 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
May 06, 2026Neural representations carry rich geometric structure; but does that structure causally shape behavior? To address this question, we intervene along paths through activation space defined by different geometries, and measure the behavioral trajectories they induce. In particular, we test whether interventions that respect the geometry of activation space will yield behaviors close to those the model exhibits naturally. Concretely, we first fit an activation manifold $M_h$ to representations and a behavior manifold $M_y$ to output probability distributions. We then test the link $M_h \leftrightarrow M_y$ via interventions: we find that steering along $M_h$, which we term manifold steering, yields behavioral trajectories that follow $M_y$, while linear steering -- which assumes a Euclidean geometry -- cuts through off-manifold regions and hence produces unnatural outputs. Moreover, optimizing interventions in activation space to produce paths along $M_y$ recovers activation trajectories that trace the curvature of $M_h$. We demonstrate this bidirectional relationship between the geometry of representation and behavior across tasks and modalities. In language models, we use reasoning tasks with cyclic and sequential geometries as well as in-context learning tasks with more complex graph geometries. In a video world model, we use a task with geometry corresponding to physical dynamics. Overall, our work shows that geometry in neural representation is not merely incidental, but is in fact the proper object for enabling principled control via intervention on internals. This recasts the core problem of steering from finding the right direction to finding the right geometry.
Cross-Modal Redundancy and the Geometry of Vision-Language Embeddings
Feb 05, 2026Vision-language models (VLMs) align images and text with remarkable success, yet the geometry of their shared embedding space remains poorly understood. To probe this geometry, we begin from the Iso-Energy Assumption, which exploits cross-modal redundancy: a concept that is truly shared should exhibit the same average energy across modalities. We operationalize this assumption with an Aligned Sparse Autoencoder (SAE) that encourages energy consistency during training while preserving reconstruction. We find that this inductive bias changes the SAE solution without harming reconstruction, giving us a representation that serves as a tool for geometric analysis. Sanity checks on controlled data with known ground truth confirm that alignment improves when Iso-Energy holds and remains neutral when it does not. Applied to foundational VLMs, our framework reveals a clear structure with practical consequences: (i) sparse bimodal atoms carry the entire cross-modal alignment signal; (ii) unimodal atoms act as modality-specific biases and fully explain the modality gap; (iii) removing unimodal atoms collapses the gap without harming performance; (iv) restricting vector arithmetic to the bimodal subspace yields in-distribution edits and improved retrieval. These findings suggest that the right inductive bias can both preserve model fidelity and render the latent geometry interpretable and actionable.
Interpreting Physics in Video World Models
Feb 04, 2026A long-standing question in physical reasoning is whether video-based models need to rely on factorized representations of physical variables in order to make physically accurate predictions, or whether they can implicitly represent such variables in a task-specific, distributed manner. While modern video world models achieve strong performance on intuitive physics benchmarks, it remains unclear which of these representational regimes they implement internally. Here, we present the first interpretability study to directly examine physical representations inside large-scale video encoders. Using layerwise probing, subspace geometry, patch-level decoding, and targeted attention ablations, we characterize where physical information becomes accessible and how it is organized within encoder-based video transformers. Across architectures, we identify a sharp intermediate-depth transition -- which we call the Physics Emergence Zone -- at which physical variables become accessible. Physics-related representations peak shortly after this transition and degrade toward the output layers. Decomposing motion into explicit variables, we find that scalar quantities such as speed and acceleration are available from early layers onwards, whereas motion direction becomes accessible only at the Physics Emergence Zone. Notably, we find that direction is encoded through a high-dimensional population structure with circular geometry, requiring coordinated multi-feature intervention to control. These findings suggest that modern video models do not use factorized representations of physical variables like a classical physics engine. Instead, they use a distributed representation that is nonetheless sufficient for making physical predictions.
