 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Has AI Come in Liver Fibrosis Staging? A Large-Scale Real-World Dataset and Benchmark
May 25, 2026Despite years of methodological progress, how far AI has come in liver fibrosis staging has never been systematically evaluated under the heterogeneous, multi-center conditions that define clinical practice. To address this gap, we introduce LiFS, a large-scale dataset and benchmark derived from the MICCAI 2025 CARE-Liver challenge, comprising 610 patients across multiple centers and scanners with multi-sequence MRI. To the best of our knowledge, LiFS is the first benchmark providing complete gadoxetic acid-enhanced sequences with histopathology-confirmed annotations from diverse real-world scanners. Through systematic evaluation of 9 independently developed methods selected from 96 registered teams against in-cohort radiologist reference results, our findings address how far current AI has progressed toward clinical-level liver fibrosis staging from three complementary perspectives. First, against radiologists, the best AI methods were broadly comparable to the senior radiologist and significantly exceeded the junior radiologist in selected settings, while median AI performance generally approached junior-radiologist levels. Second, from a data perspective, cross-center heterogeneity, label imbalance, and contrast-enhanced sequence variability emerge as the dominant challenges for AI methods. Third, from a technical perspective, methodological design choices, including spatial registration, input dimensionality, multi-modal fusion strategy, and backbone architecture, appear to modulate cross-center robustness, although no single choice alone closes the gap. Overall, LiFS provides a rigorous real-world benchmark for positioning the current state of AI in liver fibrosis staging and for enabling future research on the key challenges that limit clinically reliable deployment.
Toeplitz Unlabeled Sensing
Feb 18, 2025Unlabeled sensing is the problem of recovering an element of a vector subspace of R^n, from its image under an unknown permutation of the coordinates and knowledge of the subspace. Here we study this problem for the special class of subspaces that admit a Toeplitz basis.
AER-LLM: Ambiguity-aware Emotion Recognition Leveraging Large Language Models
Sep 26, 2024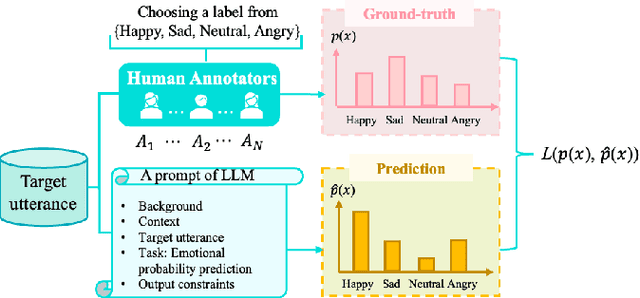
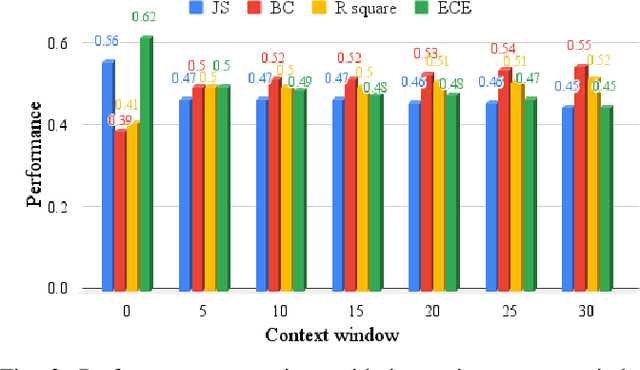
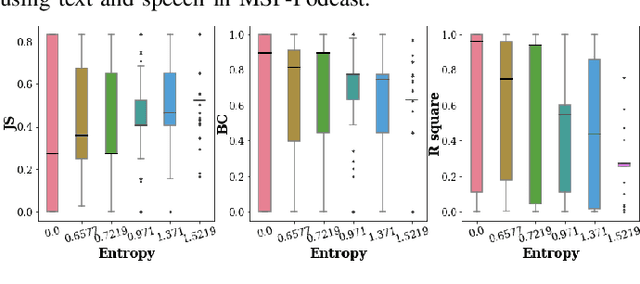
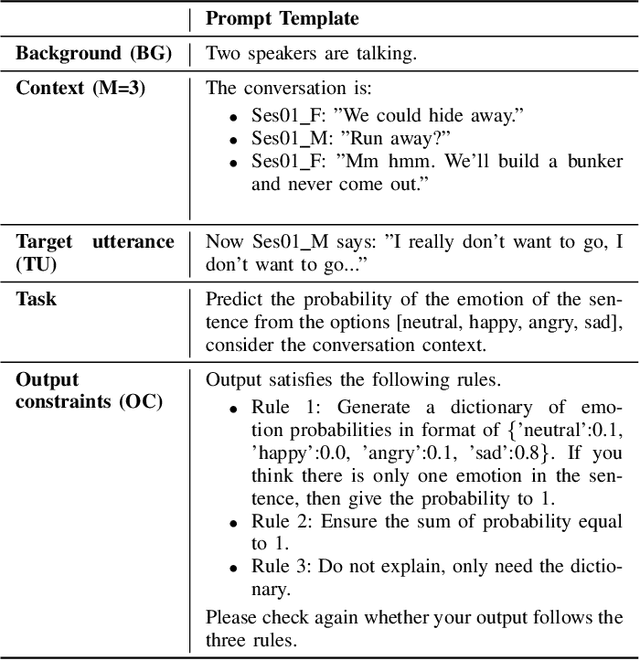
Recent advancements in Large Language Models (LLMs) have demonstrated great success in many Natural Language Processing (NLP) tasks. In addition to their cognitive intelligence, exploring their capabilities in emotional intelligence is also crucial, as it enables more natural and empathetic conversational AI. Recent studies have shown LLMs' capability in recognizing emotions, but they often focus on single emotion labels and overlook the complex and ambiguous nature of human emotions. This study is the first to address this gap by exploring the potential of LLMs in recognizing ambiguous emotions, leveraging their strong generalization capabilities and in-context learning. We design zero-shot and few-shot prompting and incorporate past dialogue as context information for ambiguous emotion recognition. Experiments conducted using three datasets indicate significant potential for LLMs in recognizing ambiguous emotions, and highlight the substantial benefits of including context information. Furthermore, our findings indicate that LLMs demonstrate a high degree of effectiveness in recognizing less ambiguous emotions and exhibit potential for identifying more ambiguous emotions, paralleling human perceptual capabilities.
