 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Phase Federated Deep Unlearning via Weight-Aware Rollback and Reconstruction
Dec 15, 2025Federated Unlearning (FUL) focuses on client data and computing power to offer a privacy-preserving solution. However, high computational demands, complex incentive mechanisms, and disparities in client-side computing power often lead to long times and higher costs. To address these challenges, many existing methods rely on server-side knowledge distillation that solely removes the updates of the target client, overlooking the privacy embedded in the contributions of other clients, which can lead to privacy leakage. In this work, we introduce DPUL, a novel server-side unlearning method that deeply unlearns all influential weights to prevent privacy pitfalls. Our approach comprises three components: (i) identifying high-weight parameters by filtering client update magnitudes, and rolling them back to ensure deep removal. (ii) leveraging the variational autoencoder (VAE) to reconstruct and eliminate low-weight parameters. (iii) utilizing a projection-based technique to recover the model. Experimental results on four datasets demonstrate that DPUL surpasses state-of-the-art baselines, providing a 1%-5% improvement in accuracy and up to 12x reduction in time cost.
SPG-CDENet: Spatial Prior-Guided Cross Dual Encoder Network for Multi-Organ Segmentation
Oct 30, 2025Multi-organ segmentation is a critical task in computer-aided diagnosis. While recent deep learning methods have achieved remarkable success in image segmentation, huge variations in organ size and shape challenge their effectiveness in multi-organ segmentation. To address these challenges, we propose a Spatial Prior-Guided Cross Dual Encoder Network (SPG-CDENet), a novel two-stage segmentation paradigm designed to improve multi-organ segmentation accuracy. Our SPG-CDENet consists of two key components: a spatial prior network and a cross dual encoder network. The prior network generates coarse localization maps that delineate the approximate ROI, serving as spatial guidance for the dual encoder network. The cross dual encoder network comprises four essential components: a global encoder, a local encoder, a symmetric cross-attention module, and a flow-based decoder. The global encoder captures global semantic features from the entire image, while the local encoder focuses on features from the prior network. To enhance the interaction between the global and local encoders, a symmetric cross-attention module is proposed across all layers of the encoders to fuse and refine features. Furthermore, the flow-based decoder directly propagates high-level semantic features from the final encoder layer to all decoder layers, maximizing feature preservation and utilization. Extensive qualitative and quantitative experiments on two public datasets demonstrate the superior performance of SPG-CDENet compared to existing segmentation methods. Furthermore, ablation studies further validate the effectiveness of the proposed modules in improving segmentation accuracy.
3D UAV Trajectory Planning for IoT Data Collection via Matrix-Based Evolutionary Computation
Oct 08, 2024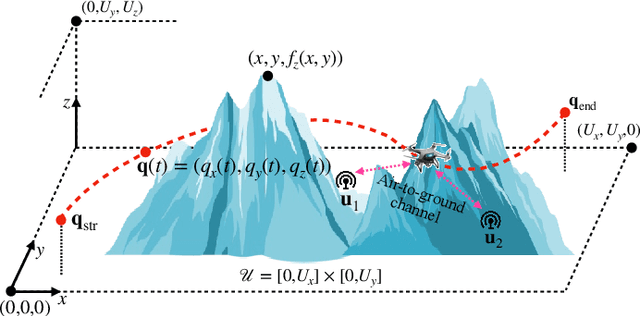
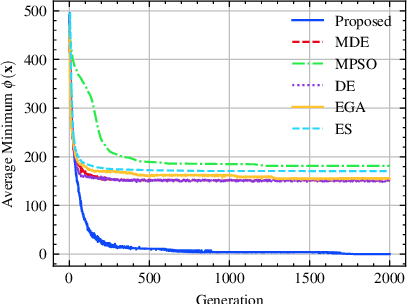
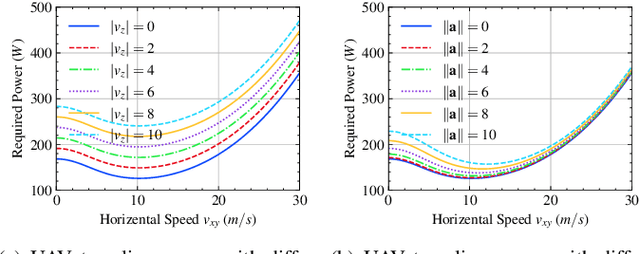
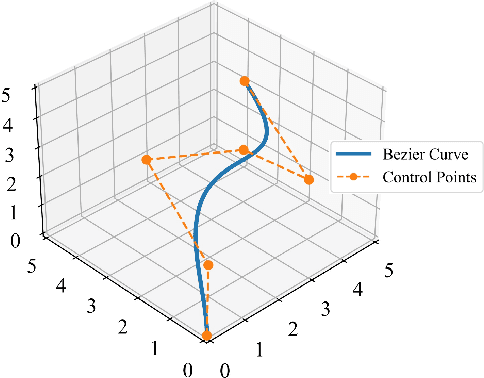
UAVs are increasingly becoming vital tools in various wireless communication applications including internet of things (IoT) and sensor networks, thanks to their rapid and agile non-terrestrial mobility. Despite recent research, planning three-dimensional (3D) UAV trajectories over a continuous temporal-spatial domain remains challenging due to the need to solve computationally intensive optimization problems. In this paper, we study UAV-assisted IoT data collection aimed at minimizing total energy consumption while accounting for the UAV's physical capabilities, the heterogeneous data demands of IoT nodes, and 3D terrain. We propose a matrix-based differential evolution with constraint handling (MDE-CH), a computation-efficient evolutionary algorithm designed to address non-convex constrained optimization problems with several different types of constraints. Numerical evaluations demonstrate that the proposed MDE-CH algorithm provides a continuous 3D temporal-spatial UAV trajectory capable of efficiently minimizing energy consumption under various practical constraints and outperforms the conventional fly-hover-fly model for both two-dimensional (2D) and 3D trajectory planning.
P2AT: Pyramid Pooling Axial Transformer for Real-time Semantic Segmentation
Oct 23, 2023



Recently, Transformer-based models have achieved promising results in various vision tasks, due to their ability to model long-range dependencies. However, transformers are computationally expensive, which limits their applications in real-time tasks such as autonomous driving. In addition, an efficient local and global feature selection and fusion are vital for accurate dense prediction, especially driving scene understanding tasks. In this paper, we propose a real-time semantic segmentation architecture named Pyramid Pooling Axial Transformer (P2AT). The proposed P2AT takes a coarse feature from the CNN encoder to produce scale-aware contextual features, which are then combined with the multi-level feature aggregation scheme to produce enhanced contextual features. Specifically, we introduce a pyramid pooling axial transformer to capture intricate spatial and channel dependencies, leading to improved performance on semantic segmentation. Then, we design a Bidirectional Fusion module (BiF) to combine semantic information at different levels. Meanwhile, a Global Context Enhancer is introduced to compensate for the inadequacy of concatenating different semantic levels. Finally, a decoder block is proposed to help maintain a larger receptive field. We evaluate P2AT variants on three challenging scene-understanding datasets. In particular, our P2AT variants achieve state-of-art results on the Camvid dataset 80.5%, 81.0%, 81.1% for P2AT-S, P2ATM, and P2AT-L, respectively. Furthermore, our experiment on Cityscapes and Pascal VOC 2012 have demonstrated the efficiency of the proposed architecture, with results showing that P2AT-M, achieves 78.7% on Cityscapes. The source code will be available at