 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022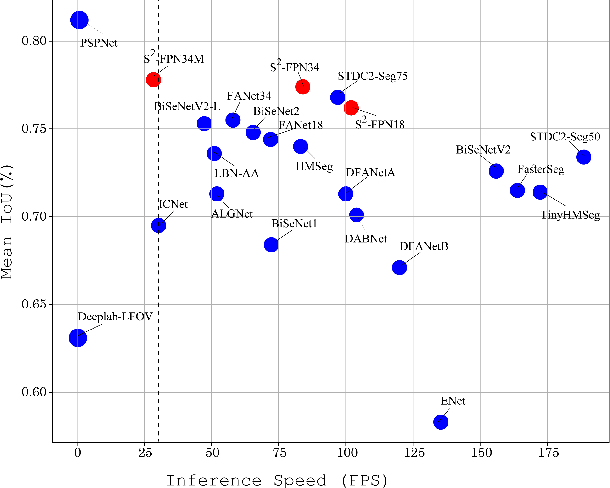
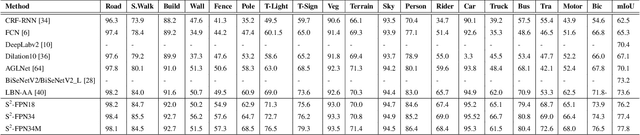
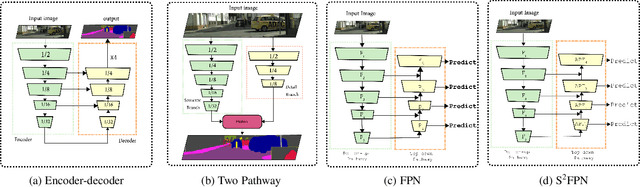
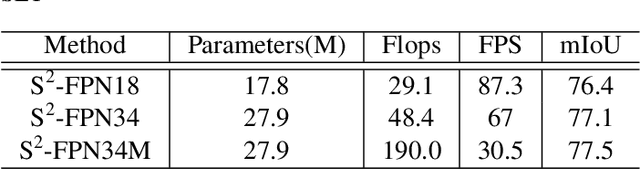
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
SPFNet:Subspace Pyramid Fusion Network for Semantic Segmentation
Apr 04, 2022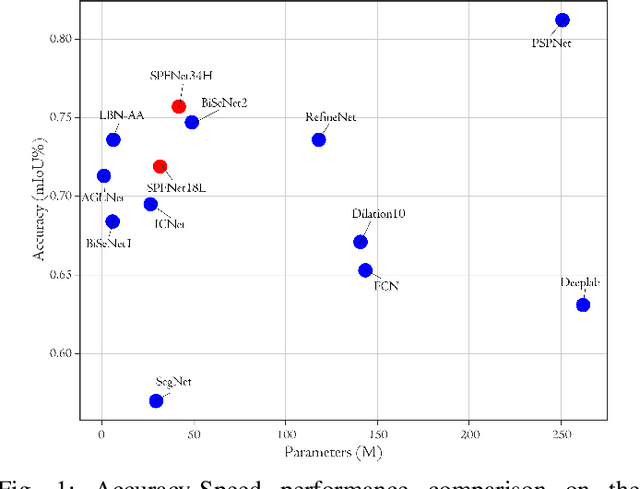

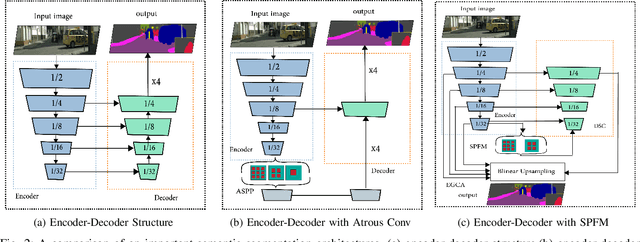
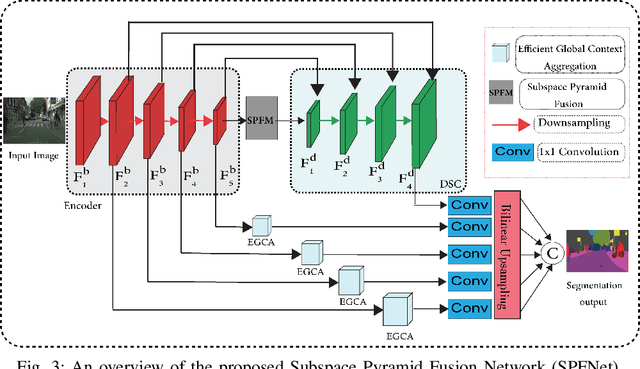
The encoder-decoder structure has significantly improved performance in many vision tasks by fusing low-level and high-level feature maps. However, this approach can hardly extract sufficient context information for pixel-wise segmentation. In addition, extracting similar low-level features at multiple scales could lead to redundant information. To tackle these issues, we propose Subspace Pyramid Fusion Network (SPFNet). Specifically, we combine pyramidal module and context aggregation module to exploit the impact of multi-scale/global context information. At first, we construct a Subspace Pyramid Fusion Module (SPFM) based on Reduced Pyramid Pooling (RPP). Then, we propose the Efficient Global Context Aggregation (EGCA) module to capture discriminative features by fusing multi-level global context features. Finally, we add decoder-based subpixel convolution to retrieve the high-resolution feature maps, which can help select category localization details. SPFM learns separate RPP for each feature subspace to capture multi-scale feature representations, which is more useful for semantic segmentation. EGCA adopts shuffle attention mechanism to enhance communication across different sub-features. Experimental results on two well-known semantic segmentation datasets, including Camvid and Cityscapes, show that our proposed method is competitive with other state-of-the-art methods.