 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Precision to Perception: User-Centred Evaluation of Keyword Extraction Algorithms for Internet-Scale Contextual Advertising
Apr 30, 2025



Keyword extraction is a foundational task in natural language processing, underpinning countless real-world applications. A salient example is contextual advertising, where keywords help predict the topical congruence between ads and their surrounding media contexts to enhance advertising effectiveness. Recent advances in artificial intelligence, particularly large language models, have improved keyword extraction capabilities but also introduced concerns about computational cost. Moreover, although the end-user experience is of vital importance, human evaluation of keyword extraction performances remains under-explored. This study provides a comparative evaluation of three prevalent keyword extraction algorithms that vary in complexity: TF-IDF, KeyBERT, and Llama 2. To evaluate their effectiveness, a mixed-methods approach is employed, combining quantitative benchmarking with qualitative assessments from 552 participants through three survey-based experiments. Findings indicate a slight user preference for KeyBERT, which offers a favourable balance between performance and computational efficiency compared to the other two algorithms. Despite a strong overall preference for gold-standard keywords, differences between the algorithmic outputs are not statistically significant, highlighting a long-overlooked gap between traditional precision-focused metrics and user-perceived algorithm efficiency. The study highlights the importance of user-centred evaluation methodologies and proposes analytical tools to support their implementation.
UniBriVL: Robust Universal Representation and Generation of Audio Driven Diffusion Models
Jul 29, 2023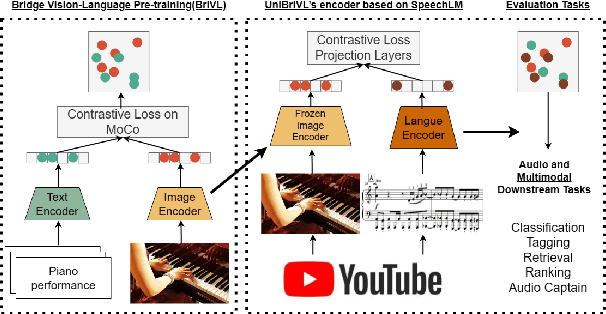



Multimodal large models have been recognized for their advantages in various performance and downstream tasks. The development of these models is crucial towards achieving general artificial intelligence in the future. In this paper, we propose a novel universal language representation learning method called UniBriVL, which is based on Bridging-Vision-and-Language (BriVL). Universal BriVL embeds audio, image, and text into a shared space, enabling the realization of various multimodal applications. Our approach addresses major challenges in robust language (both text and audio) representation learning and effectively captures the correlation between audio and image. Additionally, we demonstrate the qualitative evaluation of the generated images from UniBriVL, which serves to highlight the potential of our approach in creating images from audio. Overall, our experimental results demonstrate the efficacy of UniBriVL in downstream tasks and its ability to choose appropriate images from audio. The proposed approach has the potential for various applications such as speech recognition, music signal processing, and captioning systems.