 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Trace Distance: Quantum Statistical Metric between Measures through RKHS Density Operators
Jul 08, 2025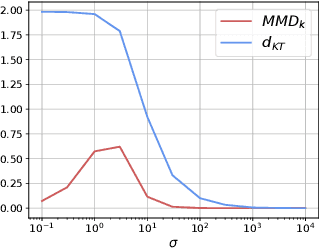

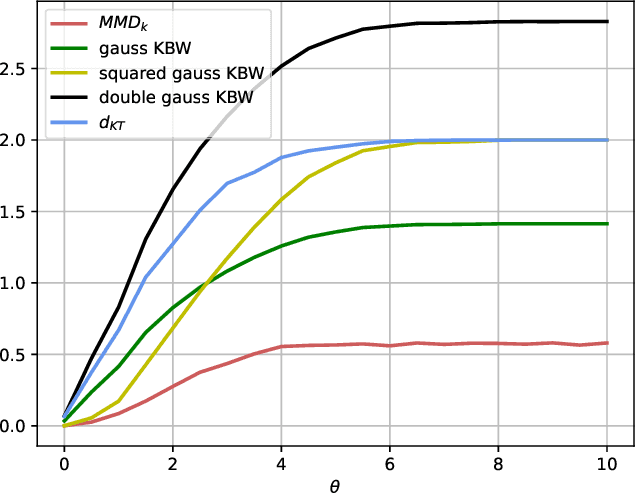
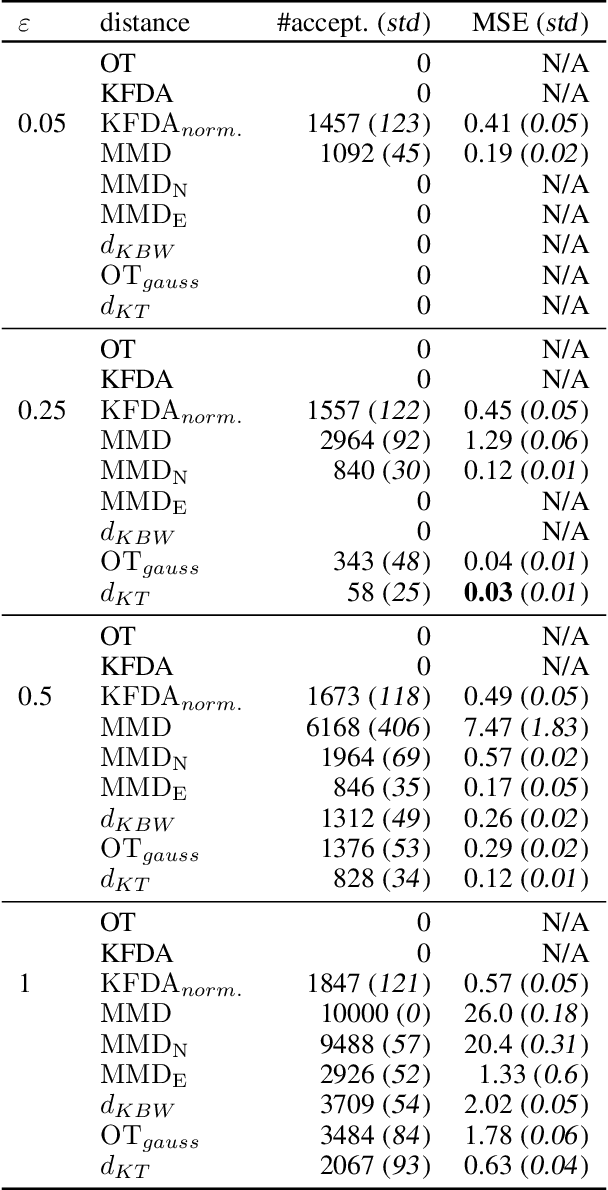
Distances between probability distributions are a key component of many statistical machine learning tasks, from two-sample testing to generative modeling, among others. We introduce a novel distance between measures that compares them through a Schatten norm of their kernel covariance operators. We show that this new distance is an integral probability metric that can be framed between a Maximum Mean Discrepancy (MMD) and a Wasserstein distance. In particular, we show that it avoids some pitfalls of MMD, by being more discriminative and robust to the choice of hyperparameters. Moreover, it benefits from some compelling properties of kernel methods, that can avoid the curse of dimensionality for their sample complexity. We provide an algorithm to compute the distance in practice by introducing an extension of kernel matrix for difference of distributions that could be of independent interest. Those advantages are illustrated by robust approximate Bayesian computation under contamination as well as particle flow simulations.
Model-Free Kernel Conformal Depth Measures Algorithm for Uncertainty Quantification in Regression Models in Separable Hilbert Spaces
Jun 10, 2025Depth measures are powerful tools for defining level sets in emerging, non--standard, and complex random objects such as high-dimensional multivariate data, functional data, and random graphs. Despite their favorable theoretical properties, the integration of depth measures into regression modeling to provide prediction regions remains a largely underexplored area of research. To address this gap, we propose a novel, model-free uncertainty quantification algorithm based on conditional depth measures--specifically, conditional kernel mean embeddings and an integrated depth measure. These new algorithms can be used to define prediction and tolerance regions when predictors and responses are defined in separable Hilbert spaces. The use of kernel mean embeddings ensures faster convergence rates in prediction region estimation. To enhance the practical utility of the algorithms with finite samples, we also introduce a conformal prediction variant that provides marginal, non-asymptotic guarantees for the derived prediction regions. Additionally, we establish both conditional and unconditional consistency results, as well as fast convergence rates in certain homoscedastic settings. We evaluate the finite--sample performance of our model in extensive simulation studies involving various types of functional data and traditional Euclidean scenarios. Finally, we demonstrate the practical relevance of our approach through a digital health application related to physical activity, aiming to provide personalized recommendations
AI-Driven Intrusion Detection Systems (IDS) on the ROAD dataset: A Comparative Analysis for automotive Controller Area Network (CAN)
Aug 30, 2024



