 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$Drug: Bridging Protein Sequence and 3D Structure in Contrastive Representation Learning for Virtual Screening
Nov 10, 2025Virtual screening (VS) is an essential task in drug discovery, focusing on the identification of small-molecule ligands that bind to specific protein pockets. Existing deep learning methods, from early regression models to recent contrastive learning approaches, primarily rely on structural data while overlooking protein sequences, which are more accessible and can enhance generalizability. However, directly integrating protein sequences poses challenges due to the redundancy and noise in large-scale protein-ligand datasets. To address these limitations, we propose \textbf{S$^2$Drug}, a two-stage framework that explicitly incorporates protein \textbf{S}equence information and 3D \textbf{S}tructure context in protein-ligand contrastive representation learning. In the first stage, we perform protein sequence pretraining on ChemBL using an ESM2-based backbone, combined with a tailored data sampling strategy to reduce redundancy and noise on both protein and ligand sides. In the second stage, we fine-tune on PDBBind by fusing sequence and structure information through a residue-level gating module, while introducing an auxiliary binding site prediction task. This auxiliary task guides the model to accurately localize binding residues within the protein sequence and capture their 3D spatial arrangement, thereby refining protein-ligand matching. Across multiple benchmarks, S$^2$Drug consistently improves virtual screening performance and achieves strong results on binding site prediction, demonstrating the value of bridging sequence and structure in contrastive learning.
Coder as Editor: Code-driven Interpretable Molecular Optimization
Oct 16, 2025Molecular optimization is a central task in drug discovery that requires precise structural reasoning and domain knowledge. While large language models (LLMs) have shown promise in generating high-level editing intentions in natural language, they often struggle to faithfully execute these modifications-particularly when operating on non-intuitive representations like SMILES. We introduce MECo, a framework that bridges reasoning and execution by translating editing actions into executable code. MECo reformulates molecular optimization for LLMs as a cascaded framework: generating human-interpretable editing intentions from a molecule and property goal, followed by translating those intentions into executable structural edits via code generation. Our approach achieves over 98% accuracy in reproducing held-out realistic edits derived from chemical reactions and target-specific compound pairs. On downstream optimization benchmarks spanning physicochemical properties and target activities, MECo substantially improves consistency by 38-86 percentage points to 90%+ and achieves higher success rates over SMILES-based baselines while preserving structural similarity. By aligning intention with execution, MECo enables consistent, controllable and interpretable molecular design, laying the foundation for high-fidelity feedback loops and collaborative human-AI workflows in drug discovery.
AANet: Virtual Screening under Structural Uncertainty via Alignment and Aggregation
Jun 06, 2025Virtual screening (VS) is a critical component of modern drug discovery, yet most existing methods--whether physics-based or deep learning-based--are developed around holo protein structures with known ligand-bound pockets. Consequently, their performance degrades significantly on apo or predicted structures such as those from AlphaFold2, which are more representative of real-world early-stage drug discovery, where pocket information is often missing. In this paper, we introduce an alignment-and-aggregation framework to enable accurate virtual screening under structural uncertainty. Our method comprises two core components: (1) a tri-modal contrastive learning module that aligns representations of the ligand, the holo pocket, and cavities detected from structures, thereby enhancing robustness to pocket localization error; and (2) a cross-attention based adapter for dynamically aggregating candidate binding sites, enabling the model to learn from activity data even without precise pocket annotations. We evaluated our method on a newly curated benchmark of apo structures, where it significantly outperforms state-of-the-art methods in blind apo setting, improving the early enrichment factor (EF1%) from 11.75 to 37.19. Notably, it also maintains strong performance on holo structures. These results demonstrate the promise of our approach in advancing first-in-class drug discovery, particularly in scenarios lacking experimentally resolved protein-ligand complexes.
