 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting the Linear Structure of Vision-language Model Embedding Spaces
Apr 16, 2025



Vision-language models encode images and text in a joint space, minimizing the distance between corresponding image and text pairs. How are language and images organized in this joint space, and how do the models encode meaning and modality? To investigate this, we train and release sparse autoencoders (SAEs) on the embedding spaces of four vision-language models (CLIP, SigLIP, SigLIP2, and AIMv2). SAEs approximate model embeddings as sparse linear combinations of learned directions, or "concepts". We find that, compared to other methods of linear feature learning, SAEs are better at reconstructing the real embeddings, while also able to retain the most sparsity. Retraining SAEs with different seeds or different data diet leads to two findings: the rare, specific concepts captured by the SAEs are liable to change drastically, but we also show that the key commonly-activating concepts extracted by SAEs are remarkably stable across runs. Interestingly, while most concepts are strongly unimodal in activation, we find they are not merely encoding modality per se. Many lie close to - but not entirely within - the subspace defining modality, suggesting that they encode cross-modal semantics despite their unimodal usage. To quantify this bridging behavior, we introduce the Bridge Score, a metric that identifies concept pairs which are both co-activated across aligned image-text inputs and geometrically aligned in the shared space. This reveals that even unimodal concepts can collaborate to support cross-modal integration. We release interactive demos of the SAEs for all models, allowing researchers to explore the organization of the concept spaces. Overall, our findings uncover a sparse linear structure within VLM embedding spaces that is shaped by modality, yet stitched together through latent bridges-offering new insight into how multimodal meaning is constructed.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Feb 18, 2025Sparse Autoencoders (SAEs) have emerged as a powerful framework for machine learning interpretability, enabling the unsupervised decomposition of model representations into a dictionary of abstract, human-interpretable concepts. However, we reveal a fundamental limitation: existing SAEs exhibit severe instability, as identical models trained on similar datasets can produce sharply different dictionaries, undermining their reliability as an interpretability tool. To address this issue, we draw inspiration from the Archetypal Analysis framework introduced by Cutler & Breiman (1994) and present Archetypal SAEs (A-SAE), wherein dictionary atoms are constrained to the convex hull of data. This geometric anchoring significantly enhances the stability of inferred dictionaries, and their mildly relaxed variants RA-SAEs further match state-of-the-art reconstruction abilities. To rigorously assess dictionary quality learned by SAEs, we introduce two new benchmarks that test (i) plausibility, if dictionaries recover "true" classification directions and (ii) identifiability, if dictionaries disentangle synthetic concept mixtures. Across all evaluations, RA-SAEs consistently yield more structured representations while uncovering novel, semantically meaningful concepts in large-scale vision models.
Mission: Impossible Language Models
Jan 12, 2024



Chomsky and others have very directly claimed that large language models (LLMs) are equally capable of learning languages that are possible and impossible for humans to learn. However, there is very little published experimental evidence to support such a claim. Here, we develop a set of synthetic impossible languages of differing complexity, each designed by systematically altering English data with unnatural word orders and grammar rules. These languages lie on an impossibility continuum: at one end are languages that are inherently impossible, such as random and irreversible shuffles of English words, and on the other, languages that may not be intuitively impossible but are often considered so in linguistics, particularly those with rules based on counting word positions. We report on a wide range of evaluations to assess the capacity of GPT-2 small models to learn these uncontroversially impossible languages, and crucially, we perform these assessments at various stages throughout training to compare the learning process for each language. Our core finding is that GPT-2 struggles to learn impossible languages when compared to English as a control, challenging the core claim. More importantly, we hope our approach opens up a productive line of inquiry in which different LLM architectures are tested on a variety of impossible languages in an effort to learn more about how LLMs can be used as tools for these cognitive and typological investigations.
Separating the Wheat from the Chaff with BREAD: An open-source benchmark and metrics to detect redundancy in text
Nov 11, 2023Data quality is a problem that perpetually resurfaces throughout the field of NLP, regardless of task, domain, or architecture, and remains especially severe for lower-resource languages. A typical and insidious issue, affecting both training data and model output, is data that is repetitive and dominated by linguistically uninteresting boilerplate, such as price catalogs or computer-generated log files. Though this problem permeates many web-scraped corpora, there has yet to be a benchmark to test against, or a systematic study to find simple metrics that generalize across languages and agree with human judgements of data quality. In the present work, we create and release BREAD, a human-labeled benchmark on repetitive boilerplate vs. plausible linguistic content, spanning 360 languages. We release several baseline CRED (Character REDundancy) scores along with it, and evaluate their effectiveness on BREAD. We hope that the community will use this resource to develop better filtering methods, and that our reference implementations of CRED scores can become standard corpus evaluation tools, driving the development of cleaner language modeling corpora, especially in low-resource languages.
Pretrain on just structure: Understanding linguistic inductive biases using transfer learning
Apr 25, 2023