The integration of digital devices in modern vehicles has revolutionized automotive technology, enhancing safety and the overall driving experience. The Controller Area Network (CAN) bus is a central system for managing in-vehicle communication between the electronic control units (ECUs). However, the CAN protocol poses security challenges due to inherent vulnerabilities, lacking encryption and authentication, which, combined with an expanding attack surface, necessitates robust security measures. In response to this challenge, numerous Intrusion Detection Systems (IDS) have been developed and deployed. Nonetheless, an open, comprehensive, and realistic dataset to test the effectiveness of such IDSs remains absent in the existing literature. This paper addresses this gap by considering the latest ROAD dataset, containing stealthy and sophisticated injections. The methodology involves dataset labelling and the implementation of both state-of-the-art deep learning models and traditional machine learning models to show the discrepancy in performance between the datasets most commonly used in the literature and the ROAD dataset, a more realistic alternative.
Restyling Unsupervised Concept Based Interpretable Networks with Generative Models
Jul 01, 2024



Developing inherently interpretable models for prediction has gained prominence in recent years. A subclass of these models, wherein the interpretable network relies on learning high-level concepts, are valued because of closeness of concept representations to human communication. However, the visualization and understanding of the learnt unsupervised dictionary of concepts encounters major limitations, specially for large-scale images. We propose here a novel method that relies on mapping the concept features to the latent space of a pretrained generative model. The use of a generative model enables high quality visualization, and naturally lays out an intuitive and interactive procedure for better interpretation of the learnt concepts. Furthermore, leveraging pretrained generative models has the additional advantage of making the training of the system more efficient. We quantitatively ascertain the efficacy of our method in terms of accuracy of the interpretable prediction network, fidelity of reconstruction, as well as faithfulness and consistency of learnt concepts. The experiments are conducted on multiple image recognition benchmarks for large-scale images. Project page available at https://jayneelparekh.github.io/VisCoIN_project_page/
Anomaly component analysis
Dec 26, 2023At the crossway of machine learning and data analysis, anomaly detection aims at identifying observations that exhibit abnormal behaviour. Be it measurement errors, disease development, severe weather, production quality default(s) (items) or failed equipment, financial frauds or crisis events, their on-time identification and isolation constitute an important task in almost any area of industry and science. While a substantial body of literature is devoted to detection of anomalies, little attention is payed to their explanation. This is the case mostly due to intrinsically non-supervised nature of the task and non-robustness of the exploratory methods like principal component analysis (PCA). We introduce a new statistical tool dedicated for exploratory analysis of abnormal observations using data depth as a score. Anomaly component analysis (shortly ACA) is a method that searches a low-dimensional data representation that best visualises and explains anomalies. This low-dimensional representation not only allows to distinguish groups of anomalies better than the methods of the state of the art, but as well provides a -- linear in variables and thus easily interpretable -- explanation for anomalies. In a comparative simulation and real-data study, ACA also proves advantageous for anomaly analysis with respect to methods present in the literature.
Fast kernel half-space depth for data with non-convex supports
Dec 21, 2023Data depth is a statistical function that generalizes order and quantiles to the multivariate setting and beyond, with applications spanning over descriptive and visual statistics, anomaly detection, testing, etc. The celebrated halfspace depth exploits data geometry via an optimization program to deliver properties of invariances, robustness, and non-parametricity. Nevertheless, it implicitly assumes convex data supports and requires exponential computational cost. To tackle distribution's multimodality, we extend the halfspace depth in a Reproducing Kernel Hilbert Space (RKHS). We show that the obtained depth is intuitive and establish its consistency with provable concentration bounds that allow for homogeneity testing. The proposed depth can be computed using manifold gradient making faster than halfspace depth by several orders of magnitude. The performance of our depth is demonstrated through numerical simulations as well as applications such as anomaly detection on real data and homogeneity testing.
Towards On-device Learning on the Edge: Ways to Select Neurons to Update under a Budget Constraint
Dec 08, 2023



