 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrafting Event Schemas using Language Models
Paper and Code
May 24, 2023
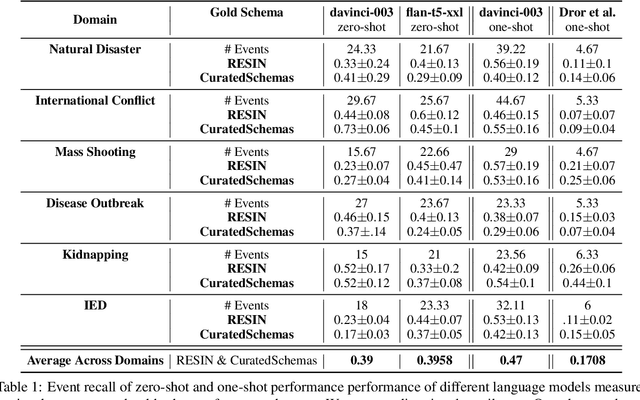
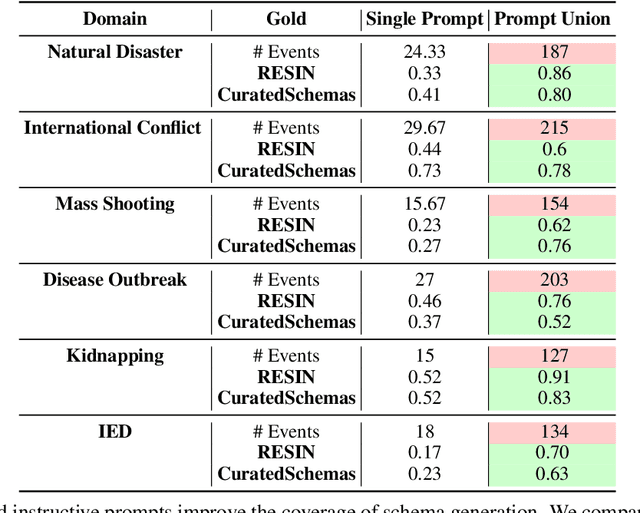
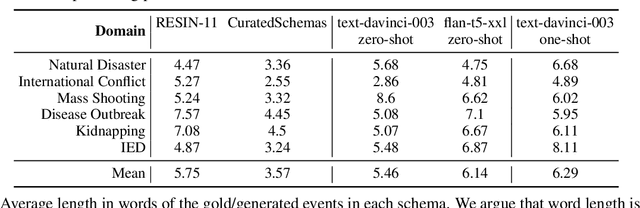
Past work has studied event prediction and event language modeling, sometimes mediated through structured representations of knowledge in the form of event schemas. Such schemas can lead to explainable predictions and forecasting of unseen events given incomplete information. In this work, we look at the process of creating such schemas to describe complex events. We use large language models (LLMs) to draft schemas directly in natural language, which can be further refined by human curators as necessary. Our focus is on whether we can achieve sufficient diversity and recall of key events and whether we can produce the schemas in a sufficiently descriptive style. We show that large language models are able to achieve moderate recall against schemas taken from two different datasets, with even better results when multiple prompts and multiple samples are combined. Moreover, we show that textual entailment methods can be used for both matching schemas to instances of events as well as evaluating overlap between gold and predicted schemas. Our method paves the way for easier distillation of event knowledge from large language model into schemas.