Block-Recurrent Dynamics in Vision Transformers
Dec 23, 2025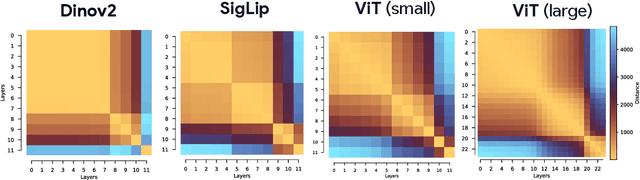
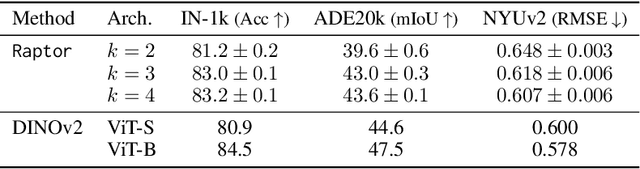

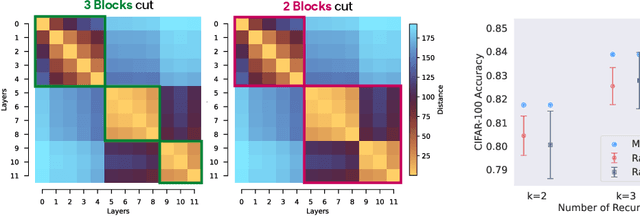
As Vision Transformers (ViTs) become standard vision backbones, a mechanistic account of their computational phenomenology is essential. Despite architectural cues that hint at dynamical structure, there is no settled framework that interprets Transformer depth as a well-characterized flow. In this work, we introduce the Block-Recurrent Hypothesis (BRH), arguing that trained ViTs admit a block-recurrent depth structure such that the computation of the original $L$ blocks can be accurately rewritten using only $k \ll L$ distinct blocks applied recurrently. Across diverse ViTs, between-layer representational similarity matrices suggest few contiguous phases. To determine whether these phases reflect genuinely reusable computation, we train block-recurrent surrogates of pretrained ViTs: Recurrent Approximations to Phase-structured TransfORmers (Raptor). In small-scale, we demonstrate that stochastic depth and training promote recurrent structure and subsequently correlate with our ability to accurately fit Raptor. We then provide an empirical existence proof for BRH by training a Raptor model to recover $96\%$ of DINOv2 ImageNet-1k linear probe accuracy in only 2 blocks at equivalent computational cost. Finally, we leverage our hypothesis to develop a program of Dynamical Interpretability. We find i) directional convergence into class-dependent angular basins with self-correcting trajectories under small perturbations, ii) token-specific dynamics, where cls executes sharp late reorientations while patch tokens exhibit strong late-stage coherence toward their mean direction, and iii) a collapse to low rank updates in late depth, consistent with convergence to low-dimensional attractors. Altogether, we find a compact recurrent program emerges along ViT depth, pointing to a low-complexity normative solution that enables these models to be studied through principled dynamical systems analysis.
Back to the Baseline: Examining Baseline Effects on Explainability Metrics
Dec 12, 2025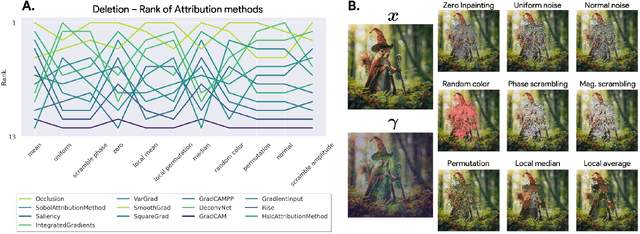
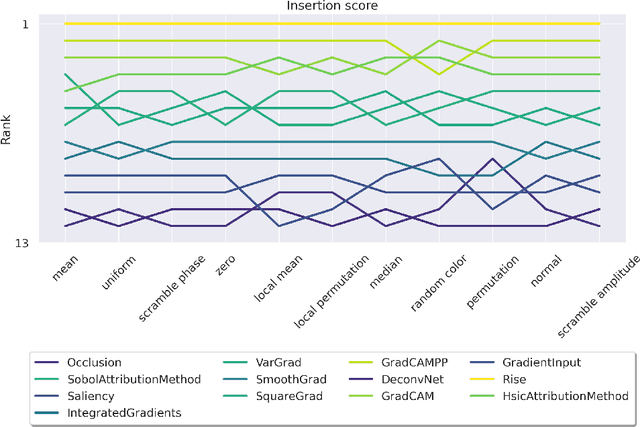
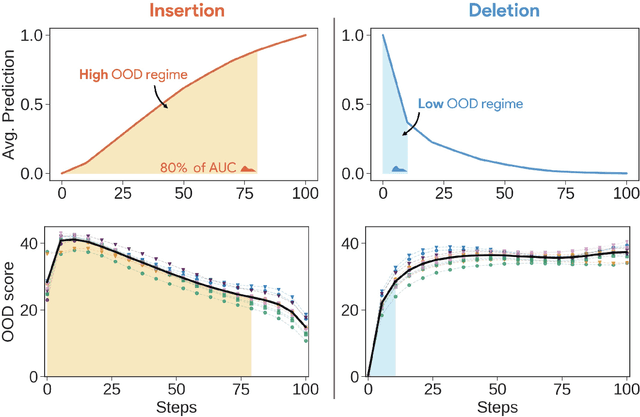
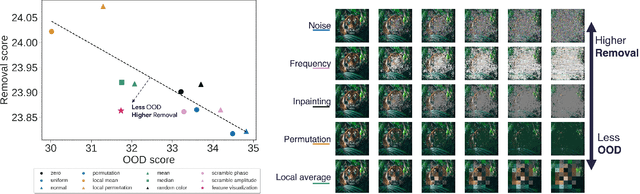
Attribution methods are among the most prevalent techniques in Explainable Artificial Intelligence (XAI) and are usually evaluated and compared using Fidelity metrics, with Insertion and Deletion being the most popular. These metrics rely on a baseline function to alter the pixels of the input image that the attribution map deems most important. In this work, we highlight a critical problem with these metrics: the choice of a given baseline will inevitably favour certain attribution methods over others. More concerningly, even a simple linear model with commonly used baselines contradicts itself by designating different optimal methods. A question then arises: which baseline should we use? We propose to study this problem through two desirable properties of a baseline: (i) that it removes information and (ii) that it does not produce overly out-of-distribution (OOD) images. We first show that none of the tested baselines satisfy both criteria, and there appears to be a trade-off among current baselines: either they remove information or they produce a sequence of OOD images. Finally, we introduce a novel baseline by leveraging recent work in feature visualisation to artificially produce a model-dependent baseline that removes information without being overly OOD, thus improving on the trade-off when compared to other existing baselines. Our code is available at https://github.com/deel-ai-papers/Back-to-the-Baseline