Pre-training with Fractional Denoising to Enhance Molecular Property Prediction
Jul 14, 2024Deep learning methods have been considered promising for accelerating molecular screening in drug discovery and material design. Due to the limited availability of labelled data, various self-supervised molecular pre-training methods have been presented. While many existing methods utilize common pre-training tasks in computer vision (CV) and natural language processing (NLP), they often overlook the fundamental physical principles governing molecules. In contrast, applying denoising in pre-training can be interpreted as an equivalent force learning, but the limited noise distribution introduces bias into the molecular distribution. To address this issue, we introduce a molecular pre-training framework called fractional denoising (Frad), which decouples noise design from the constraints imposed by force learning equivalence. In this way, the noise becomes customizable, allowing for incorporating chemical priors to significantly improve molecular distribution modeling. Experiments demonstrate that our framework consistently outperforms existing methods, establishing state-of-the-art results across force prediction, quantum chemical properties, and binding affinity tasks. The refined noise design enhances force accuracy and sampling coverage, which contribute to the creation of physically consistent molecular representations, ultimately leading to superior predictive performance.
Multi-level Interaction Modeling for Protein Mutational Effect Prediction
May 28, 2024



Protein-protein interactions are central mediators in many biological processes. Accurately predicting the effects of mutations on interactions is crucial for guiding the modulation of these interactions, thereby playing a significant role in therapeutic development and drug discovery. Mutations generally affect interactions hierarchically across three levels: mutated residues exhibit different sidechain conformations, which lead to changes in the backbone conformation, eventually affecting the binding affinity between proteins. However, existing methods typically focus only on sidechain-level interaction modeling, resulting in suboptimal predictions. In this work, we propose a self-supervised multi-level pre-training framework, ProMIM, to fully capture all three levels of interactions with well-designed pretraining objectives. Experiments show ProMIM outperforms all the baselines on the standard benchmark, especially on mutations where significant changes in backbone conformations may occur. In addition, leading results from zero-shot evaluations for SARS-CoV-2 mutational effect prediction and antibody optimization underscore the potential of ProMIM as a powerful next-generation tool for developing novel therapeutic approaches and new drugs.
