 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Oct 08, 2025Amid growing efforts to leverage advances in large language models (LLMs) and vision-language models (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. Unlike previous surveys that focus narrowly on action representations or high-level model architectures, this work offers a comprehensive, full-stack review, integrating both software and hardware components of VLA systems. In particular, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems. All references categorized by training approach, evaluation method, modality, and dataset are available in the table on our project website: https://vla-survey.github.io .
GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
COMBO-Grasp: Learning Constraint-Based Manipulation for Bimanual Occluded Grasping
Feb 12, 2025

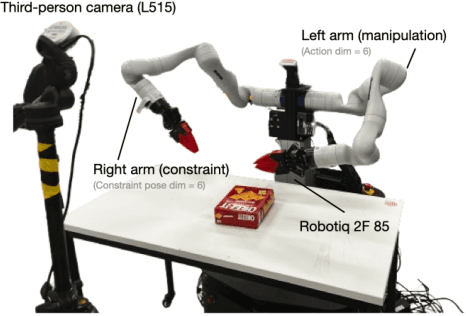
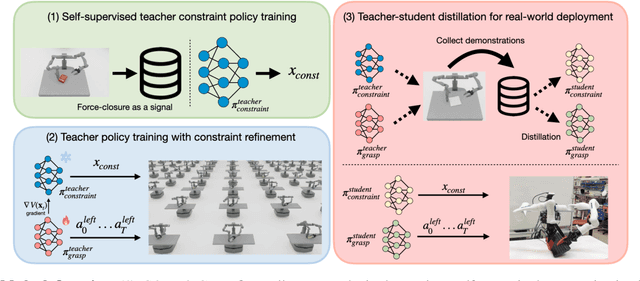
This paper addresses the challenge of occluded robot grasping, i.e. grasping in situations where the desired grasp poses are kinematically infeasible due to environmental constraints such as surface collisions. Traditional robot manipulation approaches struggle with the complexity of non-prehensile or bimanual strategies commonly used by humans in these circumstances. State-of-the-art reinforcement learning (RL) methods are unsuitable due to the inherent complexity of the task. In contrast, learning from demonstration requires collecting a significant number of expert demonstrations, which is often infeasible. Instead, inspired by human bimanual manipulation strategies, where two hands coordinate to stabilise and reorient objects, we focus on a bimanual robotic setup to tackle this challenge. In particular, we introduce Constraint-based Manipulation for Bimanual Occluded Grasping (COMBO-Grasp), a learning-based approach which leverages two coordinated policies: a constraint policy trained using self-supervised datasets to generate stabilising poses and a grasping policy trained using RL that reorients and grasps the target object. A key contribution lies in value function-guided policy coordination. Specifically, during RL training for the grasping policy, the constraint policy's output is refined through gradients from a jointly trained value function, improving bimanual coordination and task performance. Lastly, COMBO-Grasp employs teacher-student policy distillation to effectively deploy point cloud-based policies in real-world environments. Empirical evaluations demonstrate that COMBO-Grasp significantly improves task success rates compared to competitive baseline approaches, with successful generalisation to unseen objects in both simulated and real-world environments.
D-Cubed: Latent Diffusion Trajectory Optimisation for Dexterous Deformable Manipulation
Mar 19, 2024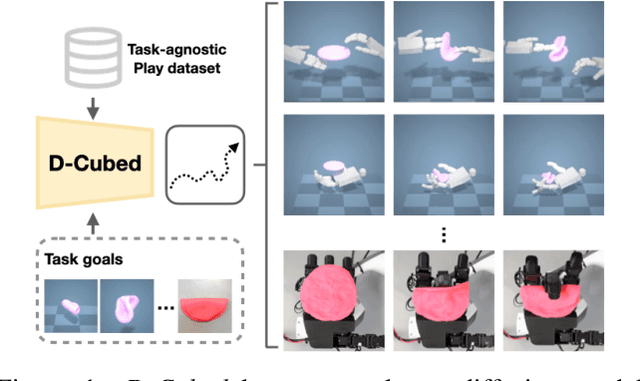

