 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Kernel Conformal Depth Measures Algorithm for Uncertainty Quantification in Regression Models in Separable Hilbert Spaces
Jun 10, 2025Depth measures are powerful tools for defining level sets in emerging, non--standard, and complex random objects such as high-dimensional multivariate data, functional data, and random graphs. Despite their favorable theoretical properties, the integration of depth measures into regression modeling to provide prediction regions remains a largely underexplored area of research. To address this gap, we propose a novel, model-free uncertainty quantification algorithm based on conditional depth measures--specifically, conditional kernel mean embeddings and an integrated depth measure. These new algorithms can be used to define prediction and tolerance regions when predictors and responses are defined in separable Hilbert spaces. The use of kernel mean embeddings ensures faster convergence rates in prediction region estimation. To enhance the practical utility of the algorithms with finite samples, we also introduce a conformal prediction variant that provides marginal, non-asymptotic guarantees for the derived prediction regions. Additionally, we establish both conditional and unconditional consistency results, as well as fast convergence rates in certain homoscedastic settings. We evaluate the finite--sample performance of our model in extensive simulation studies involving various types of functional data and traditional Euclidean scenarios. Finally, we demonstrate the practical relevance of our approach through a digital health application related to physical activity, aiming to provide personalized recommendations
Describe Where You Are: Improving Noise-Robustness for Speech Emotion Recognition with Text Description of the Environment
Jul 25, 2024


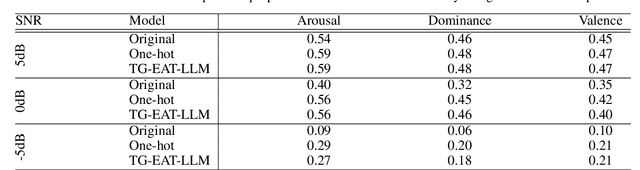
Speech emotion recognition (SER) systems often struggle in real-world environments, where ambient noise severely degrades their performance. This paper explores a novel approach that exploits prior knowledge of testing environments to maximize SER performance under noisy conditions. To address this task, we propose a text-guided, environment-aware training where an SER model is trained with contaminated speech samples and their paired noise description. We use a pre-trained text encoder to extract the text-based environment embedding and then fuse it to a transformer-based SER model during training and inference. We demonstrate the effectiveness of our approach through our experiment with the MSP-Podcast corpus and real-world additive noise samples collected from the Freesound repository. Our experiment indicates that the text-based environment descriptions processed by a large language model (LLM) produce representations that improve the noise-robustness of the SER system. In addition, our proposed approach with an LLM yields better performance than our environment-agnostic baselines, especially in low signal-to-noise ratio (SNR) conditions. When testing at -5dB SNR level, our proposed method shows better performance than our best baseline model by 31.8 % (arousal), 23.5% (dominance), and 9.5% (valence).
Deep Learning Framework with Uncertainty Quantification for Survey Data: Assessing and Predicting Diabetes Mellitus Risk in the American Population
Mar 28, 2024Complex survey designs are commonly employed in many medical cohorts. In such scenarios, developing case-specific predictive risk score models that reflect the unique characteristics of the study design is essential. This approach is key to minimizing potential selective biases in results. The objectives of this paper are: (i) To propose a general predictive framework for regression and classification using neural network (NN) modeling, which incorporates survey weights into the estimation process; (ii) To introduce an uncertainty quantification algorithm for model prediction, tailored for data from complex survey designs; (iii) To apply this method in developing robust risk score models to assess the risk of Diabetes Mellitus in the US population, utilizing data from the NHANES 2011-2014 cohort. The theoretical properties of our estimators are designed to ensure minimal bias and the statistical consistency, thereby ensuring that our models yield reliable predictions and contribute novel scientific insights in diabetes research. While focused on diabetes, this NN predictive framework is adaptable to create clinical models for a diverse range of diseases and medical cohorts. The software and the data used in this paper is publicly available on GitHub.
