 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould Audio Front-ends be Adaptive? Comparing Learnable and Adaptive Front-ends
Feb 05, 2025Hand-crafted features, such as Mel-filterbanks, have traditionally been the choice for many audio processing applications. Recently, there has been a growing interest in learnable front-ends that extract representations directly from the raw audio waveform. \textcolor{black}{However, both hand-crafted filterbanks and current learnable front-ends lead to fixed computation graphs at inference time, failing to dynamically adapt to varying acoustic environments, a key feature of human auditory systems.} To this end, we explore the question of whether audio front-ends should be adaptive by comparing the Ada-FE front-end (a recently developed adaptive front-end that employs a neural adaptive feedback controller to dynamically adjust the Q-factors of its spectral decomposition filters) to established learnable front-ends. Specifically, we systematically investigate learnable front-ends and Ada-FE across two commonly used back-end backbones and a wide range of audio benchmarks including speech, sound event, and music. The comprehensive results show that our Ada-FE outperforms advanced learnable front-ends, and more importantly, it exhibits impressive stability or robustness on test samples over various training epochs.
Blind Estimation of Sub-band Acoustic Parameters from Ambisonics Recordings using Spectro-Spatial Covariance Features
Nov 05, 2024Estimating frequency-varying acoustic parameters is essential for enhancing immersive perception in realistic spatial audio creation. In this paper, we propose a unified framework that blindly estimates reverberation time (T60), direct-to-reverberant ratio (DRR), and clarity (C50) across 10 frequency bands using first-order Ambisonics (FOA) speech recordings as inputs. The proposed framework utilizes a novel feature named Spectro-Spatial Covariance Vector (SSCV), efficiently representing temporal, spectral as well as spatial information of the FOA signal. Our models significantly outperform existing single-channel methods with only spectral information, reducing estimation errors by more than half for all three acoustic parameters. Additionally, we introduce FOA-Conv3D, a novel back-end network for effectively utilising the SSCV feature with a 3D convolutional encoder. FOA-Conv3D outperforms the convolutional neural network (CNN) and recurrent convolutional neural network (CRNN) backends, achieving lower estimation errors and accounting for a higher proportion of variance (PoV) for all 3 acoustic parameters.
AER-LLM: Ambiguity-aware Emotion Recognition Leveraging Large Language Models
Sep 26, 2024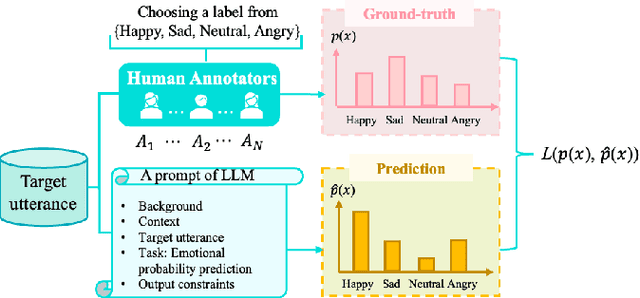
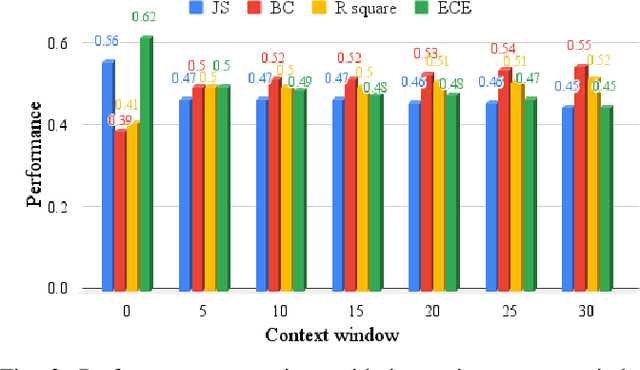
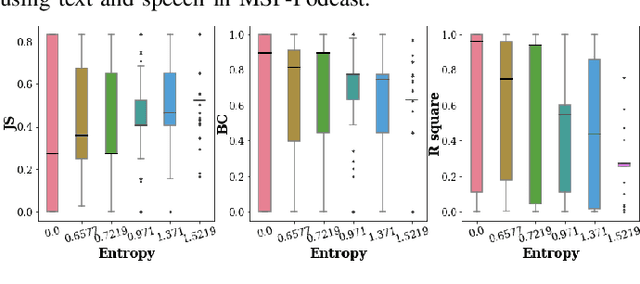
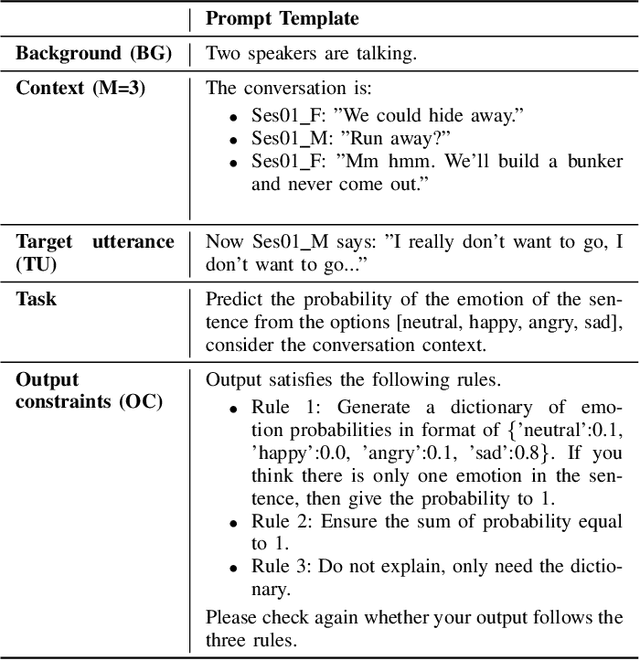
