 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can effectively convince people to believe conspiracies
Jan 08, 2026Large language models (LLMs) have been shown to be persuasive across a variety of context. But it remains unclear whether this persuasive power advantages truth over falsehood, or if LLMs can promote misbeliefs just as easily as refuting them. Here, we investigate this question across three pre-registered experiments in which participants (N = 2,724 Americans) discussed a conspiracy theory they were uncertain about with GPT-4o, and the model was instructed to either argue against ("debunking") or for ("bunking") that conspiracy. When using a "jailbroken" GPT-4o variant with guardrails removed, the AI was as effective at increasing conspiracy belief as decreasing it. Concerningly, the bunking AI was rated more positively, and increased trust in AI, more than the debunking AI. Surprisingly, we found that using standard GPT-4o produced very similar effects, such that the guardrails imposed by OpenAI did little to revent the LLM from promoting conspiracy beliefs. Encouragingly, however, a corrective conversation reversed these newly induced conspiracy beliefs, and simply prompting GPT-4o to only use accurate information dramatically reduced its ability to increase conspiracy beliefs. Our findings demonstrate that LLMs possess potent abilities to promote both truth and falsehood, but that potential solutions may exist to help mitigate this risk.
Emergent Persuasion: Will LLMs Persuade Without Being Prompted?
Dec 20, 2025With the wide-scale adoption of conversational AI systems, AI are now able to exert unprecedented influence on human opinion and beliefs. Recent work has shown that many Large Language Models (LLMs) comply with requests to persuade users into harmful beliefs or actions when prompted and that model persuasiveness increases with model scale. However, this prior work looked at persuasion from the threat model of $\textit{misuse}$ (i.e., a bad actor asking an LLM to persuade). In this paper, we instead aim to answer the following question: Under what circumstances would models persuade $\textit{without being explicitly prompted}$, which would shape how concerned we should be about such emergent persuasion risks. To achieve this, we study unprompted persuasion under two scenarios: (i) when the model is steered (through internal activation steering) along persona traits, and (ii) when the model is supervised-finetuned (SFT) to exhibit the same traits. We showed that steering towards traits, both related to persuasion and unrelated, does not reliably increase models' tendency to persuade unprompted, however, SFT does. Moreover, SFT on general persuasion datasets containing solely benign topics admits a model that has a higher propensity to persuade on controversial and harmful topics--showing that emergent harmful persuasion can arise and should be studied further.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Feb 18, 2025Sparse Autoencoders (SAEs) have emerged as a powerful framework for machine learning interpretability, enabling the unsupervised decomposition of model representations into a dictionary of abstract, human-interpretable concepts. However, we reveal a fundamental limitation: existing SAEs exhibit severe instability, as identical models trained on similar datasets can produce sharply different dictionaries, undermining their reliability as an interpretability tool. To address this issue, we draw inspiration from the Archetypal Analysis framework introduced by Cutler & Breiman (1994) and present Archetypal SAEs (A-SAE), wherein dictionary atoms are constrained to the convex hull of data. This geometric anchoring significantly enhances the stability of inferred dictionaries, and their mildly relaxed variants RA-SAEs further match state-of-the-art reconstruction abilities. To rigorously assess dictionary quality learned by SAEs, we introduce two new benchmarks that test (i) plausibility, if dictionaries recover "true" classification directions and (ii) identifiability, if dictionaries disentangle synthetic concept mixtures. Across all evaluations, RA-SAEs consistently yield more structured representations while uncovering novel, semantically meaningful concepts in large-scale vision models.
Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment
Feb 06, 2025We present Universal Sparse Autoencoders (USAEs), a framework for uncovering and aligning interpretable concepts spanning multiple pretrained deep neural networks. Unlike existing concept-based interpretability methods, which focus on a single model, USAEs jointly learn a universal concept space that can reconstruct and interpret the internal activations of multiple models at once. Our core insight is to train a single, overcomplete sparse autoencoder (SAE) that ingests activations from any model and decodes them to approximate the activations of any other model under consideration. By optimizing a shared objective, the learned dictionary captures common factors of variation-concepts-across different tasks, architectures, and datasets. We show that USAEs discover semantically coherent and important universal concepts across vision models; ranging from low-level features (e.g., colors and textures) to higher-level structures (e.g., parts and objects). Overall, USAEs provide a powerful new method for interpretable cross-model analysis and offers novel applications, such as coordinated activation maximization, that open avenues for deeper insights in multi-model AI systems
Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models
Apr 10, 2024



Understanding what deep network models capture in their learned representations is a fundamental challenge in computer vision. We present a new methodology to understanding such vision models, the Visual Concept Connectome (VCC), which discovers human interpretable concepts and their interlayer connections in a fully unsupervised manner. Our approach simultaneously reveals fine-grained concepts at a layer, connection weightings across all layers and is amendable to global analysis of network structure (e.g., branching pattern of hierarchical concept assemblies). Previous work yielded ways to extract interpretable concepts from single layers and examine their impact on classification, but did not afford multilayer concept analysis across an entire network architecture. Quantitative and qualitative empirical results show the effectiveness of VCCs in the domain of image classification. Also, we leverage VCCs for the application of failure mode debugging to reveal where mistakes arise in deep networks.
Multi-modal News Understanding with Professionally Labelled Videos (ReutersViLNews)
Jan 23, 2024
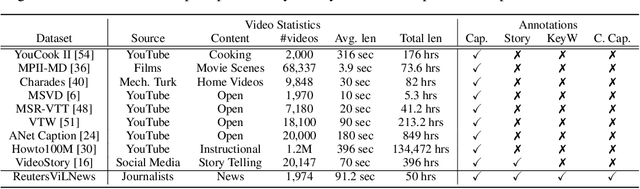
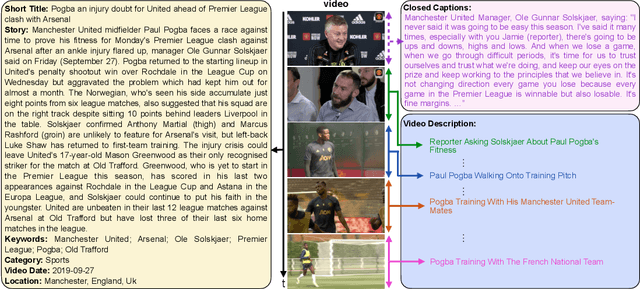
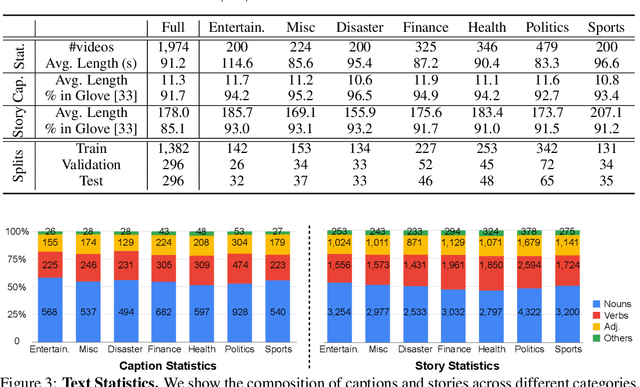
While progress has been made in the domain of video-language understanding, current state-of-the-art algorithms are still limited in their ability to understand videos at high levels of abstraction, such as news-oriented videos. Alternatively, humans easily amalgamate information from video and language to infer information beyond what is visually observable in the pixels. An example of this is watching a news story, where the context of the event can play as big of a role in understanding the story as the event itself. Towards a solution for designing this ability in algorithms, we present a large-scale analysis on an in-house dataset collected by the Reuters News Agency, called Reuters Video-Language News (ReutersViLNews) dataset which focuses on high-level video-language understanding with an emphasis on long-form news. The ReutersViLNews Dataset consists of long-form news videos collected and labeled by news industry professionals over several years and contains prominent news reporting from around the world. Each video involves a single story and contains action shots of the actual event, interviews with people associated with the event, footage from nearby areas, and more. ReutersViLNews dataset contains videos from seven subject categories: disaster, finance, entertainment, health, politics, sports, and miscellaneous with annotations from high-level to low-level, title caption, visual video description, high-level story description, keywords, and location. We first present an analysis of the dataset statistics of ReutersViLNews compared to previous datasets. Then we benchmark state-of-the-art approaches for four different video-language tasks. The results suggest that news-oriented videos are a substantial challenge for current video-language understanding algorithms and we conclude by providing future directions in designing approaches to solve the ReutersViLNews dataset.