kNN Algorithm for Conditional Mean and Variance Estimation with Automated Uncertainty Quantification and Variable Selection
Feb 02, 2024In this paper, we introduce a kNN-based regression method that synergizes the scalability and adaptability of traditional non-parametric kNN models with a novel variable selection technique. This method focuses on accurately estimating the conditional mean and variance of random response variables, thereby effectively characterizing conditional distributions across diverse scenarios.Our approach incorporates a robust uncertainty quantification mechanism, leveraging our prior estimation work on conditional mean and variance. The employment of kNN ensures scalable computational efficiency in predicting intervals and statistical accuracy in line with optimal non-parametric rates. Additionally, we introduce a new kNN semi-parametric algorithm for estimating ROC curves, accounting for covariates. For selecting the smoothing parameter k, we propose an algorithm with theoretical guarantees.Incorporation of variable selection enhances the performance of the method significantly over conventional kNN techniques in various modeling tasks. We validate the approach through simulations in low, moderate, and high-dimensional covariate spaces. The algorithm's effectiveness is particularly notable in biomedical applications as demonstrated in two case studies. Concluding with a theoretical analysis, we highlight the consistency and convergence rate of our method over traditional kNN models, particularly when the underlying regression model takes values in a low-dimensional space.
Nonparametric Additive Value Functions: Interpretable Reinforcement Learning with an Application to Surgical Recovery
Aug 25, 2023We propose a nonparametric additive model for estimating interpretable value functions in reinforcement learning. Learning effective adaptive clinical interventions that rely on digital phenotyping features is a major for concern medical practitioners. With respect to spine surgery, different post-operative recovery recommendations concerning patient mobilization can lead to significant variation in patient recovery. While reinforcement learning has achieved widespread success in domains such as games, recent methods heavily rely on black-box methods, such neural networks. Unfortunately, these methods hinder the ability of examining the contribution each