Both humans and transformer language models are able to learn language without explicit structural supervision. What inductive learning biases make this learning possible? In this study, we examine the effect of different inductive learning biases by predisposing language models with structural biases through pretraining on artificial structured data, and then evaluating by fine-tuning on English. Our experimental setup gives us the ability to actively control the inductive bias of language models. With our experiments, we investigate the comparative success of three types of inductive bias: 1) an inductive bias for recursive, hierarchical processing 2) an inductive bias for unrestricted token-token dependencies that can't be modeled by context-free grammars, and 3) an inductive bias for a Zipfian power-law vocabulary distribution. We show that complex token-token interactions form the best inductive biases, and that this is strongest in the non-context-free case. We also show that a Zipfian vocabulary distribution forms a good inductive bias independently from grammatical structure. Our study leverages the capabilities of transformer models to run controlled language learning experiments that are not possible to run in humans, and surfaces hypotheses about the structures that facilitate language learning in both humans and machines.
Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models
Oct 11, 2022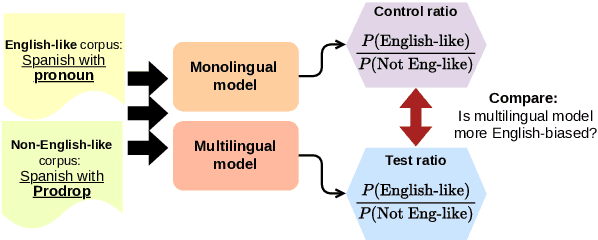

