 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Reasoning: Making an Audio Language Model Better at Comparing Emotions
Jun 23, 2026Large audio-language models (LALMs) can reason about audio, yet it remains unclear whether they can perform comparative judgments between two speech signals along emotional, environmental, linguistic, prosodic, and interpersonal dimensions. We study this question in the context of speech emotion recognition (SER), where the model determines which utterance exhibits higher arousal, valence, or dominance. We introduce a reasoning-guided ordinal SER framework that conditions an LALM on paired speech inputs. The model is trained using reasoning traces generated from both semantic audio descriptions and acoustic evidence derived from GeMAPS features, enabling interpretable comparative decisions. Beyond direct supervision, we also employ direct preference optimization to encourage stronger separation for emotional differences. Experiments show that the proposed framework improves preference prediction while requiring only 5% of the training data used by conventional ordinal SER systems.
MSP-Conversation: A Corpus for Naturalistic, Time-Continuous Emotion Recognition
Mar 23, 2026Affective computing aims to understand and model human emotions for computational systems. Within this field, speech emotion recognition (SER) focuses on predicting emotions conveyed through speech. While early SER systems relied on limited datasets and traditional machine learning models, recent deep learning approaches demand largescale, naturalistic emotional corpora. To address this need, we introduce the MSP-Conversation corpus: a dataset of more than 70 hours of conversational audio with time-continuous emotional annotations and detailed speaker diarizations. The time-continuous annotations capture the dynamic and contextdependent nature of emotional expression. The annotations in the corpus include fine-grained temporal traces of valence, arousal, and dominance. The audio data is sourced from publicly available podcasts and overlaps with a subset of the isolated speaking turns in the MSP-Podcast corpus to facilitate direct comparisons between annotation methods (i.e., in-context versus out-of-context annotations). The paper outlines the development of the corpus, annotation methodology, analyses of the annotations, and baseline SER experiments, establishing the MSP-Conversation corpus as a valuable resource for advancing research in dynamic SER in naturalistic settings.
The Interspeech 2026 Audio Reasoning Challenge: Evaluating Reasoning Process Quality for Audio Reasoning Models and Agents
Feb 15, 2026Recent Large Audio Language Models (LALMs) excel in understanding but often lack transparent reasoning. To address this "black-box" limitation, we organized the Audio Reasoning Challenge at Interspeech 2026, the first shared task dedicated to evaluating Chain-of-Thought (CoT) quality in the audio domain. The challenge introduced MMAR-Rubrics, a novel instance-level protocol assessing the factuality and logic of reasoning chains. Featured Single Model and Agent tracks, the competition attracting 156 teams from 18 countries and regions. Results show agent systems currently lead in reasoning quality, utilizing iterative tool orchestration and cross-modal analysis. Besides, single models are rapidly advancing via reinforcement learning and sophisticated data pipeline. We details the challenge design, methodology, and a comprehensive analysis of state-of-the-art systems, providing new insights for explainable audio intelligence.
ADEPT: RL-Aligned Agentic Decoding of Emotion via Evidence Probing Tools -- From Consensus Learning to Ambiguity-Driven Emotion Reasoning
Feb 13, 2026Speech Large Language Models (SLLMs) enable high-level emotion reasoning but often produce ungrounded, text-biased judgments without verifiable acoustic evidence. In contrast, self-supervised speech encoders such as WavLM provide strong acoustic representations yet remain opaque discriminative models with limited interpretability. To bridge this gap, we introduce ADEPT (Agentic Decoding of Emotion via Evidence Probing Tools), a framework that reframes emotion recognition as a multi-turn inquiry process rather than a single-pass prediction. ADEPT transforms an SLLM into an agent that maintains an evolving candidate emotion set and adaptively invokes dedicated semantic and acoustic probing tools within a structured pipeline of candidate generation, evidence collection, and adjudication. Crucially, ADEPT enables a paradigm shift from consensus learning to ambiguity-driven emotion reasoning. Since human affect exhibits inherent complexity and frequent co-occurrence of emotions, we treat minority annotations as informative perceptual signals rather than discarding them as noise. Finally, we integrate Group Relative Policy Optimization (GRPO) with an Evidence Trust Gate to explicitly couple tool-usage behaviors with prediction quality and enforce evidence-grounded reasoning. Experiments show that ADEPT improves primary emotion accuracy in most settings while substantially improving minor emotion characterization, producing explanations grounded in auditable acoustic and semantic evidence.
Sentipolis: Emotion-Aware Agents for Social Simulations
Jan 25, 2026LLM agents are increasingly used for social simulation, yet emotion is often treated as a transient cue, causing emotional amnesia and weak long-horizon continuity. We present Sentipolis, a framework for emotionally stateful agents that integrates continuous Pleasure-Arousal-Dominance (PAD) representation, dual-speed emotion dynamics, and emotion--memory coupling. Across thousands of interactions over multiple base models and evaluators, Sentipolis improves emotionally grounded behavior, boosting communication, and emotional continuity. Gains are model-dependent: believability increases for higher-capacity models but can drop for smaller ones, and emotion-awareness can mildly reduce adherence to social norms, reflecting a human-like tension between emotion-driven behavior and rule compliance in social simulation. Network-level diagnostics show reciprocal, moderately clustered, and temporally stable relationship structures, supporting the study of cumulative social dynamics such as alliance formation and gradual relationship change.
