 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal News Understanding with Professionally Labelled Videos (ReutersViLNews)
Jan 23, 2024
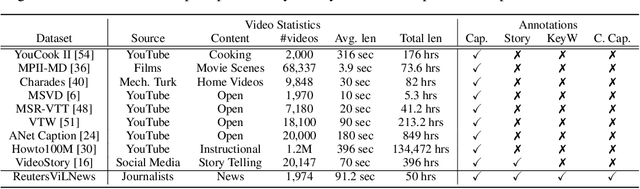
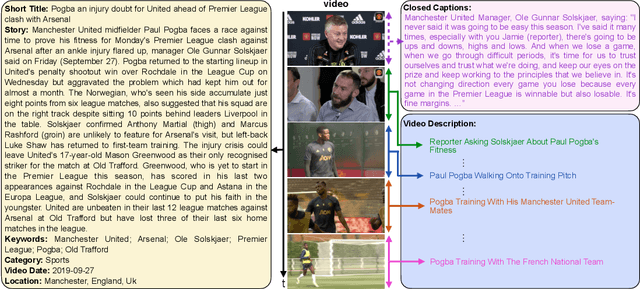
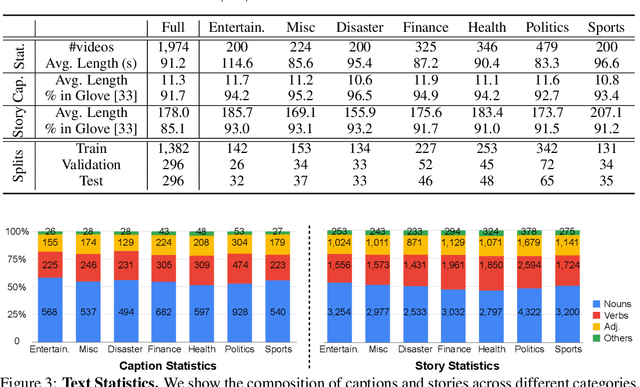
While progress has been made in the domain of video-language understanding, current state-of-the-art algorithms are still limited in their ability to understand videos at high levels of abstraction, such as news-oriented videos. Alternatively, humans easily amalgamate information from video and language to infer information beyond what is visually observable in the pixels. An example of this is watching a news story, where the context of the event can play as big of a role in understanding the story as the event itself. Towards a solution for designing this ability in algorithms, we present a large-scale analysis on an in-house dataset collected by the Reuters News Agency, called Reuters Video-Language News (ReutersViLNews) dataset which focuses on high-level video-language understanding with an emphasis on long-form news. The ReutersViLNews Dataset consists of long-form news videos collected and labeled by news industry professionals over several years and contains prominent news reporting from around the world. Each video involves a single story and contains action shots of the actual event, interviews with people associated with the event, footage from nearby areas, and more. ReutersViLNews dataset contains videos from seven subject categories: disaster, finance, entertainment, health, politics, sports, and miscellaneous with annotations from high-level to low-level, title caption, visual video description, high-level story description, keywords, and location. We first present an analysis of the dataset statistics of ReutersViLNews compared to previous datasets. Then we benchmark state-of-the-art approaches for four different video-language tasks. The results suggest that news-oriented videos are a substantial challenge for current video-language understanding algorithms and we conclude by providing future directions in designing approaches to solve the ReutersViLNews dataset.