 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Rubrics as Contextual Verifiers for SWE Agents
Jan 07, 2026Verification is critical for improving agents: it provides the reward signal for Reinforcement Learning and enables inference-time gains through Test-Time Scaling (TTS). Despite its importance, verification in software engineering (SWE) agent settings often relies on code execution, which can be difficult to scale due to environment setup overhead. Scalable alternatives such as patch classifiers and heuristic methods exist, but they are less grounded in codebase context and harder to interpret. To this end, we explore Agentic Rubrics: an expert agent interacts with the repository to create a context-grounded rubric checklist, and candidate patches are then scored against it without requiring test execution. On SWE-Bench Verified under parallel TTS evaluation, Agentic Rubrics achieve a score of 54.2% on Qwen3-Coder-30B-A3B and 40.6% on Qwen3-32B, with at least a +3.5 percentage-point gain over the strongest baseline in our comparison set. We further analyze rubric behavior, showing that rubric scores are consistent with ground-truth tests while also flagging issues that tests do not capture. Our ablations show that agentic context gathering is essential for producing codebase-specific, unambiguous criteria. Together, these results suggest that Agentic Rubrics provide an efficient, scalable, and granular verification signal for SWE agents.
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Jul 23, 2025
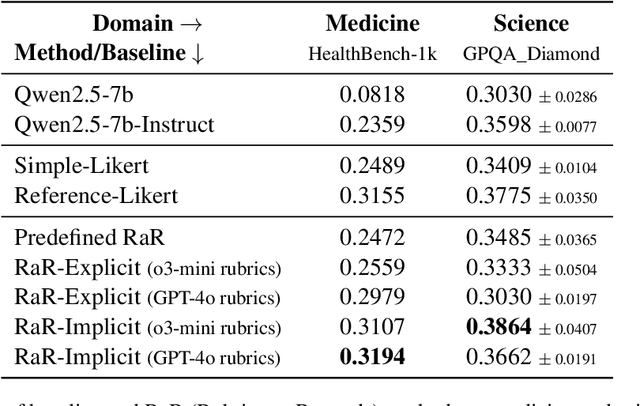
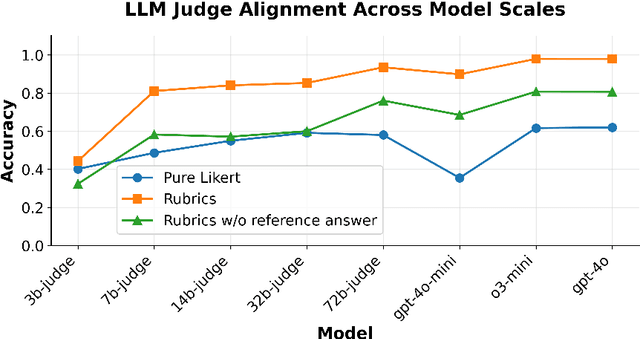
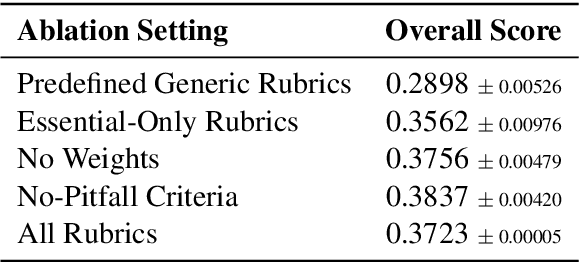
Extending Reinforcement Learning with Verifiable Rewards (RLVR) to real-world tasks often requires balancing objective and subjective evaluation criteria. However, many such tasks lack a single, unambiguous ground truth-making it difficult to define reliable reward signals for post-training language models. While traditional preference-based methods offer a workaround, they rely on opaque reward functions that are difficult to interpret and prone to spurious correlations. We introduce $\textbf{Rubrics as Rewards}$ (RaR), a framework that uses structured, checklist-style rubrics as interpretable reward signals for on-policy training with GRPO. Our best RaR method yields up to a $28\%$ relative improvement on HealthBench-1k compared to simple Likert-based approaches, while matching or surpassing the performance of reward signals derived from expert-written references. By treating rubrics as structured reward signals, we show that RaR enables smaller-scale judge models to better align with human preferences and sustain robust performance across model scales.