feature makes in producing the final suggested decision. While such interpretations are easily provided in classical algorithms such as Least Squares Policy Iteration, basic linearity assumptions prevent learning higher-order flexible interactions between features. In this paper, we present a novel method that offers a flexible technique for estimating action-value functions without making explicit parametric assumptions regarding their additive functional form. This nonparametric estimation strategy relies on incorporating local kernel regression and basis expansion to obtain a sparse, additive representation of the action-value function. Under this approach, we are able to locally approximate the action-value function and retrieve the nonlinear, independent contribution of select features as well as joint feature pairs. We validate the proposed approach with a simulation study, and, in an application to spine disease, uncover recovery recommendations that are inline with related clinical knowledge.
A 'one-size-fits-most' walking recognition method for smartphones, smartwatches, and wearable accelerometers
Jul 15, 2022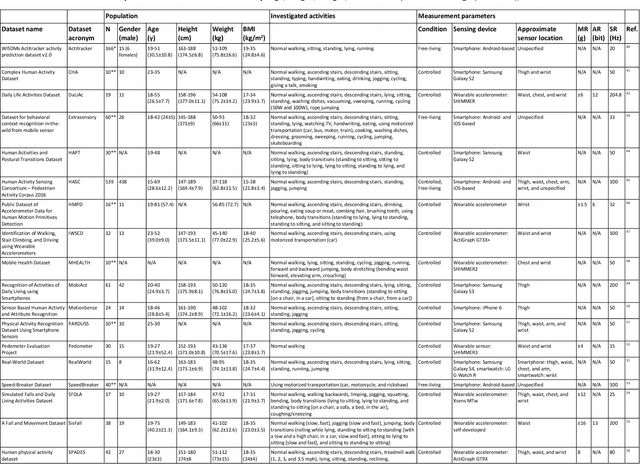
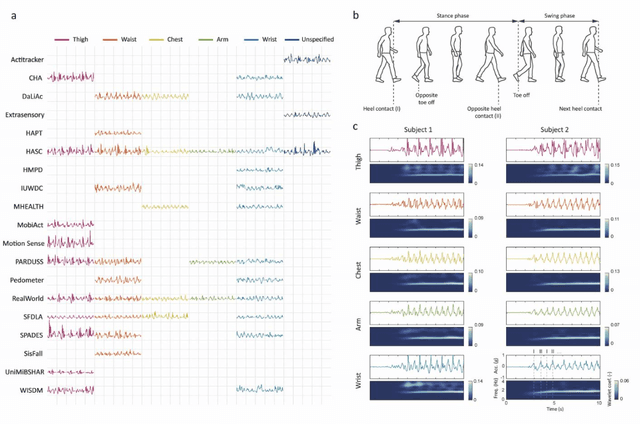
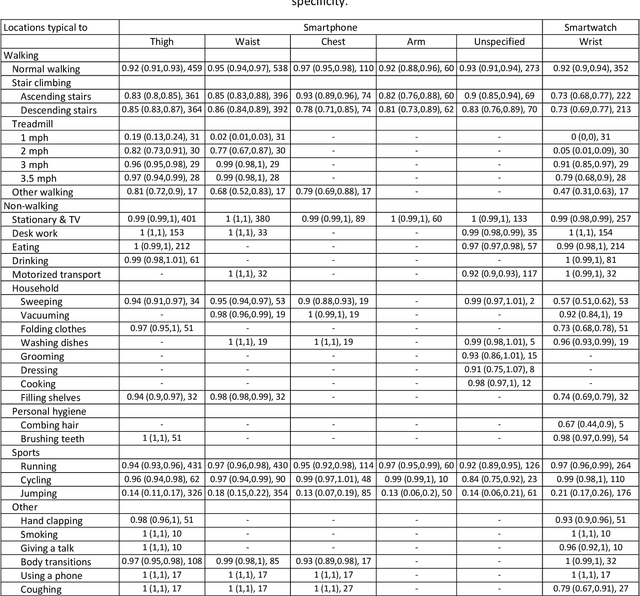
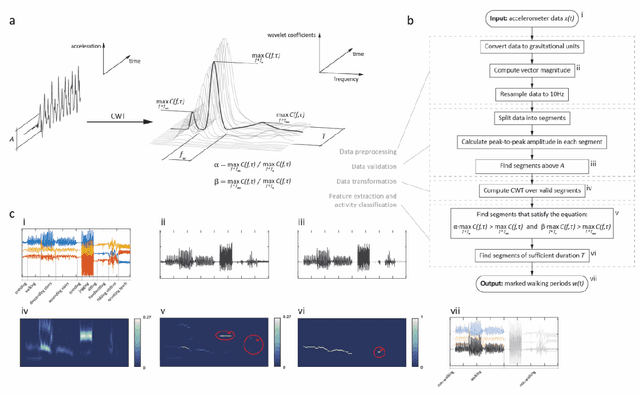
The ubiquity of personal digital devices offers unprecedented opportunities to study human behavior. Current state-of-the-art methods quantify physical activity using 'activity counts,' a measure which overlooks specific types of physical activities. We proposed a walking recognition method for sub-second tri-axial accelerometer data, in which activity classification is based on the inherent features of walking: intensity, periodicity, and duration. We validated our method against 20 publicly available, annotated datasets on walking activity data collected at various body locations (thigh, waist, chest, arm, wrist). We demonstrated that our method can estimate walking periods with high sensitivity and specificity: average sensitivity ranged between 0.92 and 0.97 across various body locations, and average specificity for common daily activities was typically above 0.95. We also assessed the method's algorithmic fairness to demographic and anthropometric variables and measurement contexts (body location, environment). Finally, we have released our method as open-source software in MATLAB and Python.