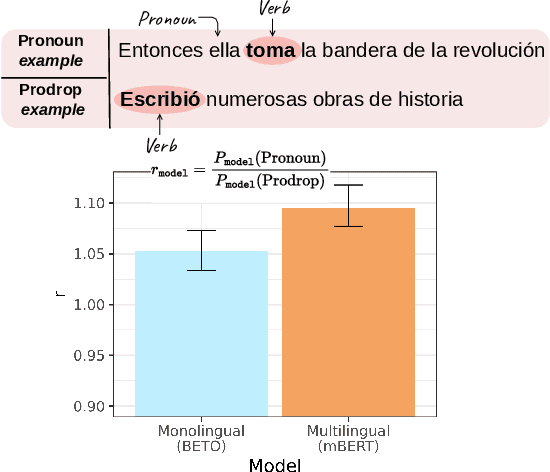
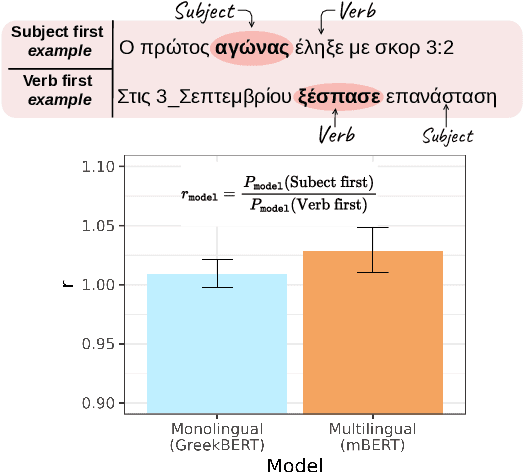
While multilingual language models can improve NLP performance on low-resource languages by leveraging higher-resource languages, they also reduce average performance on all languages (the 'curse of multilinguality'). Here we show another problem with multilingual models: grammatical structures in higher-resource languages bleed into lower-resource languages, a phenomenon we call grammatical structure bias. We show this bias via a novel method for comparing the fluency of multilingual models to the fluency of monolingual Spanish and Greek models: testing their preference for two carefully-chosen variable grammatical structures (optional pronoun-drop in Spanish and optional Subject-Verb ordering in Greek). We find that multilingual BERT is biased toward the English-like setting (explicit pronouns and Subject-Verb-Object ordering) as compared to our monolingual control. With our case studies, we hope to bring to light the fine-grained ways in which dominant languages can affect and bias multilingual performance, and encourage more linguistically-aware fluency evaluation.
When classifying grammatical role, BERT doesn't care about word order... except when it matters
Mar 11, 2022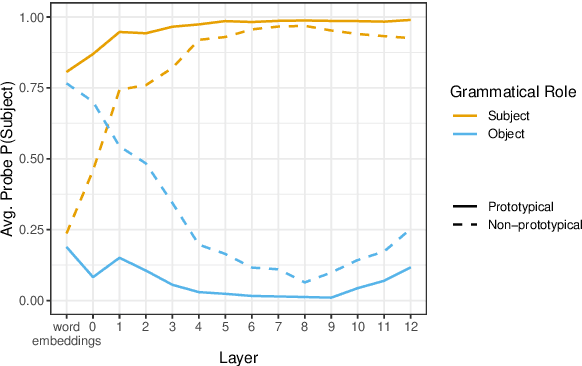
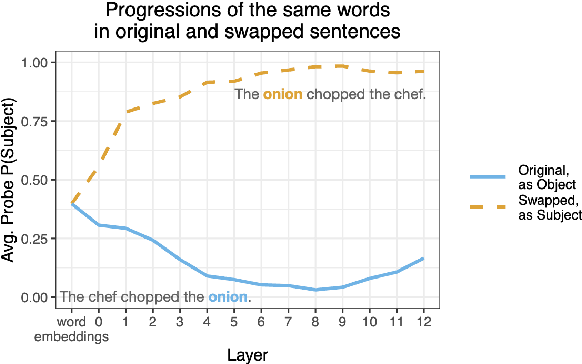

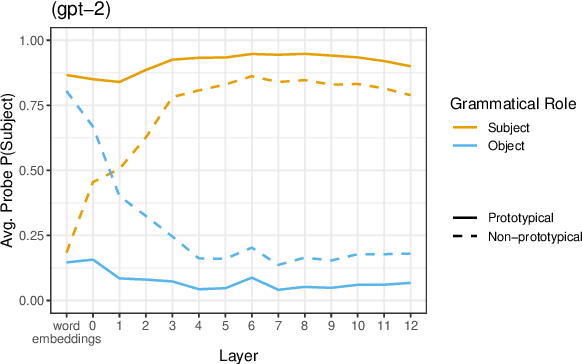
Because meaning can often be inferred from lexical semantics alone, word order is often a redundant cue in natural language. For example, the words chopped, chef, and onion are more likely used to convey "The chef chopped the onion," not "The onion chopped the chef." Recent work has shown large language models to be surprisingly word order invariant, but crucially has largely considered natural prototypical inputs, where compositional meaning mostly matches lexical expectations. To overcome this confound, we probe grammatical role representation in English BERT and GPT-2, on instances where lexical expectations are not sufficient, and word order knowledge is necessary for correct classification. Such non-prototypical instances are naturally occurring English sentences with inanimate subjects or animate objects, or sentences where we systematically swap the arguments to make sentences like "The onion chopped the chef". We find that, while early layer embeddings are largely lexical, word order is in fact crucial in defining the later-layer representations of words in semantically non-prototypical positions. Our experiments isolate the effect of word order on the contextualization process, and highlight how models use context in the uncommon, but critical, instances where it matters.
Oolong: Investigating What Makes Crosslingual Transfer Hard with Controlled Studies
Feb 24, 2022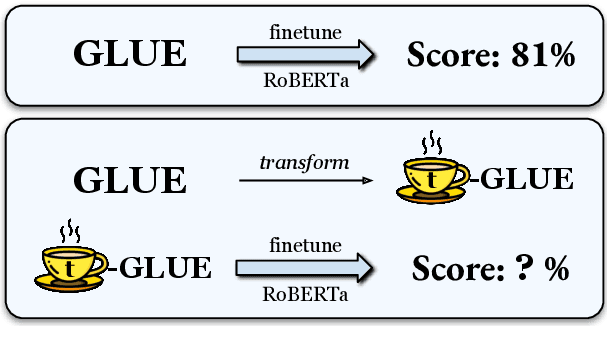