In the realm of efficient on-device learning under extreme memory and computation constraints, a significant gap in successful approaches persists. Although considerable effort has been devoted to efficient inference, the main obstacle to efficient learning is the prohibitive cost of backpropagation. The resources required to compute gradients and update network parameters often exceed the limits of tightly constrained memory budgets. This paper challenges conventional wisdom and proposes a series of experiments that reveal the existence of superior sub-networks. Furthermore, we hint at the potential for substantial gains through a dynamic neuron selection strategy when fine-tuning a target task. Our efforts extend to the adaptation of a recent dynamic neuron selection strategy pioneered by Bragagnolo et al. (NEq), revealing its effectiveness in the most stringent scenarios. Our experiments demonstrate, in the average case, the superiority of a NEq-inspired approach over a random selection. This observation prompts a compelling avenue for further exploration in the area, highlighting the opportunity to design a new class of algorithms designed to facilitate parameter update selection. Our findings usher in a new era of possibilities in the field of on-device learning under extreme constraints and encourage the pursuit of innovative strategies for efficient, resource-friendly model fine-tuning.
Tailoring Mixup to Data using Kernel Warping functions
Nov 02, 2023



Data augmentation is an essential building block for learning efficient deep learning models. Among all augmentation techniques proposed so far, linear interpolation of training data points, also called mixup, has found to be effective for a large panel of applications. While the majority of works have focused on selecting the right points to mix, or applying complex non-linear interpolation, we are interested in mixing similar points more frequently and strongly than less similar ones. To this end, we propose to dynamically change the underlying distribution of interpolation coefficients through warping functions, depending on the similarity between data points to combine. We define an efficient and flexible framework to do so without losing in diversity. We provide extensive experiments for classification and regression tasks, showing that our proposed method improves both performance and calibration of models. Code available in https://github.com/ENSTA-U2IS/torch-uncertainty
Tackling Interpretability in Audio Classification Networks with Non-negative Matrix Factorization
May 11, 2023This paper tackles two major problem settings for interpretability of audio processing networks, post-hoc and by-design interpretation. For post-hoc interpretation, we aim to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. This is extended to present an inherently interpretable model with high performance. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, an interpreter is trained to generate a regularized intermediate embedding from hidden layers of a target network, learnt as time-activations of a pre-learnt NMF dictionary. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on a variety of classification tasks, including multi-label data for real-world audio and music.
Optimized preprocessing and Tiny ML for Attention State Classification
Mar 20, 2023



In this paper, we present a new approach to mental state classification from EEG signals by combining signal processing techniques and machine learning (ML) algorithms. We evaluate the performance of the proposed method on a dataset of EEG recordings collected during a cognitive load task and compared it to other state-of-the-art methods. The results show that the proposed method achieves high accuracy in classifying mental states and outperforms state-of-the-art methods in terms of classification accuracy and computational efficiency.