Visual Transformation Telling
May 03, 2023


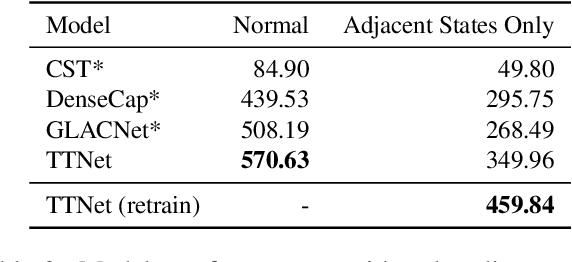
In this paper, we propose a new visual reasoning task, called Visual Transformation Telling (VTT). This task requires a machine to describe the transformation that occurred between every two adjacent states (i.e. images) in a series. Unlike most existing visual reasoning tasks that focus on state reasoning, VTT emphasizes transformation reasoning. We collected 13,547 samples from two instructional video datasets, CrossTask and COIN, and extracted desired states and transformation descriptions to create a suitable VTT benchmark dataset. Humans can naturally reason from superficial states differences (e.g. ground wetness) to transformations descriptions (e.g. raining) according to their life experience but how to model this process to bridge this semantic gap is challenging. We designed TTNet on top of existing visual storytelling models by enhancing the model's state-difference sensitivity and transformation-context awareness. TTNet significantly outperforms other baseline models adapted from similar tasks, such as visual storytelling and dense video captioning, demonstrating the effectiveness of our modeling on transformations. Through comprehensive diagnostic analyses, we found TTNet has strong context utilization abilities, but even with some state-of-the-art techniques such as CLIP, there remain challenges in generalization that need to be further explored.
Visual Reasoning: from State to Transformation
May 02, 2023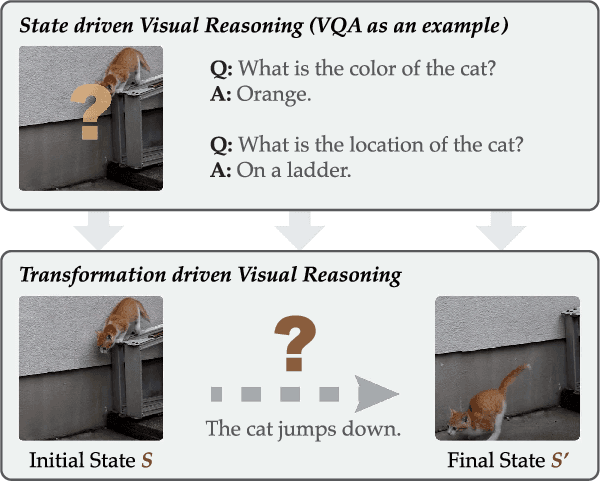
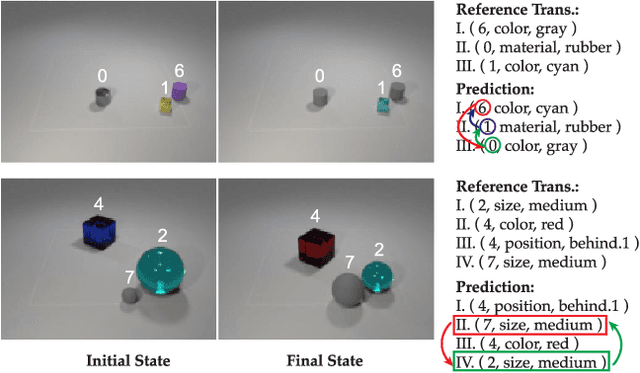
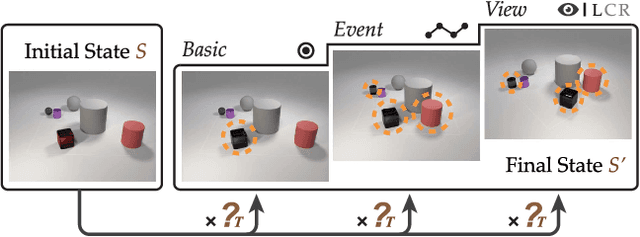

Most existing visual reasoning tasks, such as CLEVR in VQA, ignore an important factor, i.e.~transformation. They are solely defined to test how well machines understand concepts and relations within static settings, like one image. Such \textbf{state driven} visual reasoning has limitations in reflecting the ability to infer the dynamics between different states, which has shown to be equally important for human cognition in Piaget's theory. To tackle this problem, we propose a novel \textbf{transformation driven} visual reasoning (TVR) task. Given both the initial and final states, the target becomes to infer the corresponding intermediate transformation. Following this definition, a new synthetic dataset namely TRANCE is first constructed on the basis of CLEVR, including three levels of settings, i.e.~Basic (single-step transformation), Event (multi-step transformation), and View (multi-step transformation with variant views). Next, we build another real dataset called TRANCO based on COIN, to cover the loss of transformation diversity on TRANCE. Inspired by human reasoning, we propose a three-staged reasoning framework called TranNet, including observing, analyzing, and concluding, to test how recent advanced techniques perform on TVR. Experimental results show that the state-of-the-art visual reasoning models perform well on Basic, but are still far from human-level intelligence on Event, View, and TRANCO. We believe the proposed new paradigm will boost the development of machine visual reasoning. More advanced methods and new problems need to be investigated in this direction. The resource of TVR is available at \url{https://hongxin2019.github.io/TVR/}.
