shortage of analysis tools. To address this problem, we generalize the notion of probing tasks to the visual-semantic case. To this end, we (i) discuss the formalization of probing tasks for embeddings of image-caption pairs, (ii) define three concrete probing tasks within our general framework, (iii) train classifiers to probe for those properties, and (iv) compare various state-of-the-art embeddings under the lens of the proposed probing tasks. Our experiments reveal an up to 12% increase in accuracy on visual-semantic embeddings compared to the corresponding unimodal embeddings, which suggest that the text and image dimensions represented in the former do complement each other.