Understanding Video Transformers via Universal Concept Discovery
Jan 19, 2024This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we demonstrate that VTCDcan be used to improve model performance for fine-grained tasks.
Quantifying and Learning Static vs. Dynamic Information in Deep Spatiotemporal Networks
Nov 03, 2022



There is limited understanding of the information captured by deep spatiotemporal models in their intermediate representations. For example, while evidence suggests that action recognition algorithms are heavily influenced by visual appearance in single frames, no quantitative methodology exists for evaluating such static bias in the latent representation compared to bias toward dynamics. We tackle this challenge by proposing an approach for quantifying the static and dynamic biases of any spatiotemporal model, and apply our approach to three tasks, action recognition, automatic video object segmentation (AVOS) and video instance segmentation (VIS). Our key findings are: (i) Most examined models are biased toward static information. (ii) Some datasets that are assumed to be biased toward dynamics are actually biased toward static information. (iii) Individual channels in an architecture can be biased toward static, dynamic or a combination of the two. (iv) Most models converge to their culminating biases in the first half of training. We then explore how these biases affect performance on dynamically biased datasets. For action recognition, we propose StaticDropout, a semantically guided dropout that debiases a model from static information toward dynamics. For AVOS, we design a better combination of fusion and cross connection layers compared with previous architectures.
A Deeper Dive Into What Deep Spatiotemporal Networks Encode: Quantifying Static vs. Dynamic Information
Jun 06, 2022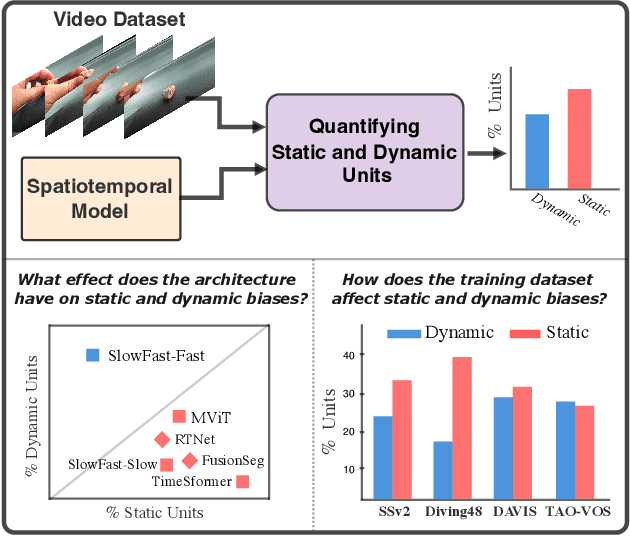
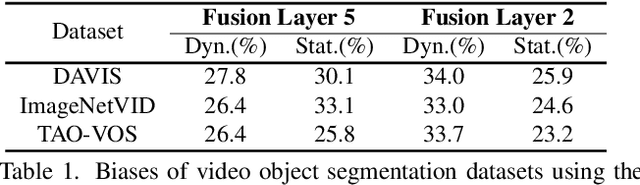
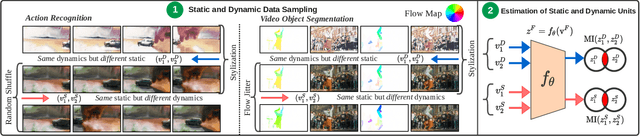
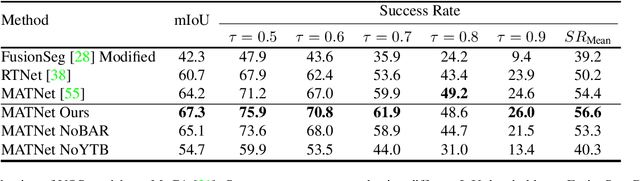
Deep spatiotemporal models are used in a variety of computer vision tasks, such as action recognition and video object segmentation. Currently, there is a limited understanding of what information is captured by these models in their intermediate representations. For example, while it has been observed that action recognition algorithms are heavily influenced by visual appearance in single static frames, there is no quantitative methodology for evaluating such static bias in the latent representation compared to bias toward dynamic information (e.g. motion). We tackle this challenge by proposing a novel approach for quantifying the static and dynamic biases of any spatiotemporal model. To show the efficacy of our approach, we analyse two widely studied tasks, action recognition and video object segmentation. Our key findings are threefold: (i) Most examined spatiotemporal models are biased toward static information; although, certain two-stream architectures with cross-connections show a better balance between the static and dynamic information captured. (ii) Some datasets that are commonly assumed to be biased toward dynamics are actually biased toward static information. (iii) Individual units (channels) in an architecture can be biased toward static, dynamic or a combination of the two.