Recent advancements in Large Language Models (LLMs) have demonstrated great success in many Natural Language Processing (NLP) tasks. In addition to their cognitive intelligence, exploring their capabilities in emotional intelligence is also crucial, as it enables more natural and empathetic conversational AI. Recent studies have shown LLMs' capability in recognizing emotions, but they often focus on single emotion labels and overlook the complex and ambiguous nature of human emotions. This study is the first to address this gap by exploring the potential of LLMs in recognizing ambiguous emotions, leveraging their strong generalization capabilities and in-context learning. We design zero-shot and few-shot prompting and incorporate past dialogue as context information for ambiguous emotion recognition. Experiments conducted using three datasets indicate significant potential for LLMs in recognizing ambiguous emotions, and highlight the substantial benefits of including context information. Furthermore, our findings indicate that LLMs demonstrate a high degree of effectiveness in recognizing less ambiguous emotions and exhibit potential for identifying more ambiguous emotions, paralleling human perceptual capabilities.
Dual-Constrained Dynamical Neural ODEs for Ambiguity-aware Continuous Emotion Prediction
Jul 31, 2024There has been a significant focus on modelling emotion ambiguity in recent years, with advancements made in representing emotions as distributions to capture ambiguity. However, there has been comparatively less effort devoted to the consideration of temporal dependencies in emotion distributions which encodes ambiguity in perceived emotions that evolve smoothly over time. Recognizing the benefits of using constrained dynamical neural ordinary differential equations (CD-NODE) to model time series as dynamic processes, we propose an ambiguity-aware dual-constrained Neural ODE approach to model the dynamics of emotion distributions on arousal and valence. In our approach, we utilize ODEs parameterised by neural networks to estimate the distribution parameters, and we integrate additional constraints to restrict the range of the system outputs to ensure the validity of predicted distributions. We evaluated our proposed system on the publicly available RECOLA dataset and observed very promising performance across a range of evaluation metrics.
Binaural Selective Attention Model for Target Speaker Extraction
Jun 18, 2024



The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
What is Learnt by the LEArnable Front-end ? Adapting Per-Channel Energy Normalisation to Noisy Conditions
Apr 10, 2024There is increasing interest in the use of the LEArnable Front-end (LEAF) in a variety of speech processing systems. However, there is a dearth of analyses of what is actually learnt and the relative importance of training the different components of the front-end. In this paper, we investigate this question on keyword spotting, speech-based emotion recognition and language identification tasks and find that the filters for spectral decomposition and the low pass filter used to estimate spectral energy variations exhibit no learning and the per-channel energy normalisation (PCEN) is the key component that is learnt. Following this, we explore the potential of adapting only the PCEN layer with a small amount of noisy data to enable it to learn appropriate dynamic range compression that better suits the noise conditions. This in turn enables a system trained on clean speech to work more accurately on noisy test data as demonstrated by the experimental results reported in this paper.