Minimizing the Expected Posterior Entropy Yields Optimal Summary Statistics
Jun 06, 2022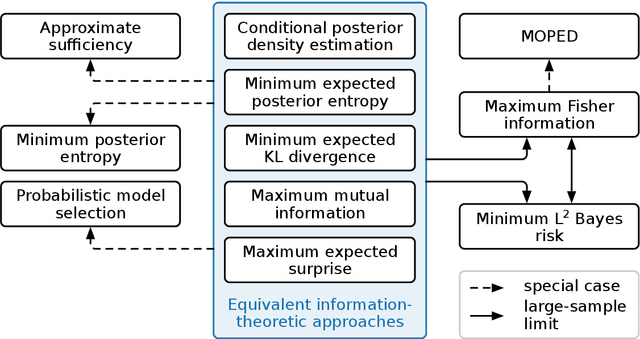
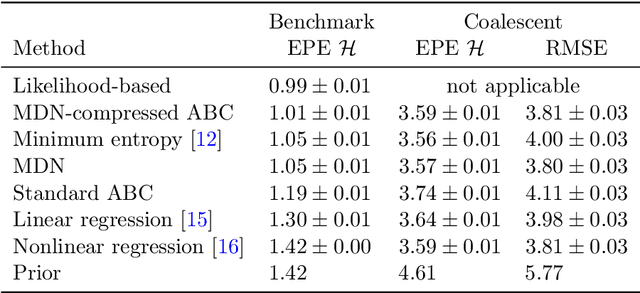
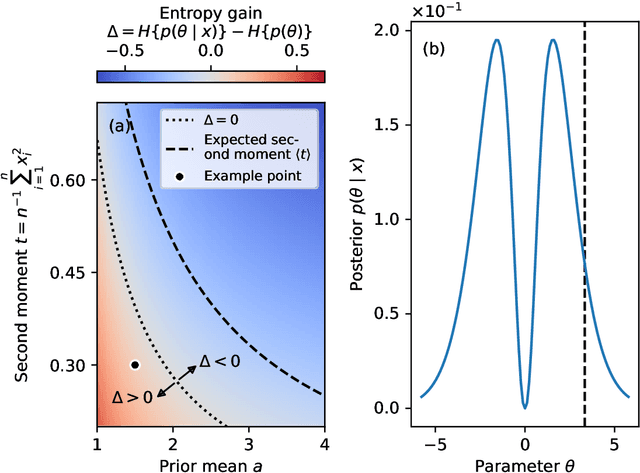

Extracting low-dimensional summary statistics from large datasets is essential for efficient (likelihood-free) inference. We propose obtaining summary statistics by minimizing the expected posterior entropy (EPE) under the prior predictive distribution of the model. We show that minimizing the EPE is equivalent to learning a conditional density estimator for the posterior as well as other information-theoretic approaches. Further summary extraction methods (including minimizing the $L^2$ Bayes risk, maximizing the Fisher information, and model selection approaches) are special or limiting cases of EPE minimization. We demonstrate that the approach yields high fidelity summary statistics by applying it to both a synthetic benchmark as well as a population genetics problem. We not only offer concrete recommendations for practitioners but also provide a unifying perspective for obtaining informative summary statistics.
Selection of Summary Statistics for Network Model Choice with Approximate Bayesian Computation
Jan 19, 2021

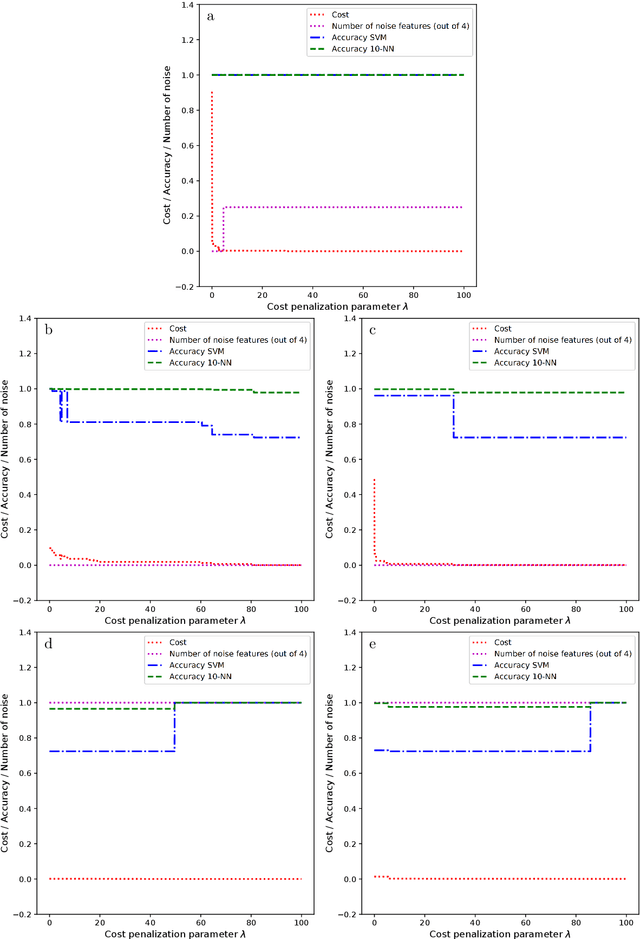
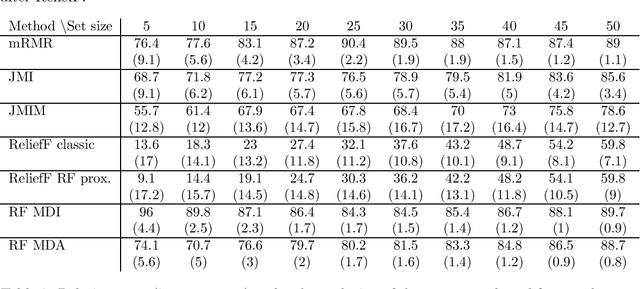