Simpler Does It: Generating Semantic Labels with Objectness Guidance
Oct 20, 2021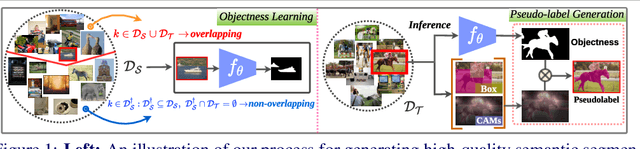
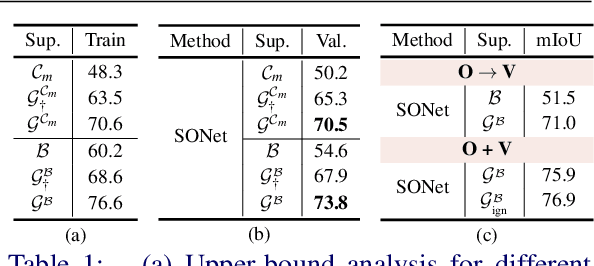
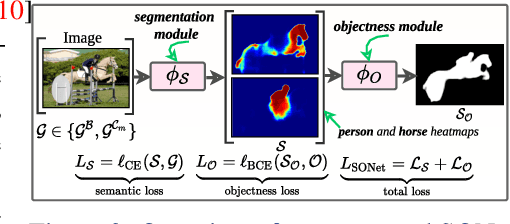
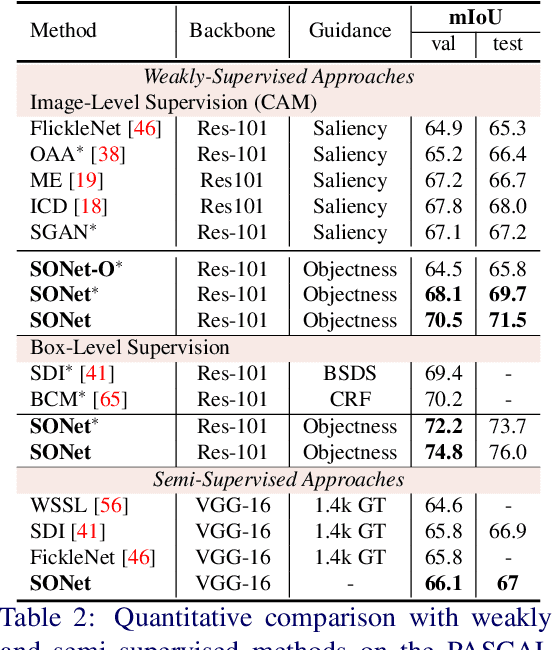
Existing weakly or semi-supervised semantic segmentation methods utilize image or box-level supervision to generate pseudo-labels for weakly labeled images. However, due to the lack of strong supervision, the generated pseudo-labels are often noisy near the object boundaries, which severely impacts the network's ability to learn strong representations. To address this problem, we present a novel framework that generates pseudo-labels for training images, which are then used to train a segmentation model. To generate pseudo-labels, we combine information from: (i) a class agnostic objectness network that learns to recognize object-like regions, and (ii) either image-level or bounding box annotations. We show the efficacy of our approach by demonstrating how the objectness network can naturally be leveraged to generate object-like regions for unseen categories. We then propose an end-to-end multi-task learning strategy, that jointly learns to segment semantics and objectness using the generated pseudo-labels. Extensive experiments demonstrate the high quality of our generated pseudo-labels and effectiveness of the proposed framework in a variety of domains. Our approach achieves better or competitive performance compared to existing weakly-supervised and semi-supervised methods.