A Geometric Unification of Concept Learning with Concept Cones
Dec 08, 2025Two traditions of interpretability have evolved side by side but seldom spoken to each other: Concept Bottleneck Models (CBMs), which prescribe what a concept should be, and Sparse Autoencoders (SAEs), which discover what concepts emerge. While CBMs use supervision to align activations with human-labeled concepts, SAEs rely on sparse coding to uncover emergent ones. We show that both paradigms instantiate the same geometric structure: each learns a set of linear directions in activation space whose nonnegative combinations form a concept cone. Supervised and unsupervised methods thus differ not in kind but in how they select this cone. Building on this view, we propose an operational bridge between the two paradigms. CBMs provide human-defined reference geometries, while SAEs can be evaluated by how well their learned cones approximate or contain those of CBMs. This containment framework yields quantitative metrics linking inductive biases -- such as SAE type, sparsity, or expansion ratio -- to emergence of plausible\footnote{We adopt the terminology of \citet{jacovi2020towards}, who distinguish between faithful explanations (accurately reflecting model computations) and plausible explanations (aligning with human intuition and domain knowledge). CBM concepts are plausible by construction -- selected or annotated by humans -- though not necessarily faithful to the true latent factors that organise the data manifold.} concepts. Using these metrics, we uncover a ``sweet spot'' in both sparsity and expansion factor that maximizes both geometric and semantic alignment with CBM concepts. Overall, our work unifies supervised and unsupervised concept discovery through a shared geometric framework, providing principled metrics to measure SAE progress and assess how well discovered concept align with plausible human concepts.
Uncovering Conceptual Blindspots in Generative Image Models Using Sparse Autoencoders
Jun 24, 2025Despite their impressive performance, generative image models trained on large-scale datasets frequently fail to produce images with seemingly simple concepts -- e.g., human hands or objects appearing in groups of four -- that are reasonably expected to appear in the training data. These failure modes have largely been documented anecdotally, leaving open the question of whether they reflect idiosyncratic anomalies or more structural limitations of these models. To address this, we introduce a systematic approach for identifying and characterizing "conceptual blindspots" -- concepts present in the training data but absent or misrepresented in a model's generations. Our method leverages sparse autoencoders (SAEs) to extract interpretable concept embeddings, enabling a quantitative comparison of concept prevalence between real and generated images. We train an archetypal SAE (RA-SAE) on DINOv2 features with 32,000 concepts -- the largest such SAE to date -- enabling fine-grained analysis of conceptual disparities. Applied to four popular generative models (Stable Diffusion 1.5/2.1, PixArt, and Kandinsky), our approach reveals specific suppressed blindspots (e.g., bird feeders, DVD discs, and whitespaces on documents) and exaggerated blindspots (e.g., wood background texture and palm trees). At the individual datapoint level, we further isolate memorization artifacts -- instances where models reproduce highly specific visual templates seen during training. Overall, we propose a theoretically grounded framework for systematically identifying conceptual blindspots in generative models by assessing their conceptual fidelity with respect to the underlying data-generating process.