Molecular Facts: Desiderata for Decontextualization in LLM Fact Verification
Jun 28, 2024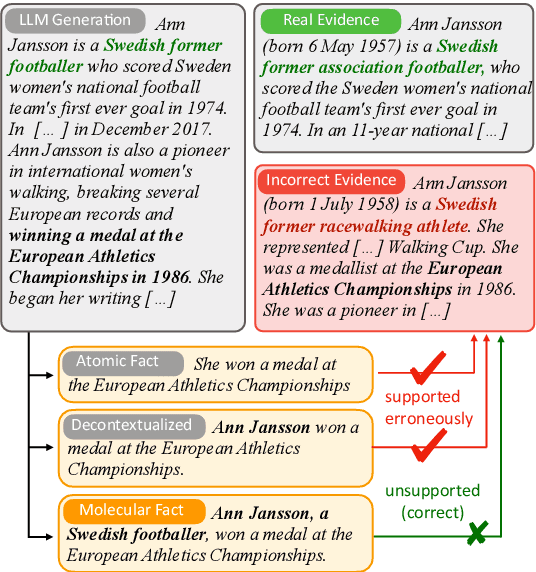
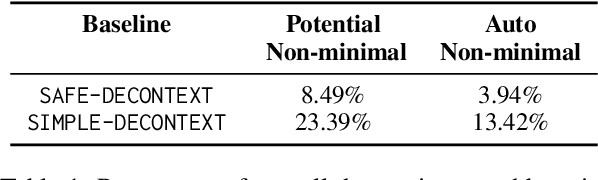
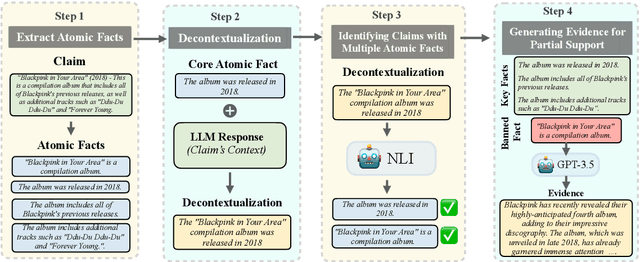
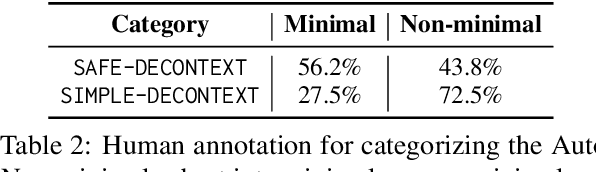
Automatic factuality verification of large language model (LLM) generations is becoming more and more widely used to combat hallucinations. A major point of tension in the literature is the granularity of this fact-checking: larger chunks of text are hard to fact-check, but more atomic facts like propositions may lack context to interpret correctly. In this work, we assess the role of context in these atomic facts. We argue that fully atomic facts are not the right representation, and define two criteria for molecular facts: decontextuality, or how well they can stand alone, and minimality, or how little extra information is added to achieve decontexuality. We quantify the impact of decontextualization on minimality, then present a baseline methodology for generating molecular facts automatically, aiming to add the right amount of information. We compare against various methods of decontextualization and find that molecular facts balance minimality with fact verification accuracy in ambiguous settings.
