 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterference Mitigation in STAR-RIS-Aided Multi-User Networks with Statistical CSI
Jun 15, 2025In this paper, we investigate real-time interference mitigation in multiuser wireless networks assisted by simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs). Unlike conventional methods that rely on instantaneous channel state information (CSI), we consider a practical scenario where only statistical CSI is available, and the STAR-RIS phase shifts are impaired by random phase errors modeled via the Von Mises distribution. To tackle the resulting nonconvex optimization problem induced by unit-modulus constraints and stochastic interference, we derive a closed-form approximation of the effective channel matrix using statistical expectations. We then reformulate the interference minimization problem as an unconstrained optimization over a Riemannian manifold and propose a conjugate gradient algorithm tailored to the complex circle manifold. The proposed solution enables efficient real-time computation of optimal phase shifts while accounting for hardware imperfections and limited CSI. Simulation results confirm that our method significantly suppresses inter-user interference and achieves superior SINR performance and convergence speed compared to conventional baselines.
Adaptive Soft Actor-Critic Framework for RIS-Assisted and UAV-Aided Communication
Nov 16, 2024



In this work, we explore UAV-assisted reconfigurable intelligent surface (RIS) technology to enhance downlink communications in wireless networks. By integrating RIS on both UAVs and ground infrastructure, we aim to boost network coverage, fairness, and resilience against challenges such as UAV jitter. To maximize the minimum achievable user rate, we formulate a joint optimization problem involving beamforming, phase shifts, and UAV trajectory. To address this problem, we propose an adaptive soft actor-critic (ASAC) framework. In this approach, agents are built using adaptive sparse transformers with attentive feature refinement (ASTAFER), enabling dynamic feature processing that adapts to real-time network conditions. The ASAC model learns optimal solutions to the coupled subproblems in real time, delivering an end-to-end solution without relying on iterative or relaxation-based methods. Simulation results demonstrate that our ASAC-based approach achieves better performance compared to the conventional SAC. This makes it a robust, adaptable solution for real-time, fair, and efficient downlink communication in UAV-RIS networks.
Real-Time and Security-Aware Precoding in RIS-Empowered Multi-User Wireless Networks
Dec 30, 2023In this letter, we propose a deep-unfolding-based framework (DUNet) to maximize the secrecy rate in reconfigurable intelligent surface (RIS) empowered multi-user wireless networks. To tailor DUNet, first we relax the problem, decouple it into beamforming and phase shift subproblems, and propose an alternative optimization (AO) based solution for the relaxed problem. Second, we apply Karush-Kuhn-Tucker (KKT) conditions to obtain a closed-form solutions for the beamforming and the phase shift. Using deep-unfolding mechanism, we transform the closed-form solutions into a deep learning model (i.e., DUNet) that achieves a comparable performance to that of AO in terms of accuracy and about 25.6 times faster.
P2AT: Pyramid Pooling Axial Transformer for Real-time Semantic Segmentation
Oct 23, 2023



