 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian mixture models in Hilbert spaces via kernel methods
May 07, 2026Modern datasets across many disciplines increasingly consist of time-evolving, potentially infinite-dimensional random objects, such as dynamic functional data, which are naturally modeled in Hilbert spaces. In these settings, characterizing probability measures, for example, through densities, can be ill-defined or technically challenging. Motivated by clustering applications, we propose a Gaussian mixture framework for Hilbert-space-valued data based on kernel mean embeddings and develop efficient optimization algorithms for estimation. We establish theoretical guarantees showing that the proposed algorithm is well defined and that the model yields a dense class of approximations in infinite-dimensional spaces. We evaluate the framework through extensive experiments on diverse structures and data geometries, including $L^2$-functional data and random graphs in Laplacian spaces arising in modern medical applications.
Random-Effects Algorithm for Random Objects in Metric Spaces
May 04, 2026Across many scientific disciplines, multiple observations are collected from the same experimental units, and in modern datasets these observations often arise as non-Euclidean random objects. In such settings, the incorporation of random effects is a critical modeling step for efficient estimation and personalized prediction. Although mixed-effects models are well established for scalar outcomes and, more recently, for functional data in Hilbert spaces, general random-effects frameworks for objects in metric spaces remain underdeveloped. In this paper, we propose a nonlinear Fréchet-based algorithm for random-effects modeling of arbitrary random objects defined on a metric space. Using M-estimation theory, we establish conditions under which the proposed metric-space prediction target is consistently estimated under a working random-effects formulation. We then evaluate the empirical performance of the proposed method using both synthetic data and digital health datasets that require practical tools for analyzing random objects in metric spaces, such as multivariate probability distributions and random graphs. We show that, although our method is developed beyond Hilbert spaces, it can outperform existing Hilbert space-based methods.
Continuous-Time Learning of Probability Distributions: A Case Study in a Digital Trial of Young Children with Type 1 Diabetes
Mar 25, 2026Understanding how biomarker distributions evolve over time is a central challenge in digital health and chronic disease monitoring. In diabetes, changes in the distribution of glucose measurements can reveal patterns of disease progression and treatment response that conventional summary measures miss. Motivated by a 26-week clinical trial comparing the closed-loop insulin delivery system t:slim X2 with standard therapy in children with type 1 diabetes, we propose a probabilistic framework to model the continuous-time evolution of time-indexed distributions using continuous glucose monitoring data (CGM) collected every five minutes. We represent the glucose distribution as a Gaussian mixture, with time-varying mixture weights governed by a neural ODE. We estimate the model parameter using a distribution-matching criterion based on the maximum mean discrepancy. The resulting framework is interpretable, computationally efficient, and sensitive to subtle temporal distributional changes. Applied to CGM trial data, the method detects treatment-related improvements in glucose dynamics that are difficult to capture with traditional analytical approaches.
Distributional Random Forests for Complex Survey Designs on Reproducing Kernel Hilbert Spaces
Dec 09, 2025We study estimation of the conditional law $P(Y|X=\mathbf{x})$ and continuous functionals $Ψ(P(Y|X=\mathbf{x}))$ when $Y$ takes values in a locally compact Polish space, $X \in \mathbb{R}^p$, and the observations arise from a complex survey design. We propose a survey-calibrated distributional random forest (SDRF) that incorporates complex-design features via a pseudo-population bootstrap, PSU-level honesty, and a Maximum Mean Discrepancy (MMD) split criterion computed from kernel mean embeddings of Hájek-type (design-weighted) node distributions. We provide a framework for analyzing forest-style estimators under survey designs; establish design consistency for the finite-population target and model consistency for the super-population target under explicit conditions on the design, kernel, resampling multipliers, and tree partitions. As far as we are aware, these are the first results on model-free estimation of conditional distributions under survey designs. Simulations under a stratified two-stage cluster design provide finite sample performance and demonstrate the statistical error price of ignoring the survey design. The broad applicability of SDRF is demonstrated using NHANES: We estimate the tolerance regions of the conditional joint distribution of two diabetes biomarkers, illustrating how distributional heterogeneity can support subgroup-specific risk profiling for diabetes mellitus in the U.S. population.
