 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments
Oct 22, 2020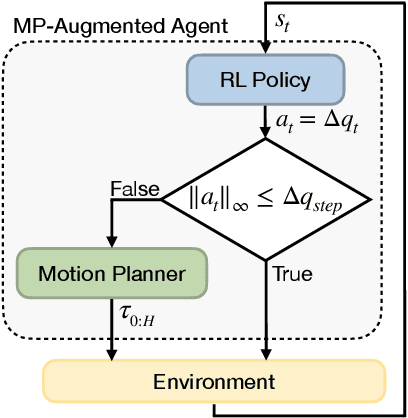

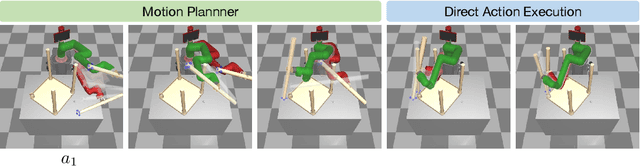

Deep reinforcement learning (RL) agents are able to learn contact-rich manipulation tasks by maximizing a reward signal, but require large amounts of experience, especially in environments with many obstacles that complicate exploration. In contrast, motion planners use explicit models of the agent and environment to plan collision-free paths to faraway goals, but suffer from inaccurate models in tasks that require contacts with the environment. To combine the benefits of both approaches, we propose motion planner augmented RL (MoPA-RL) which augments the action space of an RL agent with the long-horizon planning capabilities of motion planners. Based on the magnitude of the action, our approach smoothly transitions between directly executing the action and invoking a motion planner. We evaluate our approach on various simulated manipulation tasks and compare it to alternative action spaces in terms of learning efficiency and safety. The experiments demonstrate that MoPA-RL increases learning efficiency, leads to a faster exploration, and results in safer policies that avoid collisions with the environment. Videos and code are available at https://clvrai.com/mopa-rl .
Plan-Space State Embeddings for Improved Reinforcement Learning
Apr 30, 2020
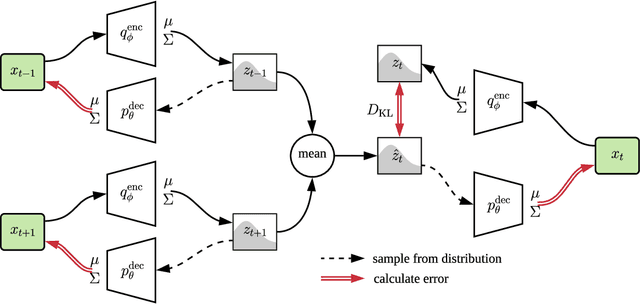
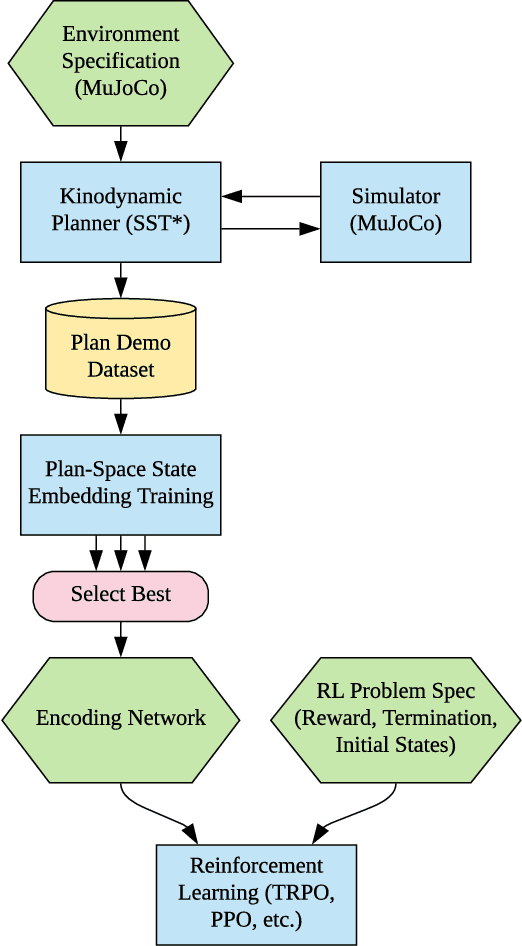
Robot control problems are often structured with a policy function that maps state values into control values, but in many dynamic problems the observed state can have a difficult to characterize relationship with useful policy actions. In this paper we present a new method for learning state embeddings from plans or other forms of demonstrations such that the embedding space has a specified geometric relationship with the demonstrations. We present a novel variational framework for learning these embeddings that attempts to optimize trajectory linearity in the learned embedding space. We show how these embedding spaces can then be used as an augmentation to the robot state in reinforcement learning problems. We use kinodynamic planning to generate training trajectories for some example environments, and then train embedding spaces for these environments. We show empirically that observing a system in the learned embedding space improves the performance of policy gradient reinforcement learning algorithms, particularly by reducing the variance between training runs. Our technique is limited to environments where demonstration data is available, but places no limits on how that data is collected. Our embedding technique provides a way to transfer domain knowledge from existing technologies such as planning and control algorithms, into more flexible policy learning algorithms, by creating an abstract representation of the robot state with meaningful geometry.