 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBriVL: Robust Universal Representation and Generation of Audio Driven Diffusion Models
Jul 29, 2023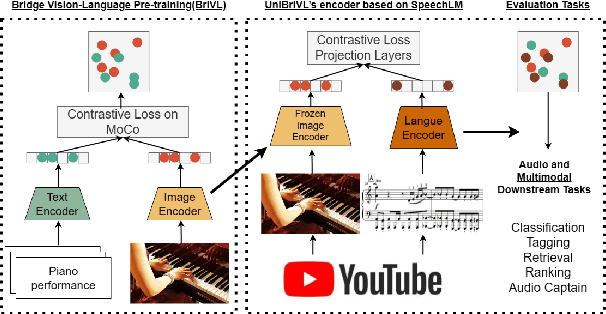



Multimodal large models have been recognized for their advantages in various performance and downstream tasks. The development of these models is crucial towards achieving general artificial intelligence in the future. In this paper, we propose a novel universal language representation learning method called UniBriVL, which is based on Bridging-Vision-and-Language (BriVL). Universal BriVL embeds audio, image, and text into a shared space, enabling the realization of various multimodal applications. Our approach addresses major challenges in robust language (both text and audio) representation learning and effectively captures the correlation between audio and image. Additionally, we demonstrate the qualitative evaluation of the generated images from UniBriVL, which serves to highlight the potential of our approach in creating images from audio. Overall, our experimental results demonstrate the efficacy of UniBriVL in downstream tasks and its ability to choose appropriate images from audio. The proposed approach has the potential for various applications such as speech recognition, music signal processing, and captioning systems.
New Audio Representations Image Gan Generation from BriVL
Mar 08, 2023Recently, researchers have gradually realized that in some cases, the self-supervised pre-training on large-scale Internet data is better than that of high-quality/manually labeled data sets, and multimodal/large models are better than single or bimodal/small models. In this paper, we propose a robust audio representation learning method WavBriVL based on Bridging-Vision-and-Language (BriVL). WavBriVL projects audio, image and text into a shared embedded space, so that multi-modal applications can be realized. We demonstrate the qualitative evaluation of the image generated from WavBriVL as a shared embedded space, with the main purposes of this paper: (1) Learning the correlation between audio and image; (2) Explore a new way of image generation, that is, use audio to generate pictures. Experimental results show that this method can effectively generate appropriate images from audio.