ROC Analysis with Covariate Adjustment Using Neural Network Models: Evaluating the Role of Age in the Physical Activity-Mortality Association
Oct 16, 2025The receiver operating characteristic (ROC) curve and its summary measure, the Area Under the Curve (AUC), are well-established tools for evaluating the efficacy of biomarkers in biomedical studies. Compared to the traditional ROC curve, the covariate-adjusted ROC curve allows for individual evaluation of the biomarker. However, the use of machine learning models has rarely been explored in this context, despite their potential to develop more powerful and sophisticated approaches for biomarker evaluation. The goal of this paper is to propose a framework for neural network-based covariate-adjusted ROC modeling that allows flexible and nonlinear evaluation of the effectiveness of a biomarker to discriminate between two reference populations. The finite-sample performance of our method is investigated through extensive simulation tests under varying dependency structures between biomarkers, covariates, and referenced populations. The methodology is further illustrated in a clinically case study that assesses daily physical activity - measured as total activity time (TAC), a proxy for daily step count-as a biomarker to predict mortality at three, five and eight years. Analyzes stratified by sex and adjusted for age and BMI reveal distinct covariate effects on mortality outcomes. These results underscore the importance of covariate-adjusted modeling in biomarker evaluation and highlight TAC's potential as a functional capacity biomarker based on specific individual characteristics.
Model-Free Kernel Conformal Depth Measures Algorithm for Uncertainty Quantification in Regression Models in Separable Hilbert Spaces
Jun 10, 2025Depth measures are powerful tools for defining level sets in emerging, non--standard, and complex random objects such as high-dimensional multivariate data, functional data, and random graphs. Despite their favorable theoretical properties, the integration of depth measures into regression modeling to provide prediction regions remains a largely underexplored area of research. To address this gap, we propose a novel, model-free uncertainty quantification algorithm based on conditional depth measures--specifically, conditional kernel mean embeddings and an integrated depth measure. These new algorithms can be used to define prediction and tolerance regions when predictors and responses are defined in separable Hilbert spaces. The use of kernel mean embeddings ensures faster convergence rates in prediction region estimation. To enhance the practical utility of the algorithms with finite samples, we also introduce a conformal prediction variant that provides marginal, non-asymptotic guarantees for the derived prediction regions. Additionally, we establish both conditional and unconditional consistency results, as well as fast convergence rates in certain homoscedastic settings. We evaluate the finite--sample performance of our model in extensive simulation studies involving various types of functional data and traditional Euclidean scenarios. Finally, we demonstrate the practical relevance of our approach through a digital health application related to physical activity, aiming to provide personalized recommendations
Continuous Temporal Learning of Probability Distributions via Neural ODEs with Applications in Continuous Glucose Monitoring Data
May 13, 2025Modeling the continuous--time dynamics of probability distributions from time--dependent data samples is a fundamental problem in many fields, including digital health. The aim is to analyze how the distribution of a biomarker, such as glucose, evolves over time and how these changes may reflect the progression of chronic diseases such as diabetes. In this paper, we propose a novel probabilistic model based on a mixture of Gaussian distributions to capture how samples from a continuous-time stochastic process evolve over the time. To model potential distribution shifts over time, we introduce a time-dependent function parameterized by a Neural Ordinary Differential Equation (Neural ODE) and estimate it non--parametrically using the Maximum Mean Discrepancy (MMD). The proposed model is highly interpretable, detects subtle temporal shifts, and remains computationally efficient. Through simulation studies, we show that it performs competitively in terms of estimation accuracy against state-of-the-art, less interpretable methods such as normalized gradient--flows and non--parameteric kernel density estimators. Finally, we demonstrate the utility of our method on digital clinical--trial data, showing how the interventions alters the time-dependent distribution of glucose levels and enabling a rigorous comparison of control and treatment groups from novel mathematical and clinical perspectives.