Detecting and Preventing Hallucinations in Large Vision Language Models
Aug 18, 2023


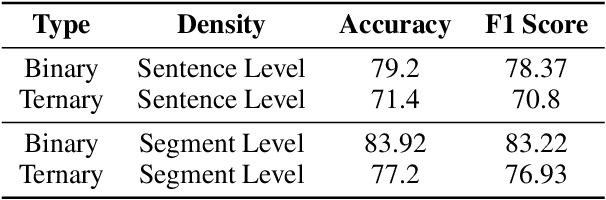
Instruction tuned Large Vision Language Models (LVLMs) have significantly advanced in generalizing across a diverse set of multi-modal tasks, especially for Visual Question Answering (VQA). However, generating detailed responses that are visually grounded is still a challenging task for these models. We find that even the current state-of-the-art LVLMs (InstructBLIP) still contain a staggering 30 percent of the hallucinatory text in the form of non-existent objects, unfaithful descriptions, and inaccurate relationships. To address this, we introduce M-HalDetect, a (M)ultimodal (Hal)lucination (Detect)ion Dataset that can be used to train and benchmark models for hallucination detection and prevention. M-HalDetect consists of 16k fine-grained annotations on VQA examples, making it the first comprehensive multi-modal hallucination detection dataset for detailed image descriptions. Unlike previous work that only consider object hallucination, we additionally annotate both entity descriptions and relationships that are unfaithful. To demonstrate the potential of this dataset for hallucination prevention, we optimize InstructBLIP through our novel Fine-grained Direct Preference Optimization (FDPO). We also train fine-grained multi-modal reward models from InstructBLIP and evaluate their effectiveness with best-of-n rejection sampling. We perform human evaluation on both FDPO and rejection sampling, and find that they reduce hallucination rates in InstructBLIP by 41% and 55% respectively. We also find that our reward model generalizes to other multi-modal models, reducing hallucinations in LLaVA and mPLUG-OWL by 15% and 57% respectively, and has strong correlation with human evaluated accuracy scores.
Drafting Event Schemas using Language Models
May 24, 2023
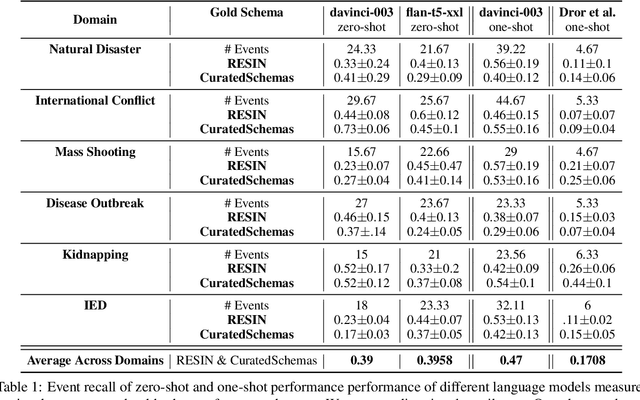
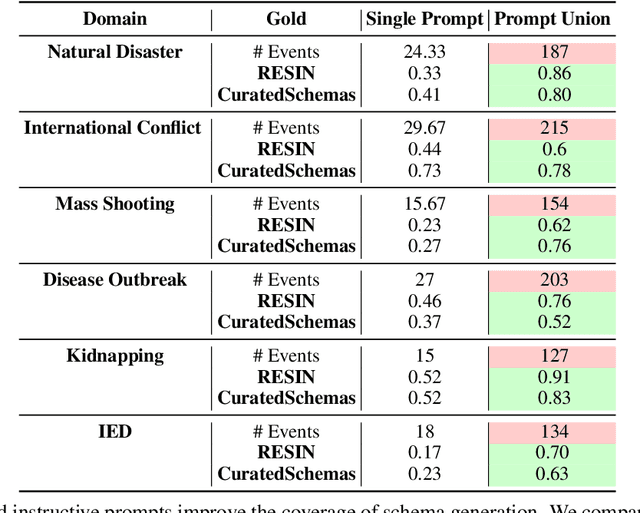
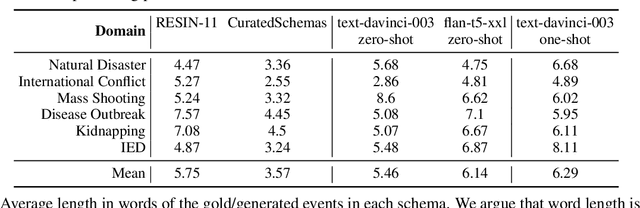
Past work has studied event prediction and event language modeling, sometimes mediated through structured representations of knowledge in the form of event schemas. Such schemas can lead to explainable predictions and forecasting of unseen events given incomplete information. In this work, we look at the process of creating such schemas to describe complex events. We use large language models (LLMs) to draft schemas directly in natural language, which can be further refined by human curators as necessary. Our focus is on whether we can achieve sufficient diversity and recall of key events and whether we can produce the schemas in a sufficiently descriptive style. We show that large language models are able to achieve moderate recall against schemas taken from two different datasets, with even better results when multiple prompts and multiple samples are combined. Moreover, we show that textual entailment methods can be used for both matching schemas to instances of events as well as evaluating overlap between gold and predicted schemas. Our method paves the way for easier distillation of event knowledge from large language model into schemas.
