 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Transformation Telling
Paper and Code
May 03, 2023


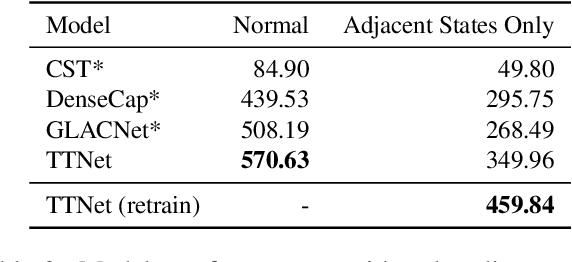
In this paper, we propose a new visual reasoning task, called Visual Transformation Telling (VTT). This task requires a machine to describe the transformation that occurred between every two adjacent states (i.e. images) in a series. Unlike most existing visual reasoning tasks that focus on state reasoning, VTT emphasizes transformation reasoning. We collected 13,547 samples from two instructional video datasets, CrossTask and COIN, and extracted desired states and transformation descriptions to create a suitable VTT benchmark dataset. Humans can naturally reason from superficial states differences (e.g. ground wetness) to transformations descriptions (e.g. raining) according to their life experience but how to model this process to bridge this semantic gap is challenging. We designed TTNet on top of existing visual storytelling models by enhancing the model's state-difference sensitivity and transformation-context awareness. TTNet significantly outperforms other baseline models adapted from similar tasks, such as visual storytelling and dense video captioning, demonstrating the effectiveness of our modeling on transformations. Through comprehensive diagnostic analyses, we found TTNet has strong context utilization abilities, but even with some state-of-the-art techniques such as CLIP, there remain challenges in generalization that need to be further explored.