S$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022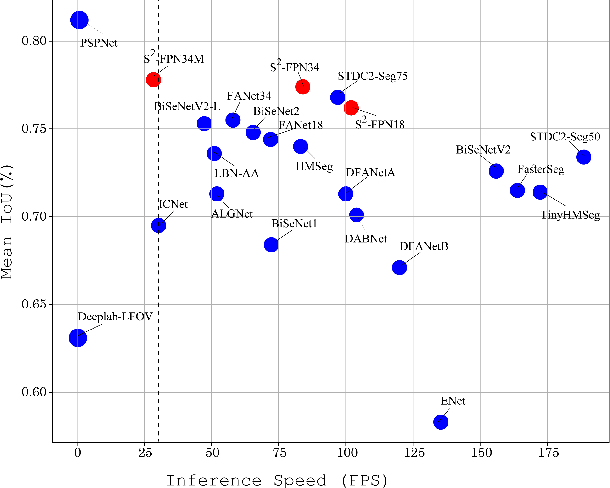
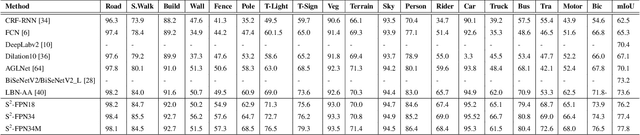
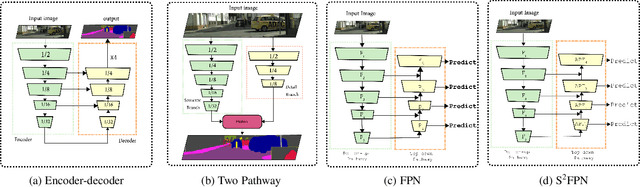
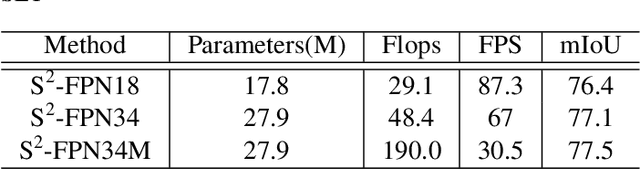
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
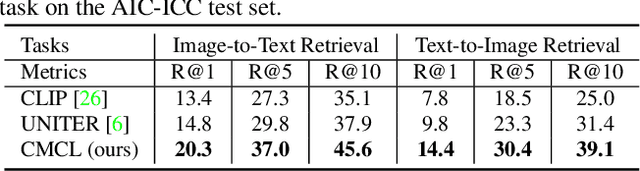
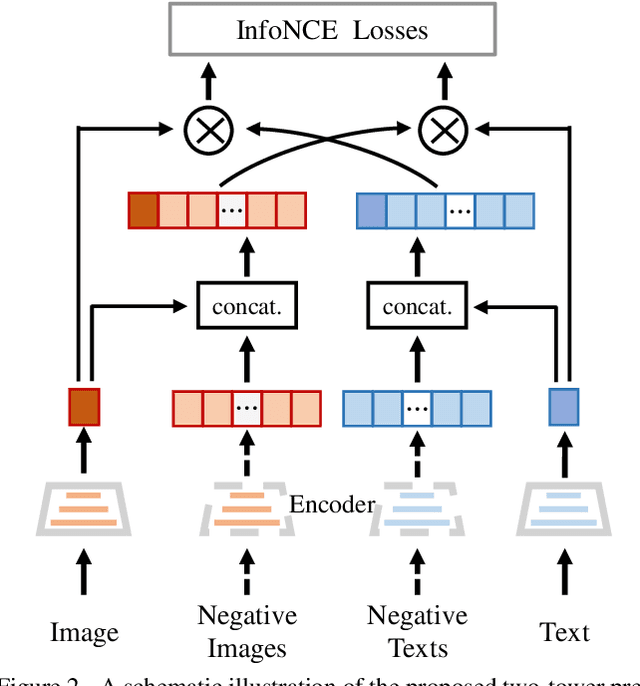
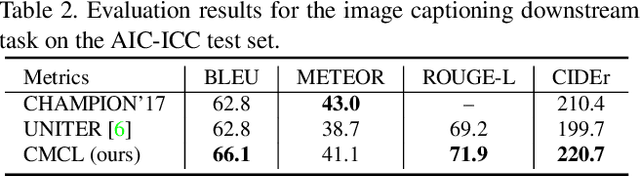
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
Transformation Driven Visual Reasoning
Nov 26, 2020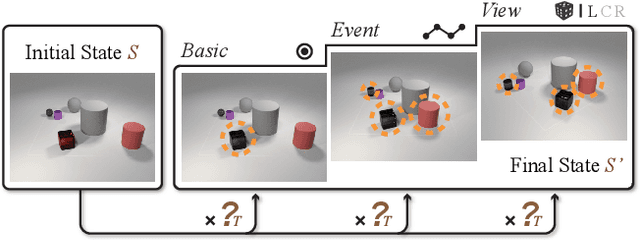
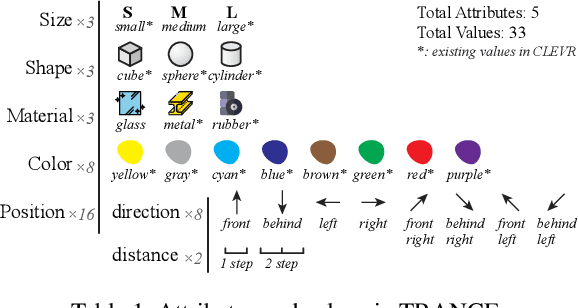
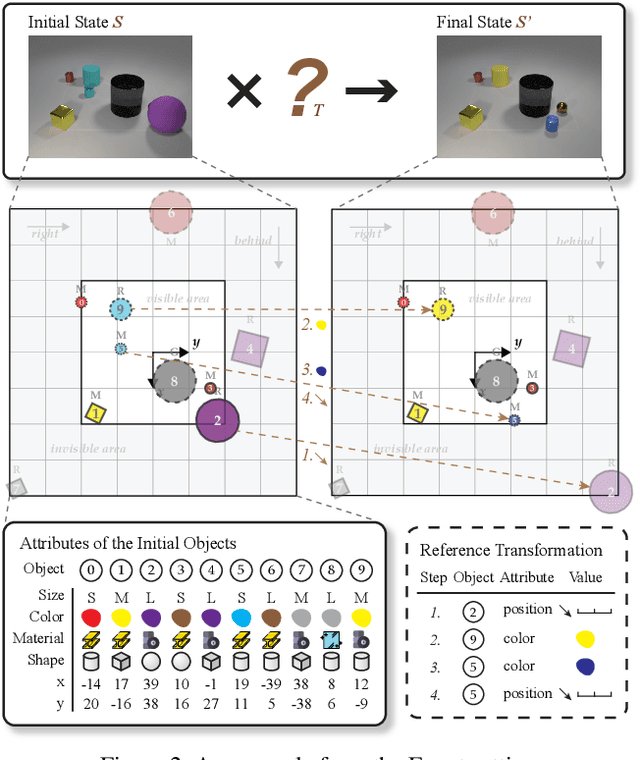
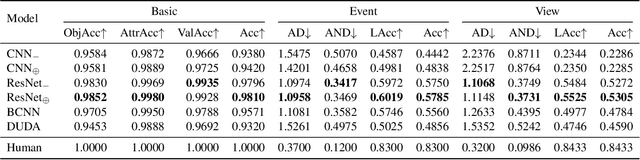
This paper defines a new visual reasoning paradigm by introducing an important factor, i.e., transformation. The motivation comes from the fact that most existing visual reasoning tasks, such as CLEVR in VQA, are solely defined to test how well the machine understands the concepts and relations within static settings, like one image. We argue that this kind of state driven visual reasoning approach has limitations in reflecting whether the machine has the ability to infer the dynamics between different states, which has been shown as important as state-level reasoning for human cognition in Piaget's theory. To tackle this problem, we propose a novel transformation driven visual reasoning task. Given both the initial and final states, the target is to infer the corresponding single-step or multi-step transformation, represented as a triplet (object, attribute, value) or a sequence of triplets, respectively. Following this definition, a new dataset namely TRANCE is constructed on the basis of CLEVR, including three levels of settings, i.e., Basic (single-step transformation), Event (multi-step transformation), and View (multi-step transformation with variant views). Experimental results show that the state-of-the-art visual reasoning models perform well on Basic, but are still far from human-level intelligence on Event and View. We believe the proposed new paradigm will boost the development of machine visual reasoning. More advanced methods and real data need to be investigated in this direction. Code is available at: https://github.com/hughplay/TVR.