 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Agentic Systems: Beyond Model Explanations to System-Level Accountability
Jan 23, 2026Agentic systems have transformed how Large Language Models (LLMs) can be leveraged to create autonomous systems with goal-directed behaviors, consisting of multi-step planning and the ability to interact with different environments. These systems differ fundamentally from traditional machine learning models, both in architecture and deployment, introducing unique AI safety challenges, including goal misalignment, compounding decision errors, and coordination risks among interacting agents, that necessitate embedding interpretability and explainability by design to ensure traceability and accountability across their autonomous behaviors. Current interpretability techniques, developed primarily for static models, show limitations when applied to agentic systems. The temporal dynamics, compounding decisions, and context-dependent behaviors of agentic systems demand new analytical approaches. This paper assesses the suitability and limitations of existing interpretability methods in the context of agentic systems, identifying gaps in their capacity to provide meaningful insight into agent decision-making. We propose future directions for developing interpretability techniques specifically designed for agentic systems, pinpointing where interpretability is required to embed oversight mechanisms across the agent lifecycle from goal formation, through environmental interaction, to outcome evaluation. These advances are essential to ensure the safe and accountable deployment of agentic AI systems.
Optimizing Large Language Models: Metrics, Energy Efficiency, and Case Study Insights
Apr 07, 2025The rapid adoption of large language models (LLMs) has led to significant energy consumption and carbon emissions, posing a critical challenge to the sustainability of generative AI technologies. This paper explores the integration of energy-efficient optimization techniques in the deployment of LLMs to address these environmental concerns. We present a case study and framework that demonstrate how strategic quantization and local inference techniques can substantially lower the carbon footprints of LLMs without compromising their operational effectiveness. Experimental results reveal that these methods can reduce energy consumption and carbon emissions by up to 45\% post quantization, making them particularly suitable for resource-constrained environments. The findings provide actionable insights for achieving sustainability in AI while maintaining high levels of accuracy and responsiveness.
Multi-modal News Understanding with Professionally Labelled Videos (ReutersViLNews)
Jan 23, 2024
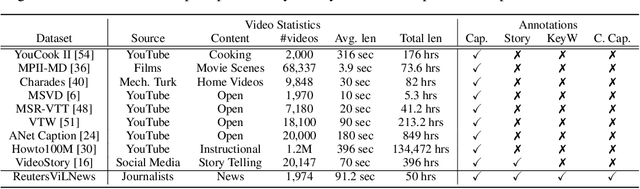
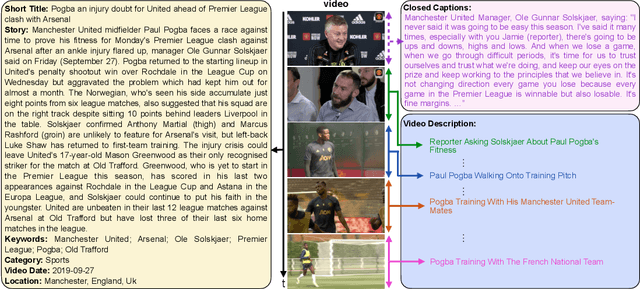
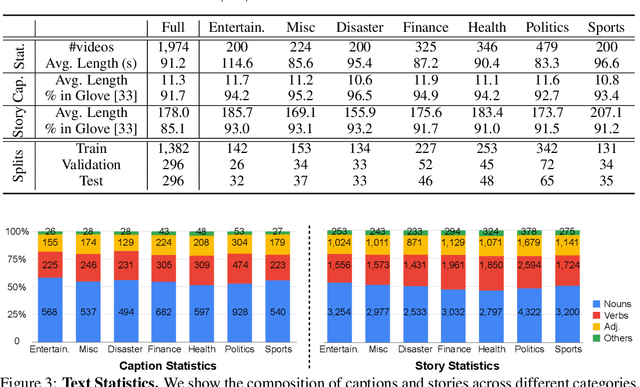
While progress has been made in the domain of video-language understanding, current state-of-the-art algorithms are still limited in their ability to understand videos at high levels of abstraction, such as news-oriented videos. Alternatively, humans easily amalgamate information from video and language to infer information beyond what is visually observable in the pixels. An example of this is watching a news story, where the context of the event can play as big of a role in understanding the story as the event itself. Towards a solution for designing this ability in algorithms, we present a large-scale analysis on an in-house dataset collected by the Reuters News Agency, called Reuters Video-Language News (ReutersViLNews) dataset which focuses on high-level video-language understanding with an emphasis on long-form news. The ReutersViLNews Dataset consists of long-form news videos collected and labeled by news industry professionals over several years and contains prominent news reporting from around the world. Each video involves a single story and contains action shots of the actual event, interviews with people associated with the event, footage from nearby areas, and more. ReutersViLNews dataset contains videos from seven subject categories: disaster, finance, entertainment, health, politics, sports, and miscellaneous with annotations from high-level to low-level, title caption, visual video description, high-level story description, keywords, and location. We first present an analysis of the dataset statistics of ReutersViLNews compared to previous datasets. Then we benchmark state-of-the-art approaches for four different video-language tasks. The results suggest that news-oriented videos are a substantial challenge for current video-language understanding algorithms and we conclude by providing future directions in designing approaches to solve the ReutersViLNews dataset.