Recovering Performance in Speech Emotion Recognition from Discrete Tokens via Multi-Layer Fusion and Paralinguistic Feature Integration
Jan 23, 2026Discrete speech tokens offer significant advantages for storage and language model integration, but their application in speech emotion recognition (SER) is limited by paralinguistic information loss during quantization. This paper presents a comprehensive investigation of discrete tokens for SER. Using a fine-tuned WavLM-Large model, we systematically quantify performance degradation across different layer configurations and k-means quantization granularities. To recover the information loss, we propose two key strategies: (1) attention-based multi-layer fusion to recapture complementary information from different layers, and (2) integration of openSMILE features to explicitly reintroduce paralinguistic cues. We also compare mainstream neural codec tokenizers (SpeechTokenizer, DAC, EnCodec) and analyze their behaviors when fused with acoustic features. Our findings demonstrate that through multi-layer fusion and acoustic feature integration, discrete tokens can close the performance gap with continuous representations in SER tasks.
On the Fallacy of Global Token Perplexity in Spoken Language Model Evaluation
Jan 09, 2026Generative spoken language models pretrained on large-scale raw audio can continue a speech prompt with appropriate content while preserving attributes like speaker and emotion, serving as foundation models for spoken dialogue. In prior literature, these models are often evaluated using ``global token perplexity'', which directly applies the text perplexity formulation to speech tokens. However, this practice overlooks fundamental differences between speech and text modalities, possibly leading to an underestimation of the speech characteristics. In this work, we propose a variety of likelihood- and generative-based evaluation methods that serve in place of naive global token perplexity. We demonstrate that the proposed evaluations more faithfully reflect perceived generation quality, as evidenced by stronger correlations with human-rated mean opinion scores (MOS). When assessed under the new metrics, the relative performance landscape of spoken language models is reshaped, revealing a significantly reduced gap between the best-performing model and the human topline. Together, these results suggest that appropriate evaluation is critical for accurately assessing progress in spoken language modeling.
Joint Learning using Mixture-of-Expert-Based Representation for Enhanced Speech Generation and Robust Emotion Recognition
Sep 10, 2025Speech emotion recognition (SER) plays a critical role in building emotion-aware speech systems, but its performance degrades significantly under noisy conditions. Although speech enhancement (SE) can improve robustness, it often introduces artifacts that obscure emotional cues and adds computational overhead to the pipeline. Multi-task learning (MTL) offers an alternative by jointly optimizing SE and SER tasks. However, conventional shared-backbone models frequently suffer from gradient interference and representational conflicts between tasks. To address these challenges, we propose the Sparse Mixture-of-Experts Representation Integration Technique (Sparse MERIT), a flexible MTL framework that applies frame-wise expert routing over self-supervised speech representations. Sparse MERIT incorporates task-specific gating networks that dynamically select from a shared pool of experts for each frame, enabling parameter-efficient and task-adaptive representation learning. Experiments on the MSP-Podcast corpus show that Sparse MERIT consistently outperforms baseline models on both SER and SE tasks. Under the most challenging condition of -5 dB signal-to-noise ratio (SNR), Sparse MERIT improves SER F1-macro by an average of 12.0% over a baseline relying on a SE pre-processing strategy, and by 3.4% over a naive MTL baseline, with statistical significance on unseen noise conditions. For SE, Sparse MERIT improves segmental SNR (SSNR) by 28.2% over the SE pre-processing baseline and by 20.0% over the naive MTL baseline. These results demonstrate that Sparse MERIT provides robust and generalizable performance for both emotion recognition and enhancement tasks in noisy environments.
Can Emotion Fool Anti-spoofing?
