 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Fine-tuning Representation Shift for Multimodal LLMs Steering alignment
Jan 06, 2025Multimodal LLMs have reached remarkable levels of proficiency in understanding multimodal inputs, driving extensive research to develop increasingly powerful models. However, much less attention has been paid to understanding and explaining the underlying mechanisms of these models. Most existing explainability research examines these models only in their final states, overlooking the dynamic representational shifts that occur during training. In this work, we systematically analyze the evolution of hidden state representations to reveal how fine-tuning alters the internal structure of a model to specialize in new multimodal tasks. Using a concept-based approach, we map hidden states to interpretable visual and textual concepts, enabling us to trace changes in encoded concepts across modalities as training progresses. We also demonstrate the use of shift vectors to capture these concepts changes. These shift vectors allow us to recover fine-tuned concepts by shifting those in the original model. Finally, we explore the practical impact of our findings on model steering, showing that we can adjust multimodal LLMs behaviors without any training, such as modifying answer types, captions style, or biasing the model toward specific responses. Our work sheds light on how multimodal representations evolve through fine-tuning and offers a new perspective for interpreting model adaptation in multimodal tasks. The code for this project is publicly available at https://github.com/mshukor/xl-vlms.
One Wave to Explain Them All: A Unifying Perspective on Post-hoc Explainability
Oct 02, 2024Despite the growing use of deep neural networks in safety-critical decision-making, their inherent black-box nature hinders transparency and interpretability. Explainable AI (XAI) methods have thus emerged to understand a model's internal workings, and notably attribution methods also called saliency maps. Conventional attribution methods typically identify the locations -- the where -- of significant regions within an input. However, because they overlook the inherent structure of the input data, these methods often fail to interpret what these regions represent in terms of structural components (e.g., textures in images or transients in sounds). Furthermore, existing methods are usually tailored to a single data modality, limiting their generalizability. In this paper, we propose leveraging the wavelet domain as a robust mathematical foundation for attribution. Our approach, the Wavelet Attribution Method (WAM) extends the existing gradient-based feature attributions into the wavelet domain, providing a unified framework for explaining classifiers across images, audio, and 3D shapes. Empirical evaluations demonstrate that WAM matches or surpasses state-of-the-art methods across faithfulness metrics and models in image, audio, and 3D explainability. Finally, we show how our method explains not only the where -- the important parts of the input -- but also the what -- the relevant patterns in terms of structural components.
Restyling Unsupervised Concept Based Interpretable Networks with Generative Models
Jul 01, 2024



Developing inherently interpretable models for prediction has gained prominence in recent years. A subclass of these models, wherein the interpretable network relies on learning high-level concepts, are valued because of closeness of concept representations to human communication. However, the visualization and understanding of the learnt unsupervised dictionary of concepts encounters major limitations, specially for large-scale images. We propose here a novel method that relies on mapping the concept features to the latent space of a pretrained generative model. The use of a generative model enables high quality visualization, and naturally lays out an intuitive and interactive procedure for better interpretation of the learnt concepts. Furthermore, leveraging pretrained generative models has the additional advantage of making the training of the system more efficient. We quantitatively ascertain the efficacy of our method in terms of accuracy of the interpretable prediction network, fidelity of reconstruction, as well as faithfulness and consistency of learnt concepts. The experiments are conducted on multiple image recognition benchmarks for large-scale images. Project page available at https://jayneelparekh.github.io/VisCoIN_project_page/
A Concept-Based Explainability Framework for Large Multimodal Models
Jun 12, 2024Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as "multi-modal concepts". We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually. We will publicly release our code.
Tackling Interpretability in Audio Classification Networks with Non-negative Matrix Factorization
May 11, 2023This paper tackles two major problem settings for interpretability of audio processing networks, post-hoc and by-design interpretation. For post-hoc interpretation, we aim to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. This is extended to present an inherently interpretable model with high performance. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, an interpreter is trained to generate a regularized intermediate embedding from hidden layers of a target network, learnt as time-activations of a pre-learnt NMF dictionary. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on a variety of classification tasks, including multi-label data for real-world audio and music.