Approximate Bayesian Computation (ABC) now serves as one of the major strategies to perform model choice and parameter inference on models with intractable likelihoods. An essential component of ABC involves comparing a large amount of simulated data with the observed data through summary statistics. To avoid the curse of dimensionality, summary statistic selection is of prime importance, and becomes even more critical when applying ABC to mechanistic network models. Indeed, while many summary statistics can be used to encode network structures, their computational complexity can be highly variable. For large networks, computation of summary statistics can quickly create a bottleneck, making the use of ABC difficult. To reduce this computational burden and make the analysis of mechanistic network models more practical, we investigated two questions in a model choice framework. First, we studied the utility of cost-based filter selection methods to account for different summary costs during the selection process. Second, we performed selection using networks generated with a smaller number of nodes to reduce the time required for the selection step. Our findings show that computationally inexpensive summary statistics can be efficiently selected with minimal impact on classification accuracy. Furthermore, we found that networks with a smaller number of nodes can only be employed to eliminate a moderate number of summaries. While this latter finding is network specific, the former is general and can be adapted to any ABC application.
A systematic review of human activity recognition using smartphones
Oct 07, 2019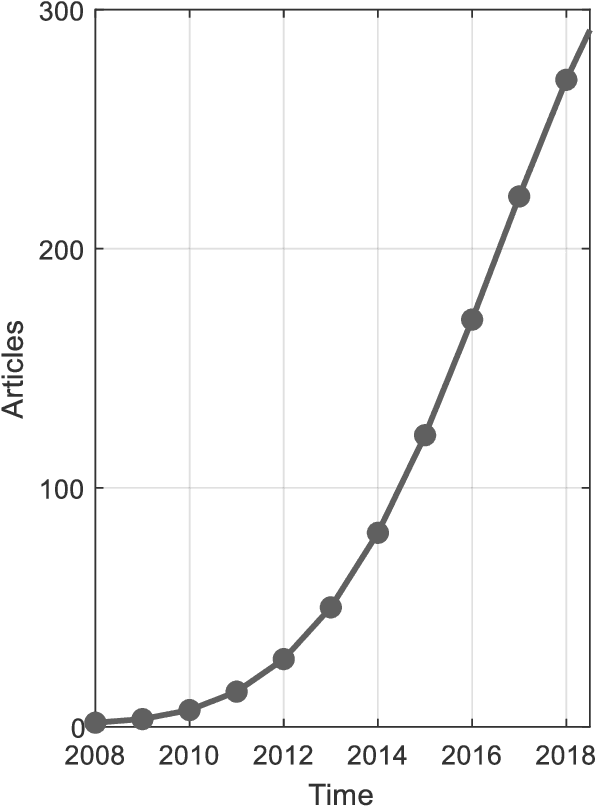
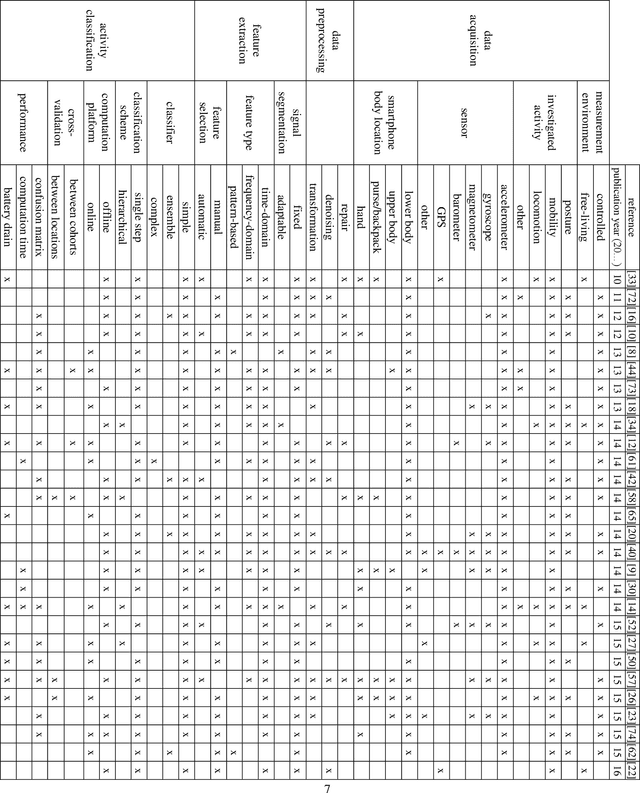
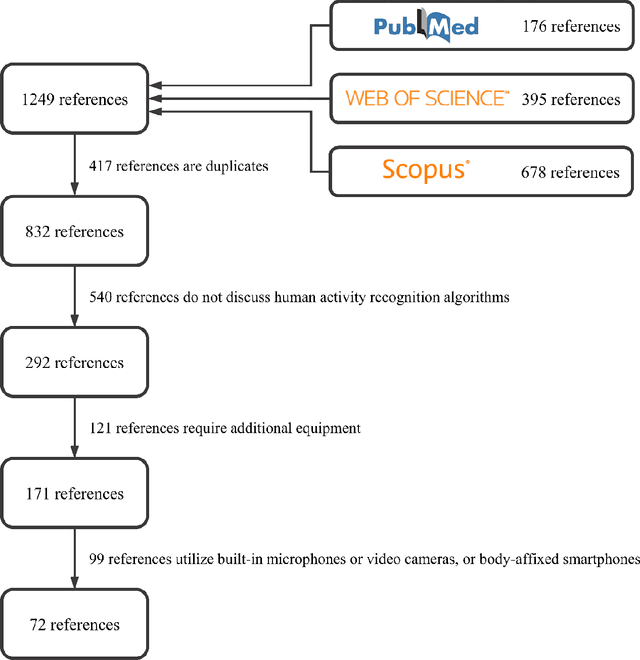
Smartphones have become a global communication tool and more recently a technology for studying human behavior. Given their numerous built-in sensors, smartphones are able to capture detailed and continuous observations on activities of daily living. However, translation of measurements from these consumer-grade devices into research-grade physical activity patterns remains challenging. Over the years, researchers have proposed various human activity recognition (HAR) systems which vary in algorithmic details and statistical principles. In this paper, we summarize existing approaches to smartphone-based HAR. We systematically screened the literature on Scopus, PubMed, and Web of Science in the areas of data acquisition, data preprocessing, feature extraction, and activity classification. We ultimately identified 72 articles on smartphone-based HAR. To provide an understanding of the literature, we discuss each of these areas separately, identify the most common practices and their alternatives, and propose possible future research directions for this interesting and important field.