Domain Specific Fine-tuning of Denoising Sequence-to-Sequence Models for Natural Language Summarization
Apr 06, 2022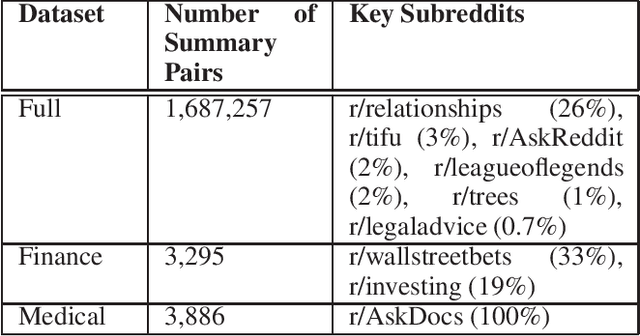
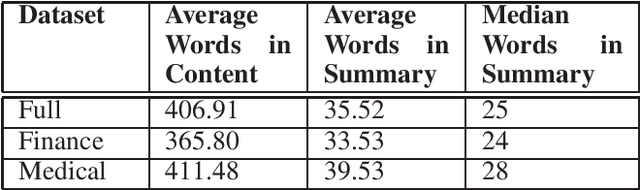
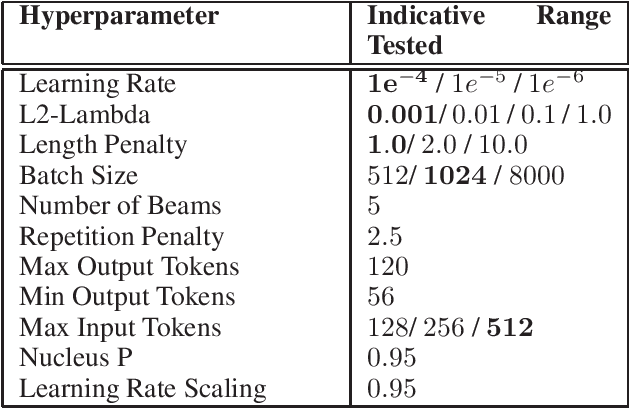

Summarization of long-form text data is a problem especially pertinent in knowledge economy jobs such as medicine and finance, that require continuously remaining informed on a sophisticated and evolving body of knowledge. As such, isolating and summarizing key content automatically using Natural Language Processing (NLP) techniques holds the potential for extensive time savings in these industries. We explore applications of a state-of-the-art NLP model (BART), and explore strategies for tuning it to optimal performance using data augmentation and various fine-tuning strategies. We show that our end-to-end fine-tuning approach can result in a 5-6\% absolute ROUGE-1 improvement over an out-of-the-box pre-trained BART summarizer when tested on domain specific data, and make available our end-to-end pipeline to achieve these results on finance, medical, or other user-specified domains.
An Experimental Evaluation of Transformer-based Language Models in the Biomedical Domain
Dec 31, 2020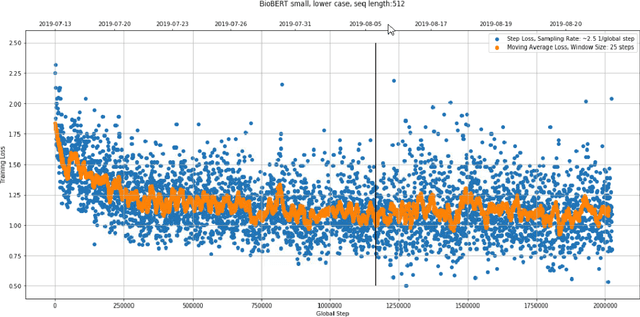
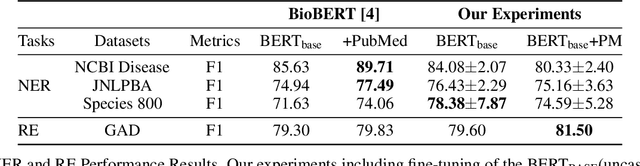
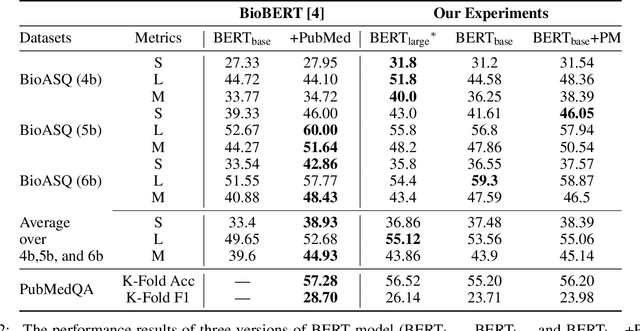

With the growing amount of text in health data, there have been rapid advances in large pre-trained models that can be applied to a wide variety of biomedical tasks with minimal task-specific modifications. Emphasizing the cost of these models, which renders technical replication challenging, this paper summarizes experiments conducted in replicating BioBERT and further pre-training and careful fine-tuning in the biomedical domain. We also investigate the effectiveness of domain-specific and domain-agnostic pre-trained models across downstream biomedical NLP tasks. Our finding confirms that pre-trained models can be impactful in some downstream NLP tasks (QA and NER) in the biomedical domain; however, this improvement may not justify the high cost of domain-specific pre-training.