Evaluating Sparse Autoencoders: From Shallow Design to Matching Pursuit
Jun 05, 2025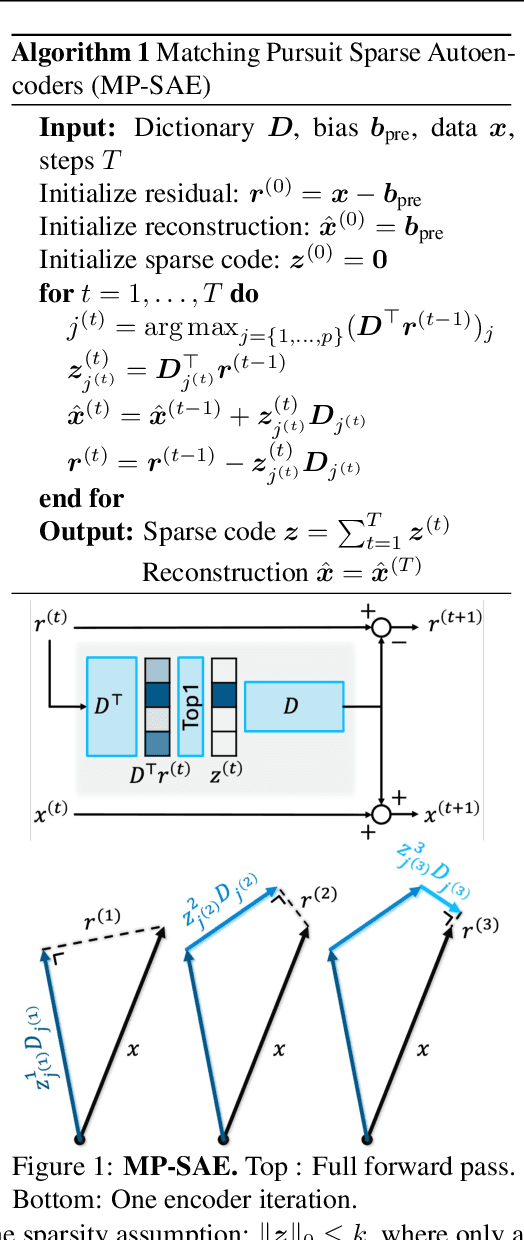
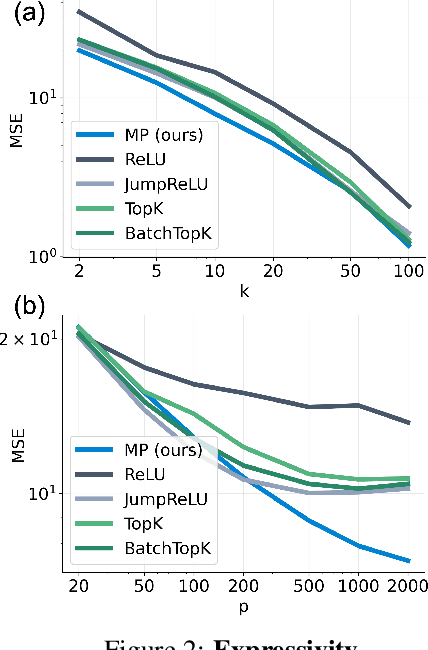

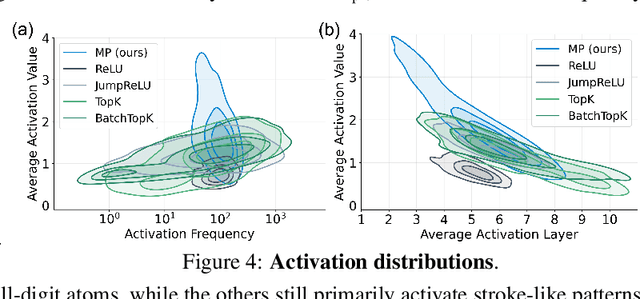
Sparse autoencoders (SAEs) have recently become central tools for interpretability, leveraging dictionary learning principles to extract sparse, interpretable features from neural representations whose underlying structure is typically unknown. This paper evaluates SAEs in a controlled setting using MNIST, which reveals that current shallow architectures implicitly rely on a quasi-orthogonality assumption that limits the ability to extract correlated features. To move beyond this, we introduce a multi-iteration SAE by unrolling Matching Pursuit (MP-SAE), enabling the residual-guided extraction of correlated features that arise in hierarchical settings such as handwritten digit generation while guaranteeing monotonic improvement of the reconstruction as more atoms are selected.