Task-Induced Representation Learning
Apr 25, 2022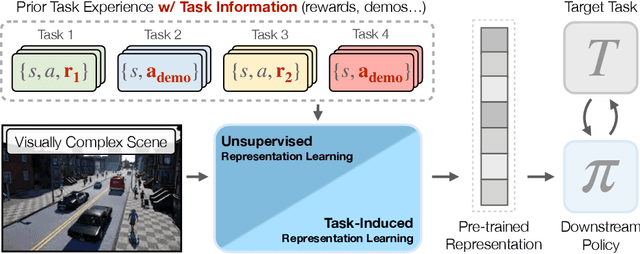
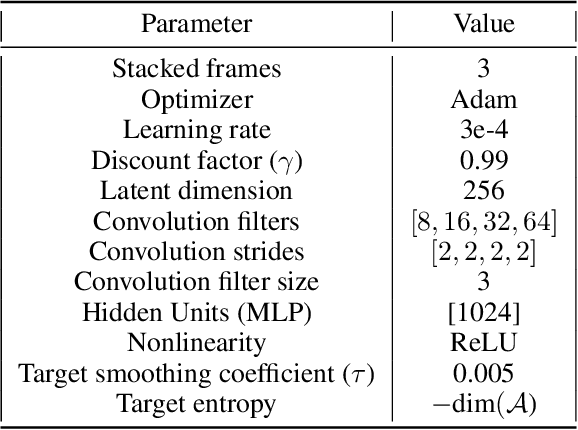
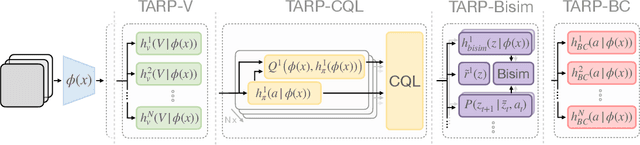

In this work, we evaluate the effectiveness of representation learning approaches for decision making in visually complex environments. Representation learning is essential for effective reinforcement learning (RL) from high-dimensional inputs. Unsupervised representation learning approaches based on reconstruction, prediction or contrastive learning have shown substantial learning efficiency gains. Yet, they have mostly been evaluated in clean laboratory or simulated settings. In contrast, real environments are visually complex and contain substantial amounts of clutter and distractors. Unsupervised representations will learn to model such distractors, potentially impairing the agent's learning efficiency. In contrast, an alternative class of approaches, which we call task-induced representation learning, leverages task information such as rewards or demonstrations from prior tasks to focus on task-relevant parts of the scene and ignore distractors. We investigate the effectiveness of unsupervised and task-induced representation learning approaches on four visually complex environments, from Distracting DMControl to the CARLA driving simulator. For both, RL and imitation learning, we find that representation learning generally improves sample efficiency on unseen tasks even in visually complex scenes and that task-induced representations can double learning efficiency compared to unsupervised alternatives. Code is available at https://clvrai.com/tarp.