PharmAgents: Building a Virtual Pharma with Large Language Model Agents
Mar 31, 2025The discovery of novel small molecule drugs remains a critical scientific challenge with far-reaching implications for treating diseases and advancing human health. Traditional drug development--especially for small molecule therapeutics--is a highly complex, resource-intensive, and time-consuming process that requires multidisciplinary collaboration. Recent breakthroughs in artificial intelligence (AI), particularly the rise of large language models (LLMs), present a transformative opportunity to streamline and accelerate this process. In this paper, we introduce PharmAgents, a virtual pharmaceutical ecosystem driven by LLM-based multi-agent collaboration. PharmAgents simulates the full drug discovery workflow--from target discovery to preclinical evaluation--by integrating explainable, LLM-driven agents equipped with specialized machine learning models and computational tools. Through structured knowledge exchange and automated optimization, PharmAgents identifies potential therapeutic targets, discovers promising lead compounds, enhances binding affinity and key molecular properties, and performs in silico analyses of toxicity and synthetic feasibility. Additionally, the system supports interpretability, agent interaction, and self-evolvement, enabling it to refine future drug designs based on prior experience. By showcasing the potential of LLM-powered multi-agent systems in drug discovery, this work establishes a new paradigm for autonomous, explainable, and scalable pharmaceutical research, with future extensions toward comprehensive drug lifecycle management.
From Theory to Therapy: Reframing SBDD Model Evaluation via Practical Metrics
Jun 13, 2024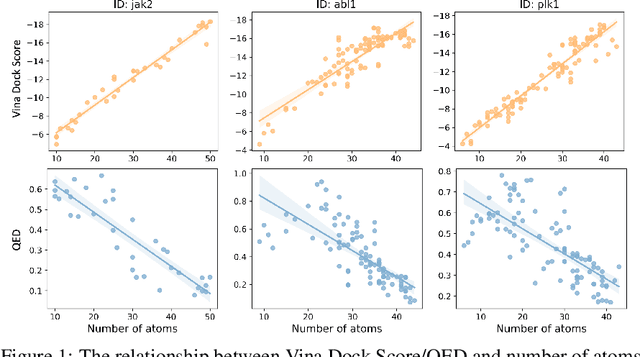
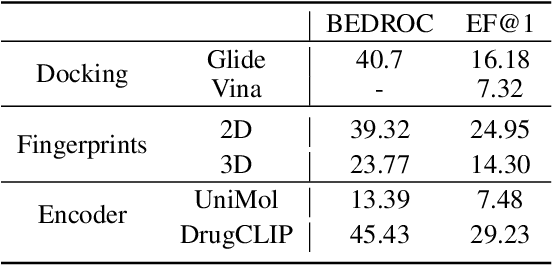
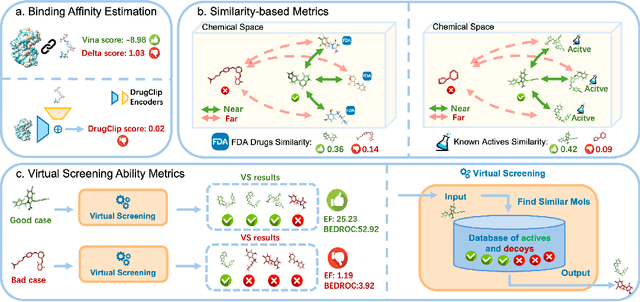
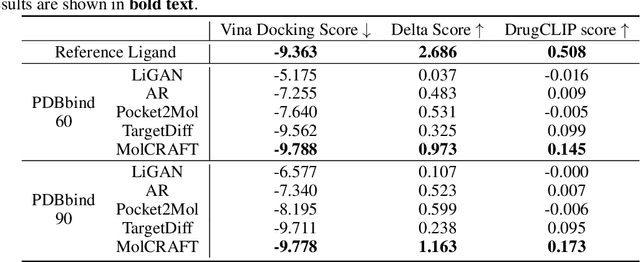
Recent advancements in structure-based drug design (SBDD) have significantly enhanced the efficiency and precision of drug discovery by generating molecules tailored to bind specific protein pockets. Despite these technological strides, their practical application in real-world drug development remains challenging due to the complexities of synthesizing and testing these molecules. The reliability of the Vina docking score, the current standard for assessing binding abilities, is increasingly questioned due to its susceptibility to overfitting. To address these limitations, we propose a comprehensive evaluation framework that includes assessing the similarity of generated molecules to known active compounds, introducing a virtual screening-based metric for practical deployment capabilities, and re-evaluating binding affinity more rigorously. Our experiments reveal that while current SBDD models achieve high Vina scores, they fall short in practical usability metrics, highlighting a significant gap between theoretical predictions and real-world applicability. Our proposed metrics and dataset aim to bridge this gap, enhancing the practical applicability of future SBDD models and aligning them more closely with the needs of pharmaceutical research and development.