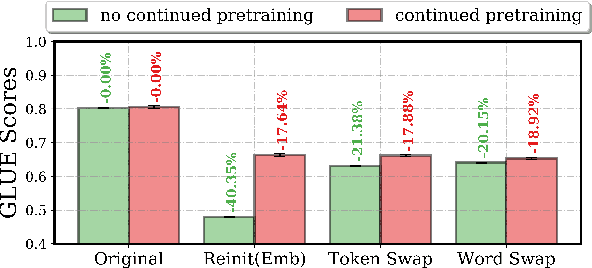
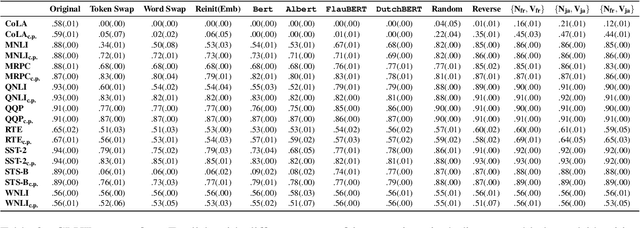
Little is known about what makes cross-lingual transfer hard, since factors like tokenization, morphology, and syntax all change at once between languages. To disentangle the impact of these factors, we propose a set of controlled transfer studies: we systematically transform GLUE tasks to alter different factors one at a time, then measure the resulting drops in a pretrained model's downstream performance. In contrast to prior work suggesting little effect from syntax on knowledge transfer, we find significant impacts from syntactic shifts (3-6% drop), though models quickly adapt with continued pretraining on a small dataset. However, we find that by far the most impactful factor for crosslingual transfer is the challenge of aligning the new embeddings with the existing transformer layers (18% drop), with little additional effect from switching tokenizers (<2% drop) or word morphologies (<2% drop). Moreover, continued pretraining with a small dataset is not very effective at closing this gap - suggesting that new directions are needed for solving this problem.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
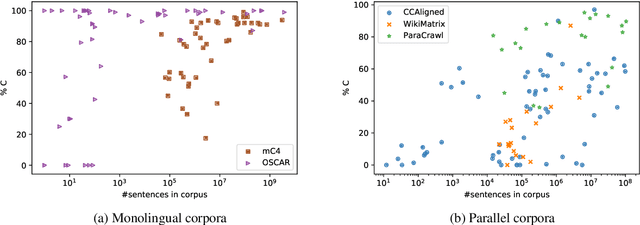

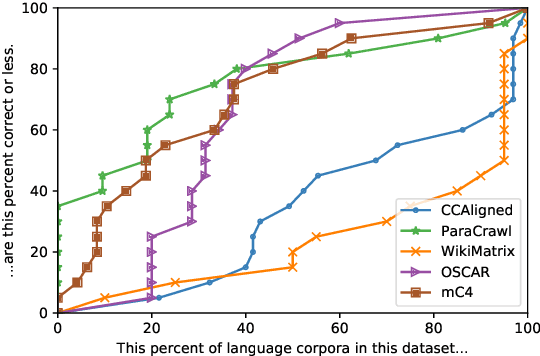
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.