Listen to Interpret: Post-hoc Interpretability for Audio Networks with NMF
Feb 23, 2022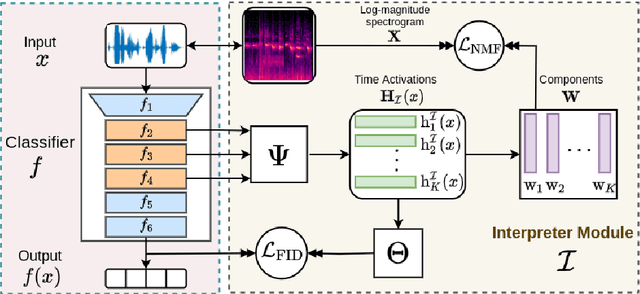
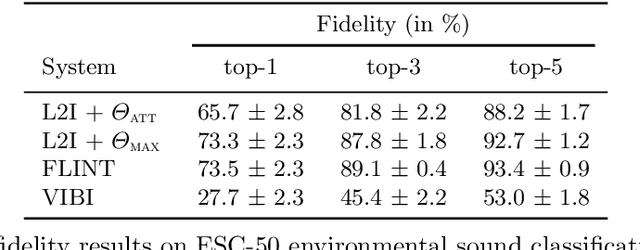

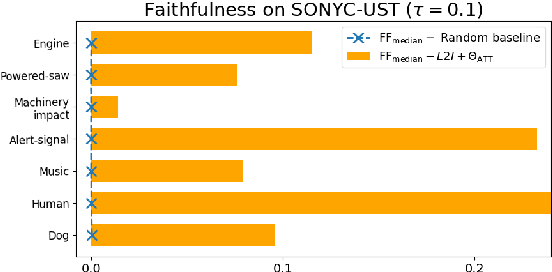
This paper tackles post-hoc interpretability for audio processing networks. Our goal is to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, a carefully regularized interpreter module is trained to take hidden layer representations of the targeted network as input and produce time activations of pre-learnt NMF components as intermediate outputs. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on popular benchmarks, including a real-world multi-label classification task.
A Framework to Learn with Interpretation
Oct 19, 2020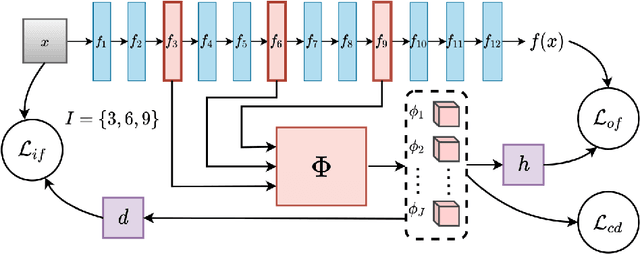
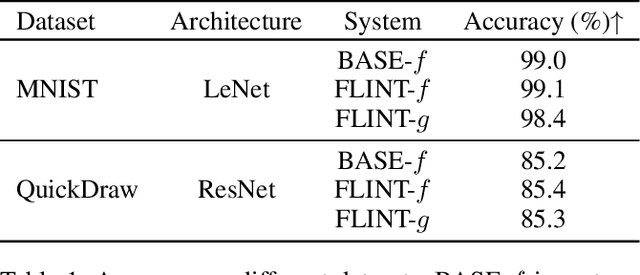


With increasingly widespread use of deep neural networks in critical decision-making applications, interpretability of these models is becoming imperative. We consider the problem of jointly learning a predictive model and its associated interpretation model. The task of the interpreter is to provide both local and global interpretability about the predictive model in terms of human-understandable high level attribute functions, without any loss of accuracy. This is achieved by a dedicated architecture and well chosen regularization penalties. We seek for a small-size dictionary of attribute functions that take as inputs the outputs of selected hidden layers and whose outputs feed a linear classifier. We impose a high level of conciseness by constraining the activation of a very few attributes for a given input with a real-entropy-based criterion while enforcing fidelity to both inputs and outputs of the predictive model. A major advantage of simultaneous learning is that the predictive neural network benefits from the interpretability constraint as well. We also develop a more detailed pipeline based on some common and novel simple tools to develop understanding about the learnt features. We show on two datasets, MNIST and QuickDraw, their relevance for both global and local interpretability.