SIU: A Million-Scale Structural Small Molecule-Protein Interaction Dataset for Unbiased Bioactivity Prediction
Jun 13, 2024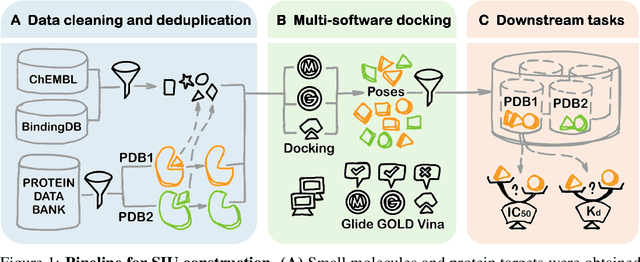

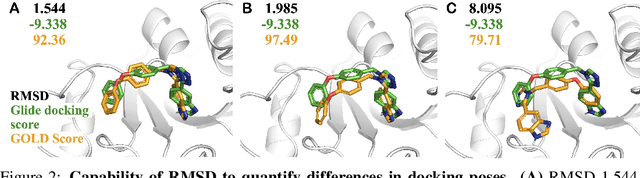
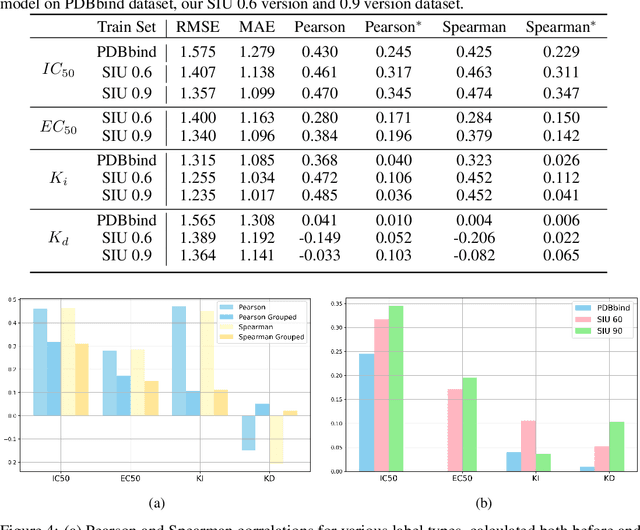
Small molecules play a pivotal role in modern medicine, and scrutinizing their interactions with protein targets is essential for the discovery and development of novel, life-saving therapeutics. The term "bioactivity" encompasses various biological effects resulting from these interactions, including both binding and functional responses. The magnitude of bioactivity dictates the therapeutic or toxic pharmacological outcomes of small molecules, rendering accurate bioactivity prediction crucial for the development of safe and effective drugs. However, existing structural datasets of small molecule-protein interactions are often limited in scale and lack systematically organized bioactivity labels, thereby impeding our understanding of these interactions and precise bioactivity prediction. In this study, we introduce a comprehensive dataset of small molecule-protein interactions, consisting of over a million binding structures, each annotated with real biological activity labels. This dataset is designed to facilitate unbiased bioactivity prediction. We evaluated several classical models on this dataset, and the results demonstrate that the task of unbiased bioactivity prediction is challenging yet essential.
Multi-level Interaction Modeling for Protein Mutational Effect Prediction
May 28, 2024



Protein-protein interactions are central mediators in many biological processes. Accurately predicting the effects of mutations on interactions is crucial for guiding the modulation of these interactions, thereby playing a significant role in therapeutic development and drug discovery. Mutations generally affect interactions hierarchically across three levels: mutated residues exhibit different sidechain conformations, which lead to changes in the backbone conformation, eventually affecting the binding affinity between proteins. However, existing methods typically focus only on sidechain-level interaction modeling, resulting in suboptimal predictions. In this work, we propose a self-supervised multi-level pre-training framework, ProMIM, to fully capture all three levels of interactions with well-designed pretraining objectives. Experiments show ProMIM outperforms all the baselines on the standard benchmark, especially on mutations where significant changes in backbone conformations may occur. In addition, leading results from zero-shot evaluations for SARS-CoV-2 mutational effect prediction and antibody optimization underscore the potential of ProMIM as a powerful next-generation tool for developing novel therapeutic approaches and new drugs.