Interpreting the Linear Structure of Vision-language Model Embedding Spaces
Apr 16, 2025



Vision-language models encode images and text in a joint space, minimizing the distance between corresponding image and text pairs. How are language and images organized in this joint space, and how do the models encode meaning and modality? To investigate this, we train and release sparse autoencoders (SAEs) on the embedding spaces of four vision-language models (CLIP, SigLIP, SigLIP2, and AIMv2). SAEs approximate model embeddings as sparse linear combinations of learned directions, or "concepts". We find that, compared to other methods of linear feature learning, SAEs are better at reconstructing the real embeddings, while also able to retain the most sparsity. Retraining SAEs with different seeds or different data diet leads to two findings: the rare, specific concepts captured by the SAEs are liable to change drastically, but we also show that the key commonly-activating concepts extracted by SAEs are remarkably stable across runs. Interestingly, while most concepts are strongly unimodal in activation, we find they are not merely encoding modality per se. Many lie close to - but not entirely within - the subspace defining modality, suggesting that they encode cross-modal semantics despite their unimodal usage. To quantify this bridging behavior, we introduce the Bridge Score, a metric that identifies concept pairs which are both co-activated across aligned image-text inputs and geometrically aligned in the shared space. This reveals that even unimodal concepts can collaborate to support cross-modal integration. We release interactive demos of the SAEs for all models, allowing researchers to explore the organization of the concept spaces. Overall, our findings uncover a sparse linear structure within VLM embedding spaces that is shaped by modality, yet stitched together through latent bridges-offering new insight into how multimodal meaning is constructed.
Projecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometry
Mar 03, 2025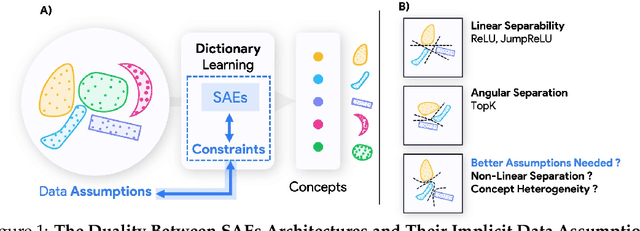
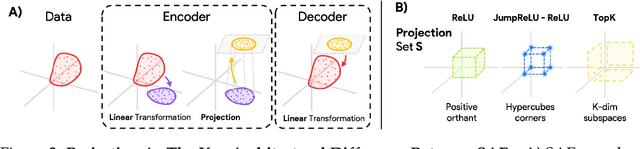
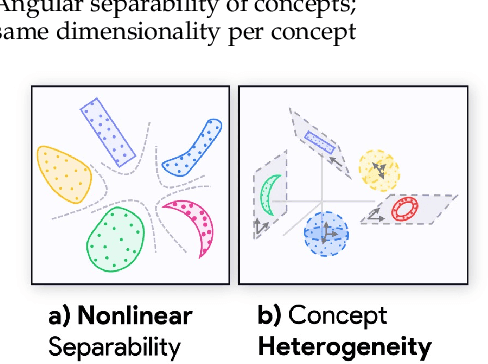

Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from their representations. However, do SAEs truly uncover all concepts a model relies on, or are they inherently biased toward certain kinds of concepts? We introduce a unified framework that recasts SAEs as solutions to a bilevel optimization problem, revealing a fundamental challenge: each SAE imposes structural assumptions about how concepts are encoded in model representations, which in turn shapes what it can and cannot detect. This means different SAEs are not interchangeable -- switching architectures can expose entirely new concepts or obscure existing ones. To systematically probe this effect, we evaluate SAEs across a spectrum of settings: from controlled toy models that isolate key variables, to semi-synthetic experiments on real model activations and finally to large-scale, naturalistic datasets. Across this progression, we examine two fundamental properties that real-world concepts often exhibit: heterogeneity in intrinsic dimensionality (some concepts are inherently low-dimensional, others are not) and nonlinear separability. We show that SAEs fail to recover concepts when these properties are ignored, and we design a new SAE that explicitly incorporates both, enabling the discovery of previously hidden concepts and reinforcing our theoretical insights. Our findings challenge the idea of a universal SAE and underscores the need for architecture-specific choices in model interpretability. Overall, we argue an SAE does not just reveal concepts -- it determines what can be seen at all.