Bayesian Inference of Spreading Processes on Networks
May 21, 2018
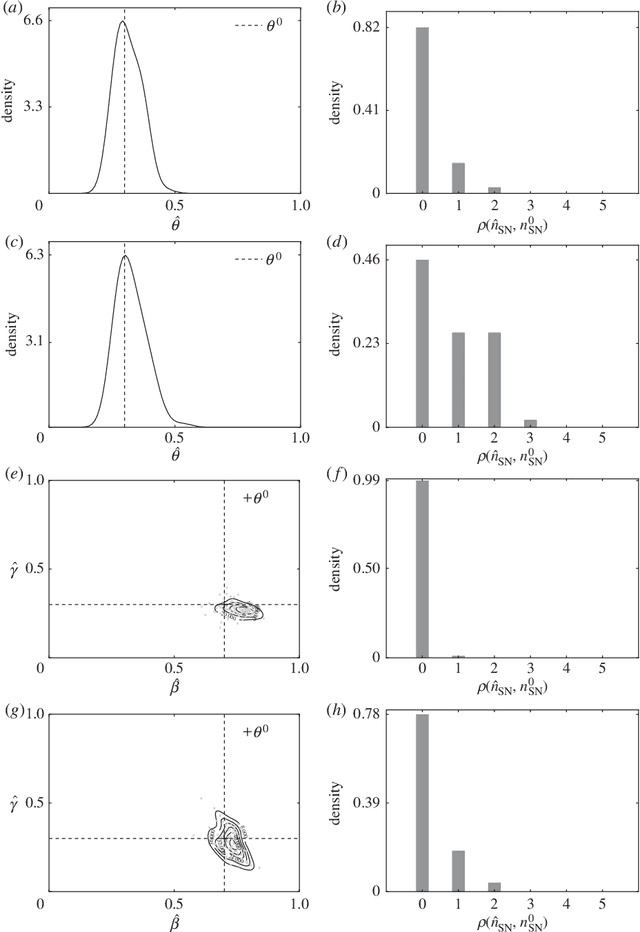
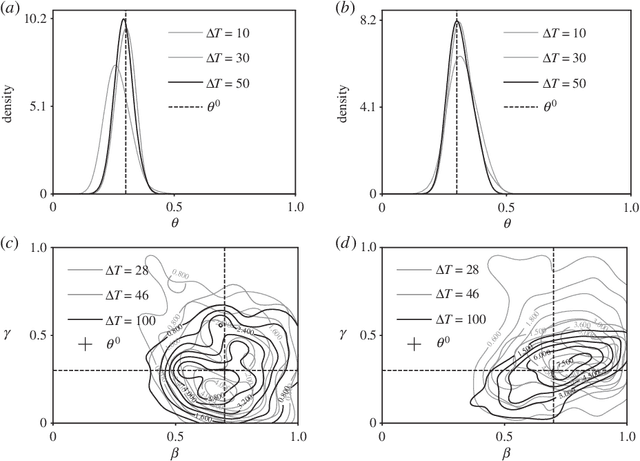
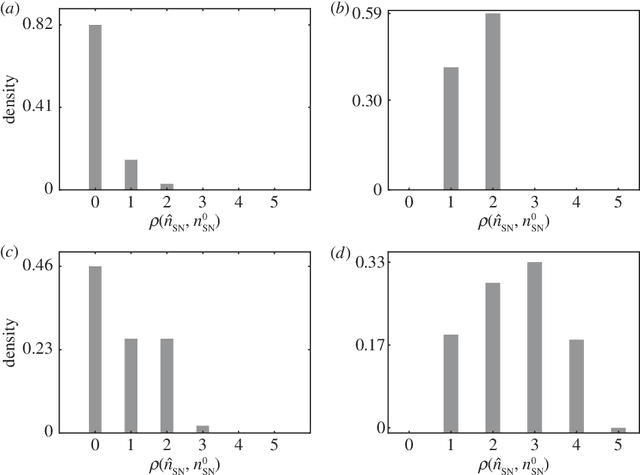
Infectious diseases are studied to understand their spreading mechanisms, to evaluate control strategies and to predict the risk and course of future outbreaks. Because people only interact with a small number of individuals, and because the structure of these interactions matters for spreading processes, the pairwise relationships between individuals in a population can be usefully represented by a network. Although the underlying processes of transmission are different, the network approach can be used to study the spread of pathogens in a contact network or the spread of rumors in an online social network. We study simulated simple and complex epidemics on synthetic networks and on two empirical networks, a social / contact network in an Indian village and an online social network in the U.S. Our goal is to learn simultaneously about the spreading process parameters and the source node (first infected node) of the epidemic, given a fixed and known network structure, and observations about state of nodes at several points in time. Our inference scheme is based on approximate Bayesian computation (ABC), an inference technique for complex models with likelihood functions that are either expensive to evaluate or analytically intractable. ABC enables us to adopt a Bayesian approach to the problem despite the posterior distribution being very complex. Our method is agnostic about the topology of the network and the nature of the spreading process. It generally performs well and, somewhat counter-intuitively, the inference problem appears to be easier on more heterogeneous network topologies, which enhances its future applicability to real-world settings where few networks have homogeneous topologies.