Recently, Transformer-based models have achieved promising results in various vision tasks, due to their ability to model long-range dependencies. However, transformers are computationally expensive, which limits their applications in real-time tasks such as autonomous driving. In addition, an efficient local and global feature selection and fusion are vital for accurate dense prediction, especially driving scene understanding tasks. In this paper, we propose a real-time semantic segmentation architecture named Pyramid Pooling Axial Transformer (P2AT). The proposed P2AT takes a coarse feature from the CNN encoder to produce scale-aware contextual features, which are then combined with the multi-level feature aggregation scheme to produce enhanced contextual features. Specifically, we introduce a pyramid pooling axial transformer to capture intricate spatial and channel dependencies, leading to improved performance on semantic segmentation. Then, we design a Bidirectional Fusion module (BiF) to combine semantic information at different levels. Meanwhile, a Global Context Enhancer is introduced to compensate for the inadequacy of concatenating different semantic levels. Finally, a decoder block is proposed to help maintain a larger receptive field. We evaluate P2AT variants on three challenging scene-understanding datasets. In particular, our P2AT variants achieve state-of-art results on the Camvid dataset 80.5%, 81.0%, 81.1% for P2AT-S, P2ATM, and P2AT-L, respectively. Furthermore, our experiment on Cityscapes and Pascal VOC 2012 have demonstrated the efficiency of the proposed architecture, with results showing that P2AT-M, achieves 78.7% on Cityscapes. The source code will be available at
Enhancing Secrecy in UAV RSMA Networks: Deep Unfolding Meets Deep Reinforcement Learning
Sep 30, 2023In this paper, we consider the maximization of the secrecy rate in multiple unmanned aerial vehicles (UAV) rate-splitting multiple access (RSMA) network. A joint beamforming, rate allocation, and UAV trajectory optimization problem is formulated which is nonconvex. Hence, the problem is transformed into a Markov decision problem and a novel multiagent deep reinforcement learning (DRL) framework is designed. The proposed framework (named DUN-DRL) combines deep unfolding to design beamforming and rate allocation, data-driven to design the UAV trajectory, and deep deterministic policy gradient (DDPG) for the learning procedure. The proposed DUN-DRL have shown great performance and outperformed other DRL-based methods in the literature.
S$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022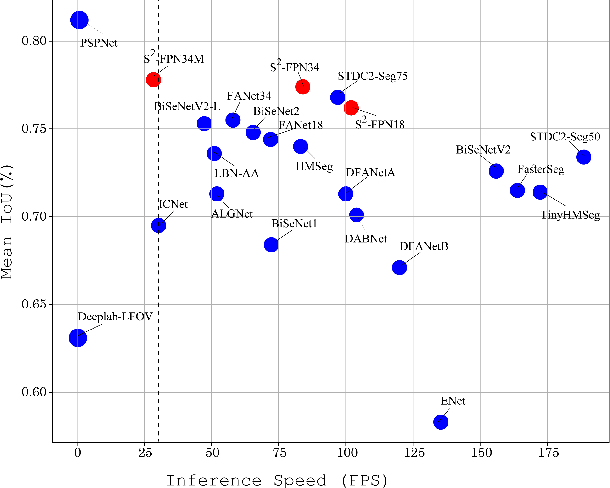
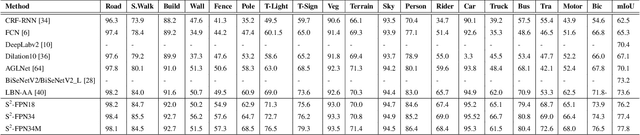
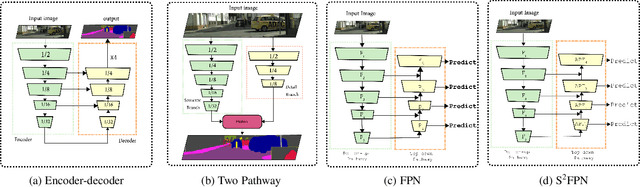
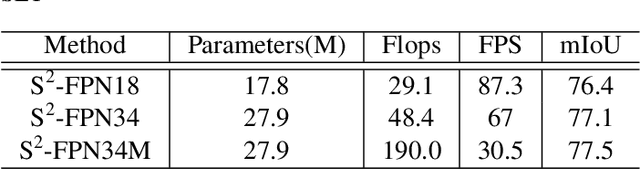
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
SPFNet:Subspace Pyramid Fusion Network for Semantic Segmentation
Apr 04, 2022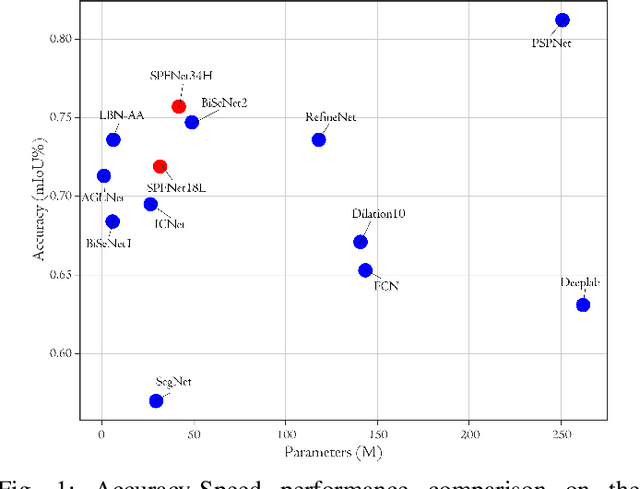

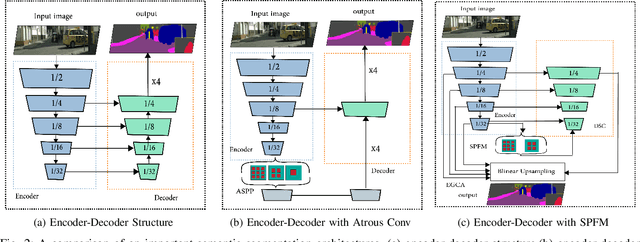
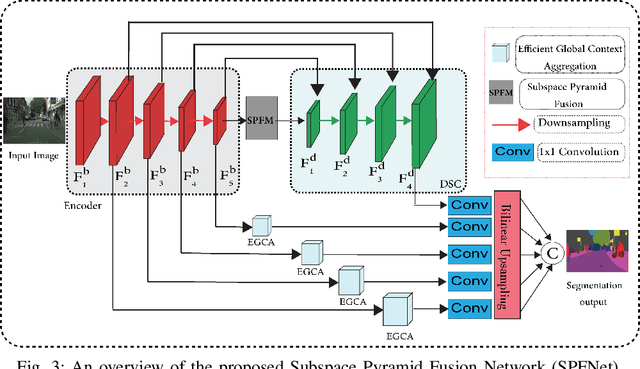
The encoder-decoder structure has significantly improved performance in many vision tasks by fusing low-level and high-level feature maps. However, this approach can hardly extract sufficient context information for pixel-wise segmentation. In addition, extracting similar low-level features at multiple scales could lead to redundant information. To tackle these issues, we propose Subspace Pyramid Fusion Network (SPFNet). Specifically, we combine pyramidal module and context aggregation module to exploit the impact of multi-scale/global context information. At first, we construct a Subspace Pyramid Fusion Module (SPFM) based on Reduced Pyramid Pooling (RPP). Then, we propose the Efficient Global Context Aggregation (EGCA) module to capture discriminative features by fusing multi-level global context features. Finally, we add decoder-based subpixel convolution to retrieve the high-resolution feature maps, which can help select category localization details. SPFM learns separate RPP for each feature subspace to capture multi-scale feature representations, which is more useful for semantic segmentation. EGCA adopts shuffle attention mechanism to enhance communication across different sub-features. Experimental results on two well-known semantic segmentation datasets, including Camvid and Cityscapes, show that our proposed method is competitive with other state-of-the-art methods.