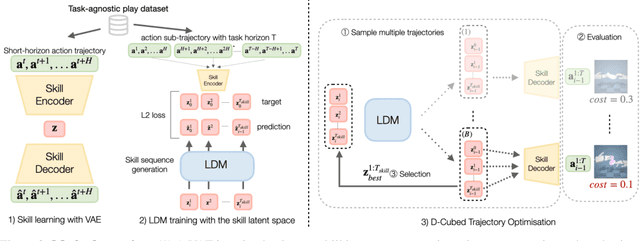
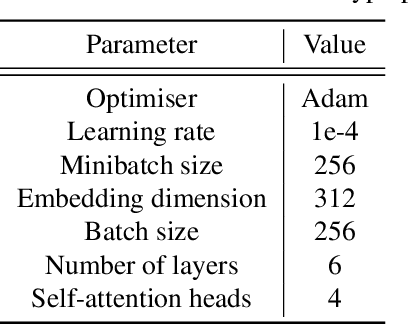
Mastering dexterous robotic manipulation of deformable objects is vital for overcoming the limitations of parallel grippers in real-world applications. Current trajectory optimisation approaches often struggle to solve such tasks due to the large search space and the limited task information available from a cost function. In this work, we propose D-Cubed, a novel trajectory optimisation method using a latent diffusion model (LDM) trained from a task-agnostic play dataset to solve dexterous deformable object manipulation tasks. D-Cubed learns a skill-latent space that encodes short-horizon actions in the play dataset using a VAE and trains a LDM to compose the skill latents into a skill trajectory, representing a long-horizon action trajectory in the dataset. To optimise a trajectory for a target task, we introduce a novel gradient-free guided sampling method that employs the Cross-Entropy method within the reverse diffusion process. In particular, D-Cubed samples a small number of noisy skill trajectories using the LDM for exploration and evaluates the trajectories in simulation. Then, D-Cubed selects the trajectory with the lowest cost for the subsequent reverse process. This effectively explores promising solution areas and optimises the sampled trajectories towards a target task throughout the reverse diffusion process. Through empirical evaluation on a public benchmark of dexterous deformable object manipulation tasks, we demonstrate that D-Cubed outperforms traditional trajectory optimisation and competitive baseline approaches by a significant margin. We further demonstrate that trajectories found by D-Cubed readily transfer to a real-world LEAP hand on a folding task.
World Models via Policy-Guided Trajectory Diffusion
Dec 17, 2023



World models are a powerful tool for developing intelligent agents. By predicting the outcome of a sequence of actions, world models enable policies to be optimised via on-policy reinforcement learning (RL) using synthetic data, i.e. in "in imagination". Existing world models are autoregressive in that they interleave predicting the next state with sampling the next action from the policy. Prediction error inevitably compounds as the trajectory length grows. In this work, we propose a novel world modelling approach that is not autoregressive and generates entire on-policy trajectories in a single pass through a diffusion model. Our approach, Policy-Guided Trajectory Diffusion (PolyGRAD), leverages a denoising model in addition to the gradient of the action distribution of the policy to diffuse a trajectory of initially random states and actions into an on-policy synthetic trajectory. We analyse the connections between PolyGRAD, score-based generative models, and classifier-guided diffusion models. Our results demonstrate that PolyGRAD outperforms state-of-the-art baselines in terms of trajectory prediction error for moderate-length trajectories, with the exception of autoregressive diffusion. At short horizons, PolyGRAD obtains comparable errors to autoregressive diffusion, but with significantly lower computational requirements. Our experiments also demonstrate that PolyGRAD enables performant policies to be trained via on-policy RL in imagination for MuJoCo continuous control domains. Thus, PolyGRAD introduces a new paradigm for scalable and non-autoregressive on-policy world modelling.
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer
Nov 07, 2023Model-based RL is a promising approach for real-world robotics due to its improved sample efficiency and generalization capabilities compared to model-free RL. However, effective model-based RL solutions for vision-based real-world applications require bridging the sim-to-real gap for any world model learnt. Due to its significant computational cost, standard domain randomisation does not provide an effective solution to this problem. This paper proposes TWIST (Teacher-Student World Model Distillation for Sim-to-Real Transfer) to achieve efficient sim-to-real transfer of vision-based model-based RL using distillation. Specifically, TWIST leverages state observations as readily accessible, privileged information commonly garnered from a simulator to significantly accelerate sim-to-real transfer. Specifically, a teacher world model is trained efficiently on state information. At the same time, a matching dataset is collected of domain-randomised image observations. The teacher world model then supervises a student world model that takes the domain-randomised image observations as input. By distilling the learned latent dynamics model from the teacher to the student model, TWIST achieves efficient and effective sim-to-real transfer for vision-based model-based RL tasks. Experiments in simulated and real robotics tasks demonstrate that our approach outperforms naive domain randomisation and model-free methods in terms of sample efficiency and task performance of sim-to-real transfer.
RAMP: A Benchmark for Evaluating Robotic Assembly Manipulation and Planning
May 16, 2023

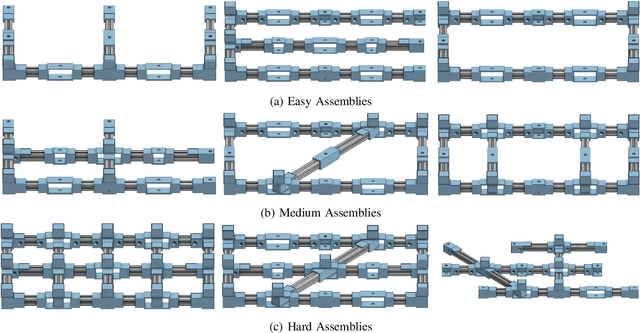

We introduce RAMP, an open-source robotics benchmark inspired by real-world industrial assembly tasks. RAMP consists of beams that a robot must assemble into specified goal configurations using pegs as fasteners. As such it assesses planning and execution capabilities, and poses challenges in perception, reasoning, manipulation, diagnostics, fault recovery and goal parsing. RAMP has been designed to be accessible and extensible. Parts are either 3D printed or otherwise constructed from materials that are readily obtainable. The part design and detailed instructions are publicly available. In order to broaden community engagement, RAMP incorporates fixtures such as April Tags which enable researchers to focus on individual sub-tasks of the assembly challenge if desired. We provide a full digital twin as well as rudimentary baselines to enable rapid progress. Our vision is for RAMP to form the substrate for a community-driven endeavour that evolves as capability matures.
Efficient Skill Acquisition for Complex Manipulation Tasks in Obstructed Environments
Mar 06, 2023



