 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation
Nov 11, 2021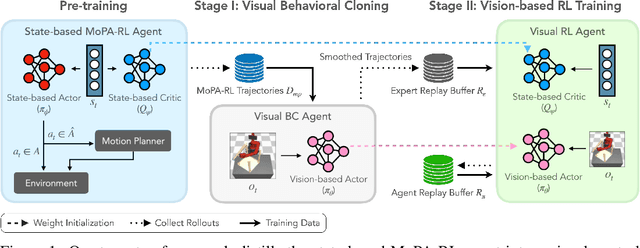
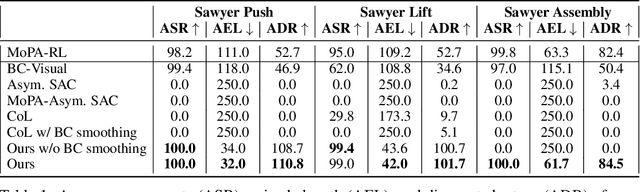
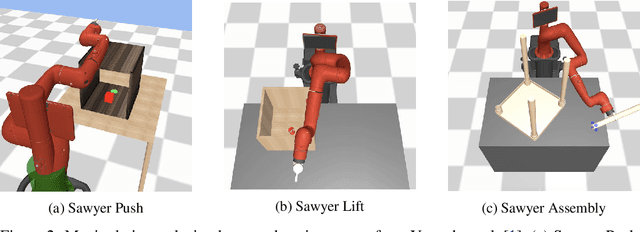

Learning complex manipulation tasks in realistic, obstructed environments is a challenging problem due to hard exploration in the presence of obstacles and high-dimensional visual observations. Prior work tackles the exploration problem by integrating motion planning and reinforcement learning. However, the motion planner augmented policy requires access to state information, which is often not available in the real-world settings. To this end, we propose to distill a state-based motion planner augmented policy to a visual control policy via (1) visual behavioral cloning to remove the motion planner dependency along with its jittery motion, and (2) vision-based reinforcement learning with the guidance of the smoothed trajectories from the behavioral cloning agent. We evaluate our method on three manipulation tasks in obstructed environments and compare it against various reinforcement learning and imitation learning baselines. The results demonstrate that our framework is highly sample-efficient and outperforms the state-of-the-art algorithms. Moreover, coupled with domain randomization, our policy is capable of zero-shot transfer to unseen environment settings with distractors. Code and videos are available at https://clvrai.com/mopa-pd
Pathfinder Discovery Networks for Neural Message Passing
Oct 24, 2020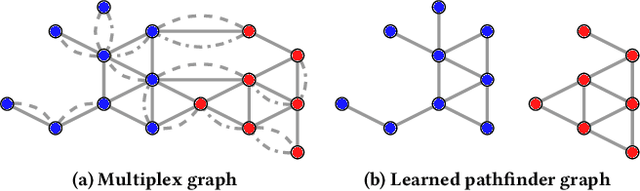
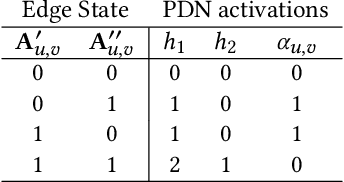
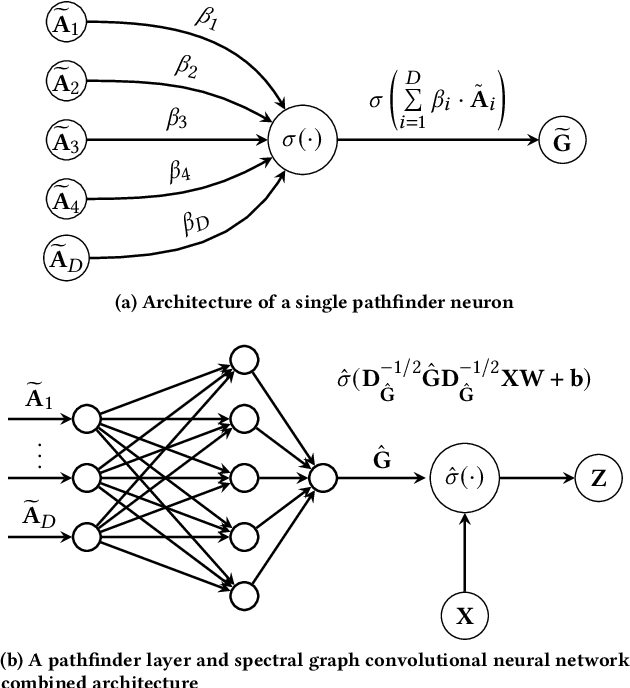
In this work we propose Pathfinder Discovery Networks (PDNs), a method for jointly learning a message passing graph over a multiplex network with a downstream semi-supervised model. PDNs inductively learn an aggregated weight for each edge, optimized to produce the best outcome for the downstream learning task. PDNs are a generalization of attention mechanisms on graphs which allow flexible construction of similarity functions between nodes, edge convolutions, and cheap multiscale mixing layers. We show that PDNs overcome weaknesses of existing methods for graph attention (e.g. Graph Attention Networks), such as the diminishing weight problem. Our experimental results demonstrate competitive predictive performance on academic node classification tasks. Additional results from a challenging suite of node classification experiments show how PDNs can learn a wider class of functions than existing baselines. We analyze the relative computational complexity of PDNs, and show that PDN runtime is not considerably higher than static-graph models. Finally, we discuss how PDNs can be used to construct an easily interpretable attention mechanism that allows users to understand information propagation in the graph.
Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments
Oct 22, 2020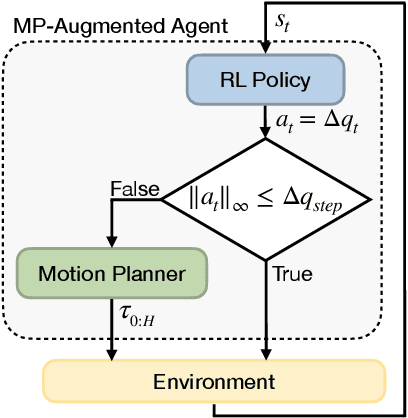