Speech-to-Singing Conversion in an Encoder-Decoder Framework
Feb 16, 2020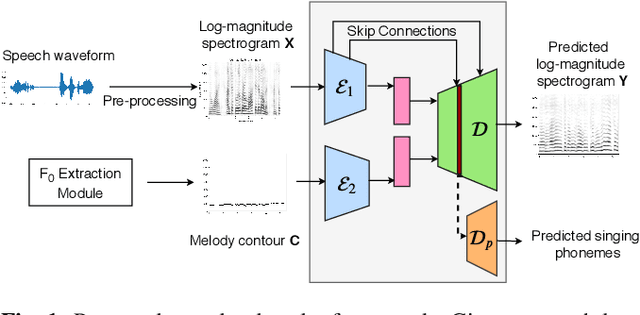
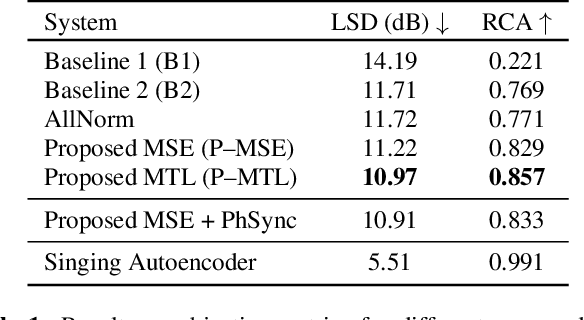
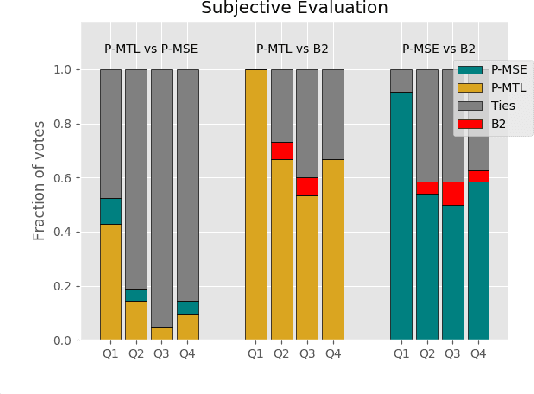
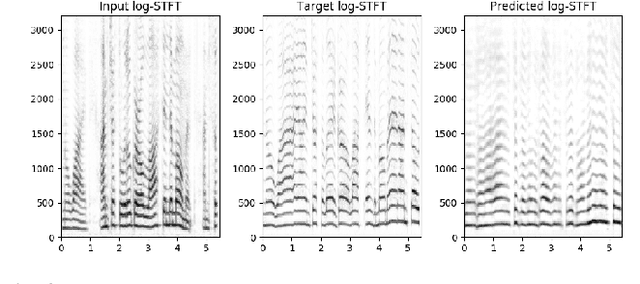
In this paper our goal is to convert a set of spoken lines into sung ones. Unlike previous signal processing based methods, we take a learning based approach to the problem. This allows us to automatically model various aspects of this transformation, thus overcoming dependence on specific inputs such as high quality singing templates or phoneme-score synchronization information. Specifically, we propose an encoder--decoder framework for our task. Given time-frequency representations of speech and a target melody contour, we learn encodings that enable us to synthesize singing that preserves the linguistic content and timbre of the speaker while adhering to the target melody. We also propose a multi-task learning based objective to improve lyric intelligibility. We present a quantitative and qualitative analysis of our framework.