May 29, 2025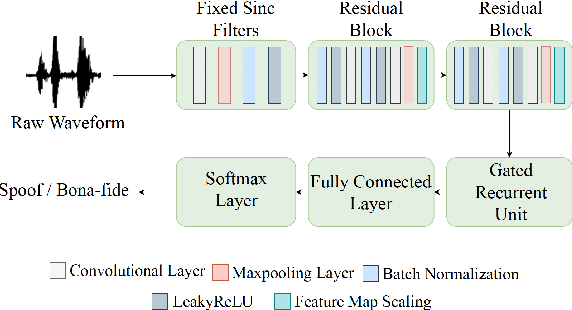
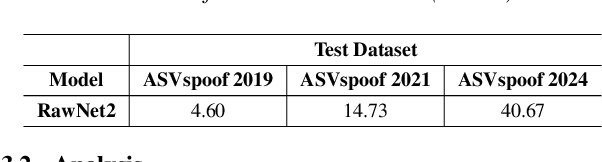
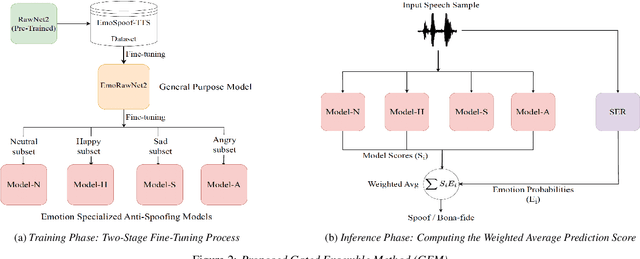
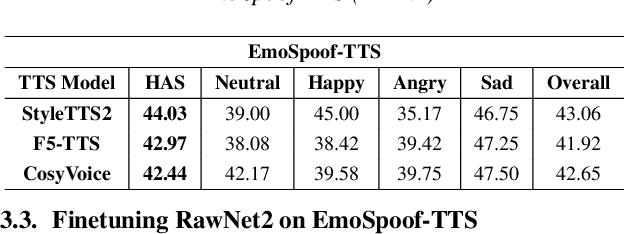
Traditional anti-spoofing focuses on models and datasets built on synthetic speech with mostly neutral state, neglecting diverse emotional variations. As a result, their robustness against high-quality, emotionally expressive synthetic speech is uncertain. We address this by introducing EmoSpoof-TTS, a corpus of emotional text-to-speech samples. Our analysis shows existing anti-spoofing models struggle with emotional synthetic speech, exposing risks of emotion-targeted attacks. Even trained on emotional data, the models underperform due to limited focus on emotional aspect and show performance disparities across emotions. This highlights the need for emotion-focused anti-spoofing paradigm in both dataset and methodology. We propose GEM, a gated ensemble of emotion-specialized models with a speech emotion recognition gating network. GEM performs effectively across all emotions and neutral state, improving defenses against spoofing attacks. We release the EmoSpoof-TTS Dataset: https://emospoof-tts.github.io/Dataset/
EmotionRankCLAP: Bridging Natural Language Speaking Styles and Ordinal Speech Emotion via Rank-N-Contrast
May 29, 2025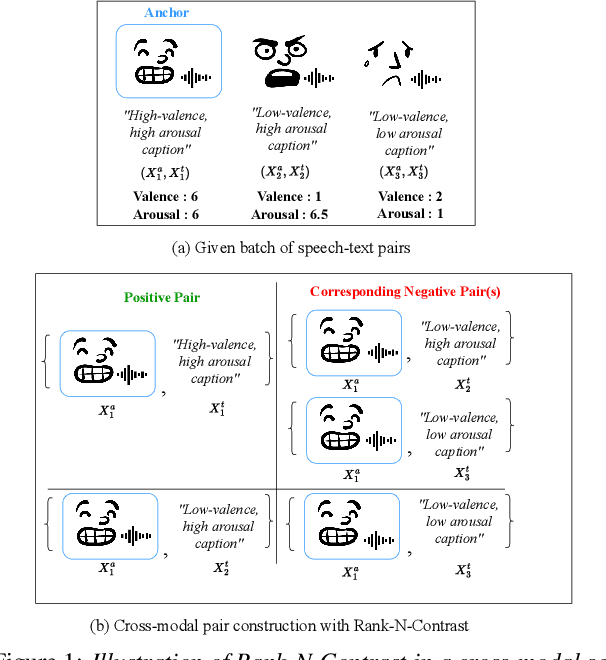


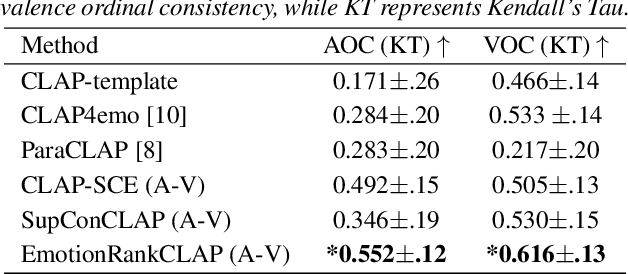
Current emotion-based contrastive language-audio pretraining (CLAP) methods typically learn by na\"ively aligning audio samples with corresponding text prompts. Consequently, this approach fails to capture the ordinal nature of emotions, hindering inter-emotion understanding and often resulting in a wide modality gap between the audio and text embeddings due to insufficient alignment. To handle these drawbacks, we introduce EmotionRankCLAP, a supervised contrastive learning approach that uses dimensional attributes of emotional speech and natural language prompts to jointly capture fine-grained emotion variations and improve cross-modal alignment. Our approach utilizes a Rank-N-Contrast objective to learn ordered relationships by contrasting samples based on their rankings in the valence-arousal space. EmotionRankCLAP outperforms existing emotion-CLAP methods in modeling emotion ordinality across modalities, measured via a cross-modal retrieval task.