* Interspeech 2023 Proceeding
Spatial HuBERT: Self-supervised Spatial Speech Representation Learning for a Single Talker from Multi-channel Audio
Oct 17, 2023Self-supervised learning has been used to leverage unlabelled data, improving accuracy and generalisation of speech systems through the training of representation models. While many recent works have sought to produce effective representations across a variety of acoustic domains, languages, modalities and even simultaneous speakers, these studies have all been limited to single-channel audio recordings. This paper presents Spatial HuBERT, a self-supervised speech representation model that learns both acoustic and spatial information pertaining to a single speaker in a potentially noisy environment by using multi-channel audio inputs. Spatial HuBERT learns representations that outperform state-of-the-art single-channel speech representations on a variety of spatial downstream tasks, particularly in reverberant and noisy environments. We also demonstrate the utility of the representations learned by Spatial HuBERT on a speech localisation downstream task. Along with this paper, we publicly release a new dataset of 100 000 simulated first-order ambisonics room impulse responses.
Variational Connectionist Temporal Classification for Order-Preserving Sequence Modeling
Sep 21, 2023Connectionist temporal classification (CTC) is commonly adopted for sequence modeling tasks like speech recognition, where it is necessary to preserve order between the input and target sequences. However, CTC is only applied to deterministic sequence models, where the latent space is discontinuous and sparse, which in turn makes them less capable of handling data variability when compared to variational models. In this paper, we integrate CTC with a variational model and derive loss functions that can be used to train more generalizable sequence models that preserve order. Specifically, we derive two versions of the novel variational CTC based on two reasonable assumptions, the first being that the variational latent variables at each time step are conditionally independent; and the second being that these latent variables are Markovian. We show that both loss functions allow direct optimization of the variational lower bound for the model log-likelihood, and present computationally tractable forms for implementing them.
A Novel Markovian Framework for Integrating Absolute and Relative Ordinal Emotion Information
Aug 10, 2021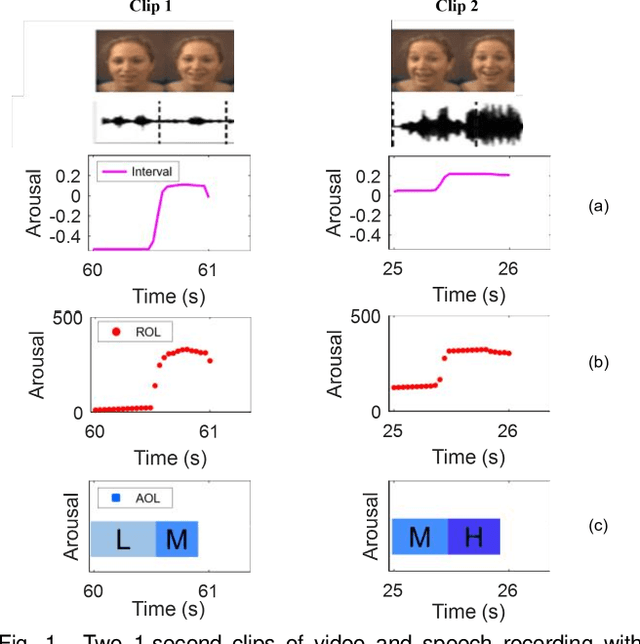
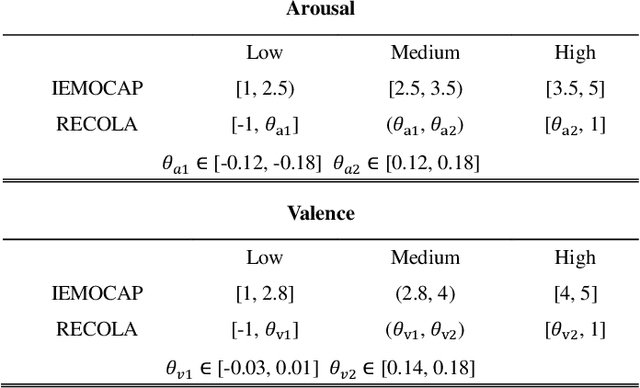