Data efficiency in robotic skill acquisition is crucial for operating robots in varied small-batch assembly settings. To operate in such environments, robots must have robust obstacle avoidance and versatile goal conditioning acquired from only a few simple demonstrations. Existing approaches, however, fall short of these requirements. Deep reinforcement learning (RL) enables a robot to learn complex manipulation tasks but is often limited to small task spaces in the real world due to sample inefficiency and safety concerns. Motion planning (MP) can generate collision-free paths in obstructed environments, but cannot solve complex manipulation tasks and requires goal states often specified by a user or object-specific pose estimator. In this work, we propose a system for efficient skill acquisition that leverages an object-centric generative model (OCGM) for versatile goal identification to specify a goal for MP combined with RL to solve complex manipulation tasks in obstructed environments. Specifically, OCGM enables one-shot target object identification and re-identification in new scenes, allowing MP to guide the robot to the target object while avoiding obstacles. This is combined with a skill transition network, which bridges the gap between terminal states of MP and feasible start states of a sample-efficient RL policy. The experiments demonstrate that our OCGM-based one-shot goal identification provides competitive accuracy to other baseline approaches and that our modular framework outperforms competitive baselines, including a state-of-the-art RL algorithm, by a significant margin for complex manipulation tasks in obstructed environments.
Leveraging Scene Embeddings for Gradient-Based Motion Planning in Latent Space
Mar 06, 2023



Motion planning framed as optimisation in structured latent spaces has recently emerged as competitive with traditional methods in terms of planning success while significantly outperforming them in terms of computational speed. However, the real-world applicability of recent work in this domain remains limited by the need to express obstacle information directly in state-space, involving simple geometric primitives. In this work we address this challenge by leveraging learned scene embeddings together with a generative model of the robot manipulator to drive the optimisation process. In addition, we introduce an approach for efficient collision checking which directly regularises the optimisation undertaken for planning. Using simulated as well as real-world experiments, we demonstrate that our approach, AMP-LS, is able to successfully plan in novel, complex scenes while outperforming traditional planning baselines in terms of computation speed by an order of magnitude. We show that the resulting system is fast enough to enable closed-loop planning in real-world dynamic scenes.
* Project website: https://amp-ls.github.io/
Task-Induced Representation Learning
Apr 25, 2022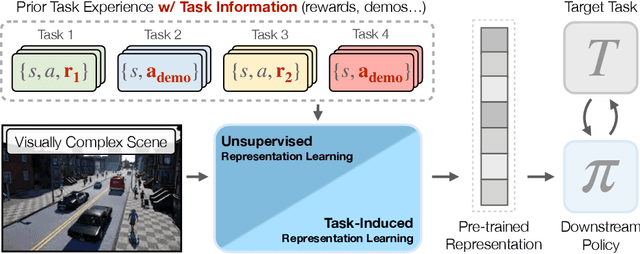
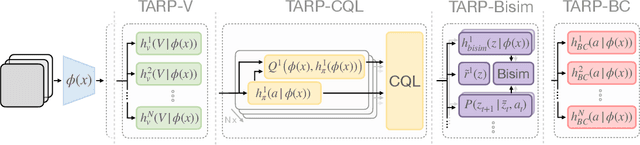

In this work, we evaluate the effectiveness of representation learning approaches for decision making in visually complex environments. Representation learning is essential for effective reinforcement learning (RL) from high-dimensional inputs. Unsupervised representation learning approaches based on reconstruction, prediction or contrastive learning have shown substantial learning efficiency gains. Yet, they have mostly been evaluated in clean laboratory or simulated settings. In contrast, real environments are visually complex and contain substantial amounts of clutter and distractors. Unsupervised representations will learn to model such distractors, potentially impairing the agent's learning efficiency. In contrast, an alternative class of approaches, which we call task-induced representation learning, leverages task information such as rewards or demonstrations from prior tasks to focus on task-relevant parts of the scene and ignore distractors. We investigate the effectiveness of unsupervised and task-induced representation learning approaches on four visually complex environments, from Distracting DMControl to the CARLA driving simulator. For both, RL and imitation learning, we find that representation learning generally improves sample efficiency on unseen tasks even in visually complex scenes and that task-induced representations can double learning efficiency compared to unsupervised alternatives. Code is available at https://clvrai.com/tarp.