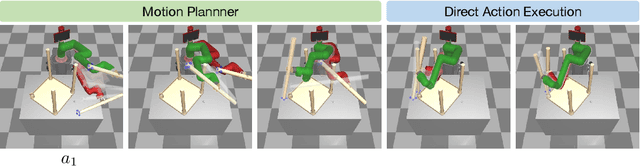

Deep reinforcement learning (RL) agents are able to learn contact-rich manipulation tasks by maximizing a reward signal, but require large amounts of experience, especially in environments with many obstacles that complicate exploration. In contrast, motion planners use explicit models of the agent and environment to plan collision-free paths to faraway goals, but suffer from inaccurate models in tasks that require contacts with the environment. To combine the benefits of both approaches, we propose motion planner augmented RL (MoPA-RL) which augments the action space of an RL agent with the long-horizon planning capabilities of motion planners. Based on the magnitude of the action, our approach smoothly transitions between directly executing the action and invoking a motion planner. We evaluate our approach on various simulated manipulation tasks and compare it to alternative action spaces in terms of learning efficiency and safety. The experiments demonstrate that MoPA-RL increases learning efficiency, leads to a faster exploration, and results in safer policies that avoid collisions with the environment. Videos and code are available at https://clvrai.com/mopa-rl .
Learning Equality Constraints for Motion Planning on Manifolds
Sep 24, 2020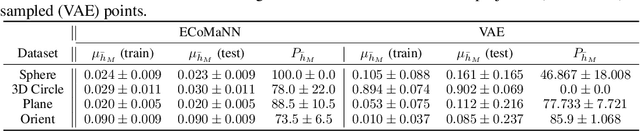
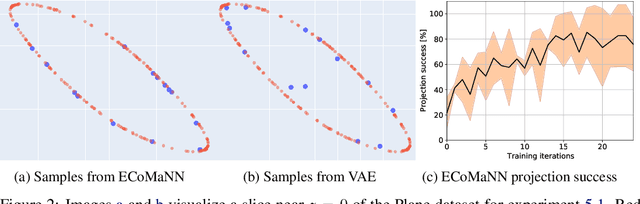

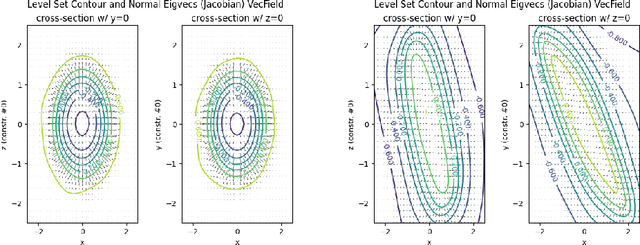
Constrained robot motion planning is a widely used technique to solve complex robot tasks. We consider the problem of learning representations of constraints from demonstrations with a deep neural network, which we call Equality Constraint Manifold Neural Network (ECoMaNN). The key idea is to learn a level-set function of the constraint suitable for integration into a constrained sampling-based motion planner. Learning proceeds by aligning subspaces in the network with subspaces of the data. We combine both learned constraints and analytically described constraints into the planner and use a projection-based strategy to find valid points. We evaluate ECoMaNN on its representation capabilities of constraint manifolds, the impact of its individual loss terms, and the motions produced when incorporated into a planner.
Learning Manifolds for Sequential Motion Planning
Jul 04, 2020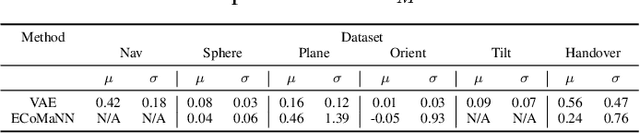