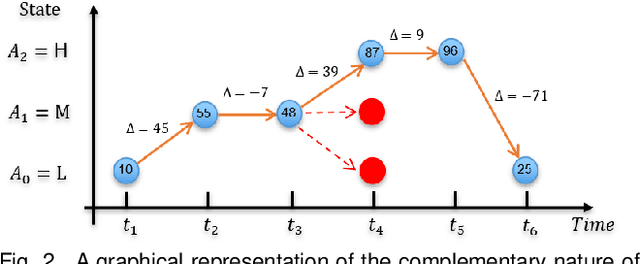
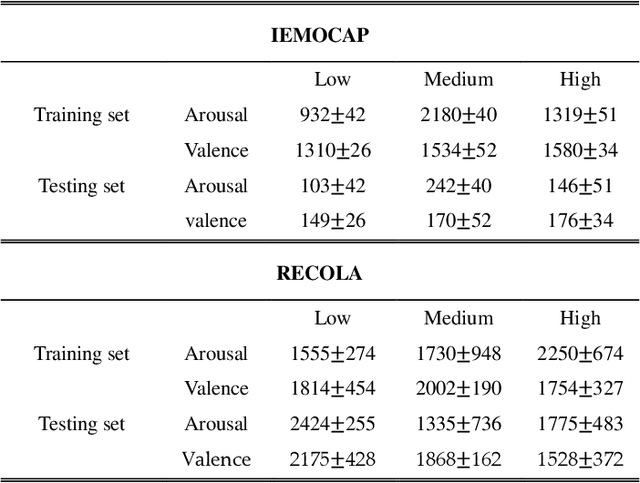
There is growing interest in affective computing for the representation and prediction of emotions along ordinal scales. However, the term ordinal emotion label has been used to refer to both absolute notions such as low or high arousal, as well as relation notions such as arousal is higher at one instance compared to another. In this paper, we introduce the terminology absolute and relative ordinal labels to make this distinction clear and investigate both with a view to integrate them and exploit their complementary nature. We propose a Markovian framework referred to as Dynamic Ordinal Markov Model (DOMM) that makes use of both absolute and relative ordinal information, to improve speech based ordinal emotion prediction. Finally, the proposed framework is validated on two speech corpora commonly used in affective computing, the RECOLA and the IEMOCAP databases, across a range of system configurations. The results consistently indicate that integrating relative ordinal information improves absolute ordinal emotion prediction.
The Ambiguous World of Emotion Representation
Sep 01, 2019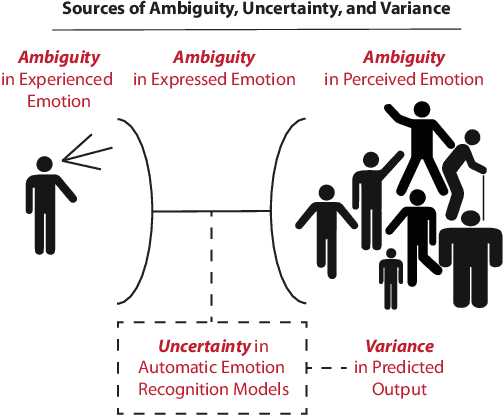


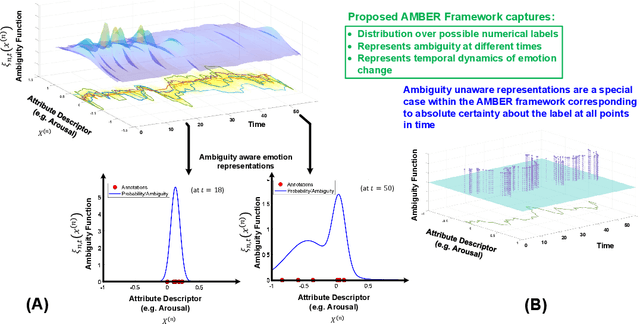
Artificial intelligence and machine learning systems have demonstrated huge improvements and human-level parity in a range of activities, including speech recognition, face recognition and speaker verification. However, these diverse tasks share a key commonality that is not true in affective computing: the ground truth information that is inferred can be unambiguously represented. This observation provides some hints as to why affective computing, despite having attracted the attention of researchers for years, may not still be considered a mature field of research. A key reason for this is the lack of a common mathematical framework to describe all the relevant elements of emotion representations. This paper proposes the AMBiguous Emotion Representation (AMBER) framework to address this deficiency. AMBER is a unified framework that explicitly describes categorical, numerical and ordinal representations of emotions, including time varying representations. In addition to explaining the core elements of AMBER, the paper also discusses how some of the commonly employed emotion representation schemes can be viewed through the AMBER framework, and concludes with a discussion of how the proposed framework can be used to reason about current and future affective computing systems.