Variable Selection Methods for Multivariate, Functional, and Complex Biomedical Data in the AI Age
Jan 12, 2025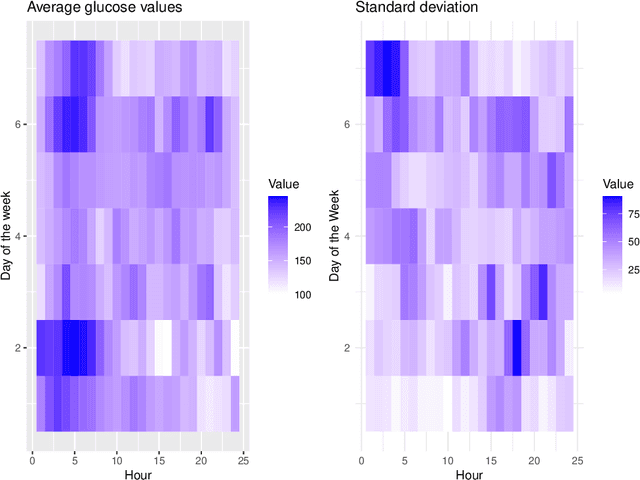



Many problems within personalized medicine and digital health rely on the analysis of continuous-time functional biomarkers and other complex data structures emerging from high-resolution patient monitoring. In this context, this work proposes new optimization-based variable selection methods for multivariate, functional, and even more general outcomes in metrics spaces based on best-subset selection. Our framework applies to several types of regression models, including linear, quantile, or non parametric additive models, and to a broad range of random responses, such as univariate, multivariate Euclidean data, functional, and even random graphs. Our analysis demonstrates that our proposed methodology outperforms state-of-the-art methods in accuracy and, especially, in speed-achieving several orders of magnitude improvement over competitors across various type of statistical responses as the case of mathematical functions. While our framework is general and is not designed for a specific regression and scientific problem, the article is self-contained and focuses on biomedical applications. In the clinical areas, serves as a valuable resource for professionals in biostatistics, statistics, and artificial intelligence interested in variable selection problem in this new technological AI-era.
Conformal Prediction in Dynamic Biological Systems
Sep 04, 2024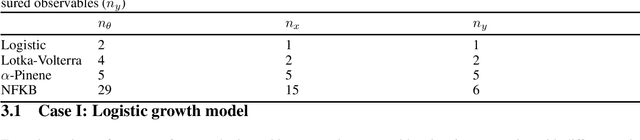


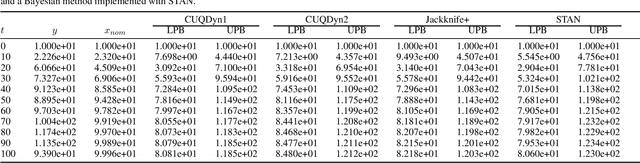
Uncertainty quantification (UQ) is the process of systematically determining and characterizing the degree of confidence in computational model predictions. In the context of systems biology, especially with dynamic models, UQ is crucial because it addresses the challenges posed by nonlinearity and parameter sensitivity, allowing us to properly understand and extrapolate the behavior of complex biological systems. Here, we focus on dynamic models represented by deterministic nonlinear ordinary differential equations. Many current UQ approaches in this field rely on Bayesian statistical methods. While powerful, these methods often require strong prior specifications and make parametric assumptions that may not always hold in biological systems. Additionally, these methods face challenges in domains where sample sizes are limited, and statistical inference becomes constrained, with computational speed being a bottleneck in large models of biological systems. As an alternative, we propose the use of conformal inference methods, introducing two novel algorithms that, in some instances, offer non-asymptotic guarantees, enhancing robustness and scalability across various applications. We demonstrate the efficacy of our proposed algorithms through several scenarios, highlighting their advantages over traditional Bayesian approaches. The proposed methods show promising results for diverse biological data structures and scenarios, offering a general framework to quantify uncertainty for dynamic models of biological systems.The software for the methodology and the reproduction of the results is available at https://zenodo.org/doi/10.5281/zenodo.13644870.
Uncertainty quantification in metric spaces
May 08, 2024This paper introduces a novel uncertainty quantification framework for regression models where the response takes values in a separable metric space, and the predictors are in a Euclidean space. The proposed algorithms can efficiently handle large datasets and are agnostic to the predictive base model used. Furthermore, the algorithms possess asymptotic consistency guarantees and, in some special homoscedastic cases, we provide non-asymptotic guarantees. To illustrate the effectiveness of the proposed uncertainty quantification framework, we use a linear regression model for metric responses (known as the global Fr\'echet model) in various clinical applications related to precision and digital medicine. The different clinical outcomes analyzed are represented as complex statistical objects, including multivariate Euclidean data, Laplacian graphs, and probability distributions.