Delta Score: Improving the Binding Assessment of Structure-Based Drug Design Methods
Nov 01, 2023Structure-based drug design (SBDD) stands at the forefront of drug discovery, emphasizing the creation of molecules that target specific binding pockets. Recent advances in this area have witnessed the adoption of deep generative models and geometric deep learning techniques, modeling SBDD as a conditional generation task where the target structure serves as context. Historically, evaluation of these models centered on docking scores, which quantitatively depict the predicted binding affinity between a molecule and its target pocket. Though state-of-the-art models purport that a majority of their generated ligands exceed the docking score of ground truth ligands in test sets, it begs the question: Do these scores align with real-world biological needs? In this paper, we introduce the delta score, a novel evaluation metric grounded in tangible pharmaceutical requisites. Our experiments reveal that molecules produced by current deep generative models significantly lag behind ground truth reference ligands when assessed with the delta score. This novel metric not only complements existing benchmarks but also provides a pivotal direction for subsequent research in the domain.
Self-supervised Pocket Pretraining via Protein Fragment-Surroundings Alignment
Oct 11, 2023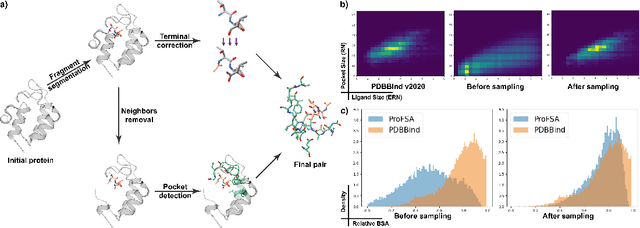

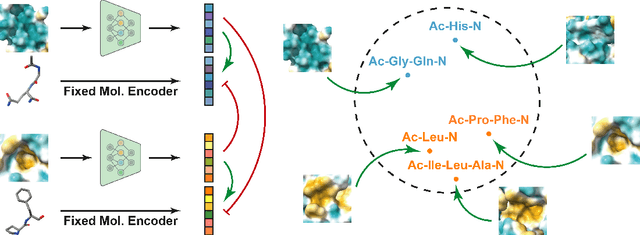

Pocket representations play a vital role in various biomedical applications, such as druggability estimation, ligand affinity prediction, and de novo drug design. While existing geometric features and pretrained representations have demonstrated promising results, they usually treat pockets independent of ligands, neglecting the fundamental interactions between them. However, the limited pocket-ligand complex structures available in the PDB database (less than 100 thousand non-redundant pairs) hampers large-scale pretraining endeavors for interaction modeling. To address this constraint, we propose a novel pocket pretraining approach that leverages knowledge from high-resolution atomic protein structures, assisted by highly effective pretrained small molecule representations. By segmenting protein structures into drug-like fragments and their corresponding pockets, we obtain a reasonable simulation of ligand-receptor interactions, resulting in the generation of over 5 million complexes. Subsequently, the pocket encoder is trained in a contrastive manner to align with the representation of pseudo-ligand furnished by some pretrained small molecule encoders. Our method, named ProFSA, achieves state-of-the-art performance across various tasks, including pocket druggability prediction, pocket matching, and ligand binding affinity prediction. Notably, ProFSA surpasses other pretraining methods by a substantial margin. Moreover, our work opens up a new avenue for mitigating the scarcity of protein-ligand complex data through the utilization of high-quality and diverse protein structure databases.
DrugCLIP: Contrastive Protein-Molecule Representation Learning for Virtual Screening
Oct 10, 2023Virtual screening, which identifies potential drugs from vast compound databases to bind with a particular protein pocket, is a critical step in AI-assisted drug discovery. Traditional docking methods are highly time-consuming, and can only work with a restricted search library in real-life applications. Recent supervised learning approaches using scoring functions for binding-affinity prediction, although promising, have not yet surpassed docking methods due to their strong dependency on limited data with reliable binding-affinity labels. In this paper, we propose a novel contrastive learning framework, DrugCLIP, by reformulating virtual screening as a dense retrieval task and employing contrastive learning to align representations of binding protein pockets and molecules from a large quantity of pairwise data without explicit binding-affinity scores. We also introduce a biological-knowledge inspired data augmentation strategy to learn better protein-molecule representations. Extensive experiments show that DrugCLIP significantly outperforms traditional docking and supervised learning methods on diverse virtual screening benchmarks with highly reduced computation time, especially in zero-shot setting.