 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Selective Adaptation Enables Cross-Platform Predictive Fluorescence Microscopy
Nov 15, 2025Deep learning is transforming microscopy, yet models often fail when applied to images from new instruments or acquisition settings. Conventional adversarial domain adaptation (ADDA) retrains entire networks, often disrupting learned semantic representations. Here, we overturn this paradigm by showing that adapting only the earliest convolutional layers, while freezing deeper layers, yields reliable transfer. Building on this principle, we introduce Subnetwork Image Translation ADDA with automatic depth selection (SIT-ADDA-Auto), a self-configuring framework that integrates shallow-layer adversarial alignment with predictive uncertainty to automatically select adaptation depth without target labels. We demonstrate robustness via multi-metric evaluation, blinded expert assessment, and uncertainty-depth ablations. Across exposure and illumination shifts, cross-instrument transfer, and multiple stains, SIT-ADDA improves reconstruction and downstream segmentation over full-encoder adaptation and non-adversarial baselines, with reduced drift of semantic features. Our results provide a design rule for label-free adaptation in microscopy and a recipe for field settings; the code is publicly available.
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
An Experimental Evaluation of Transformer-based Language Models in the Biomedical Domain
Dec 31, 2020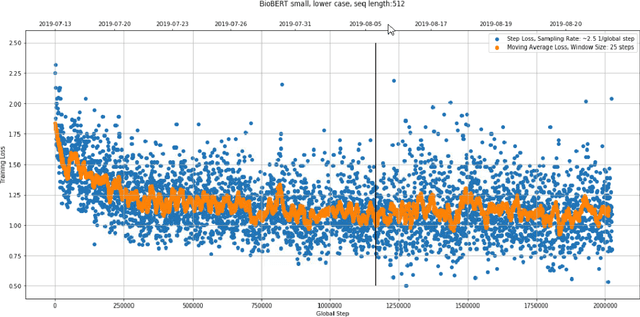
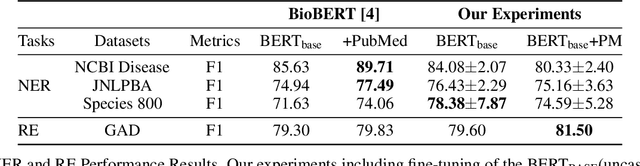
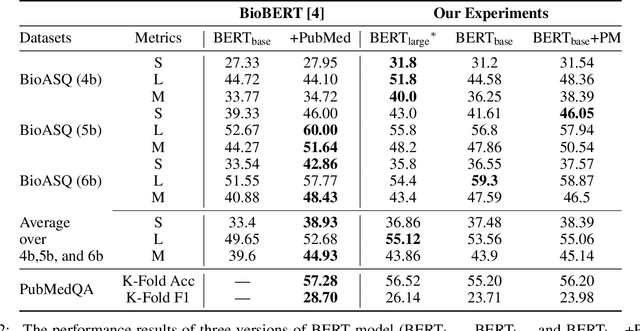

With the growing amount of text in health data, there have been rapid advances in large pre-trained models that can be applied to a wide variety of biomedical tasks with minimal task-specific modifications. Emphasizing the cost of these models, which renders technical replication challenging, this paper summarizes experiments conducted in replicating BioBERT and further pre-training and careful fine-tuning in the biomedical domain. We also investigate the effectiveness of domain-specific and domain-agnostic pre-trained models across downstream biomedical NLP tasks. Our finding confirms that pre-trained models can be impactful in some downstream NLP tasks (QA and NER) in the biomedical domain; however, this improvement may not justify the high cost of domain-specific pre-training.