Motion planning with constraints is an important part of many real-world robotic systems. In this work, we study manifold learning methods to learn such constraints from data. We explore two methods for learning implicit constraint manifolds from data: Variational Autoencoders (VAE), and a new method, Equality Constraint Manifold Neural Network (ECoMaNN). With the aim of incorporating learned constraints into a sampling-based motion planning framework, we evaluate the approaches on their ability to learn representations of constraints from various datasets and on the quality of paths produced during planning.
Sampling-Based Motion Planning on Manifold Sequences
Jun 03, 2020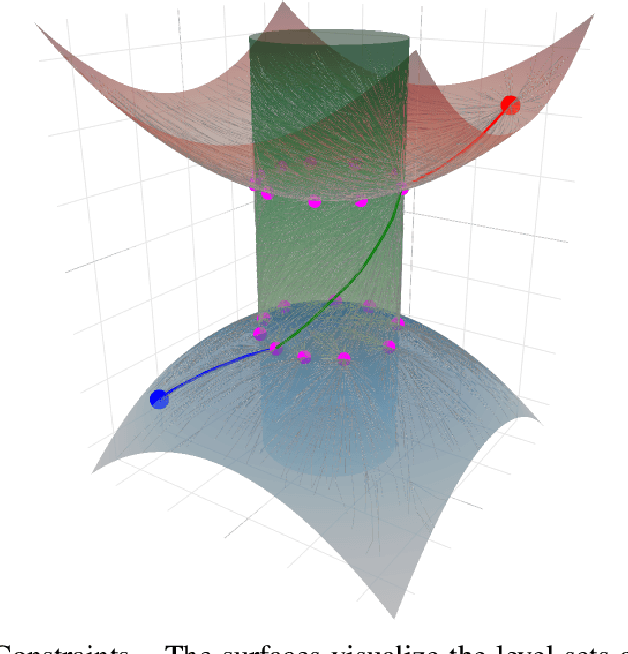
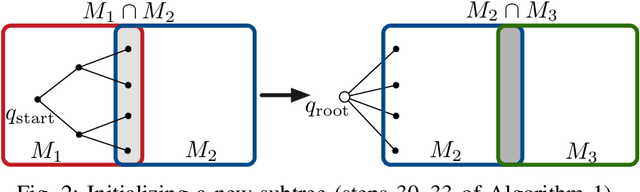
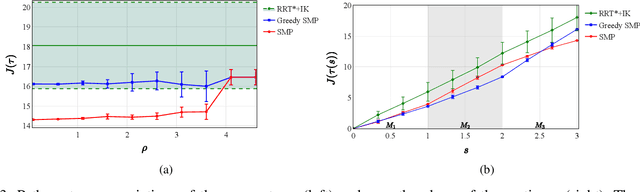
We address the problem of planning robot motions in constrained configuration spaces where the constraints change throughout the motion. A novel problem formulation is introduced that describes a task as a sequence of intersecting manifolds, which the robot needs to traverse in order to solve the task. We specify a class of sequential motion planning problems that fulfill a particular property of the change in the free configuration space when transitioning between manifolds. For this problem class, a sequential motion planning algorithm SMP is developed that searches for optimal intersection points between manifolds by using RRT* in an inner loop with a novel steering strategy. We provide a theoretical analysis regarding its probabilistic completeness and demonstrate its performance on kinematic planning problems where the constraints are represented as geometric primitives. Further, we show its capabilities on solving multi-robot object transportation tasks.
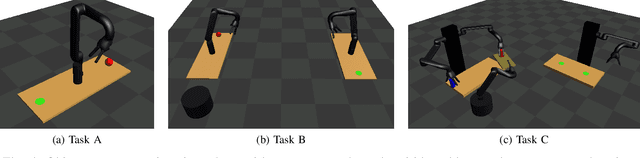
Kinematic Morphing Networks for Manipulation Skill Transfer
Mar 05, 2018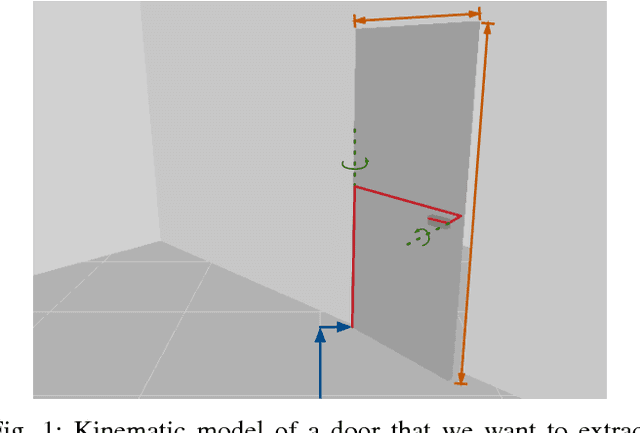
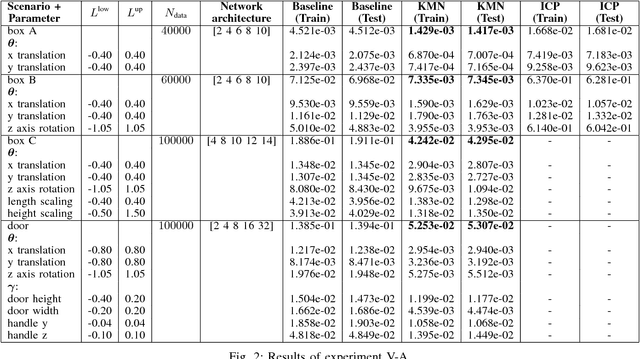
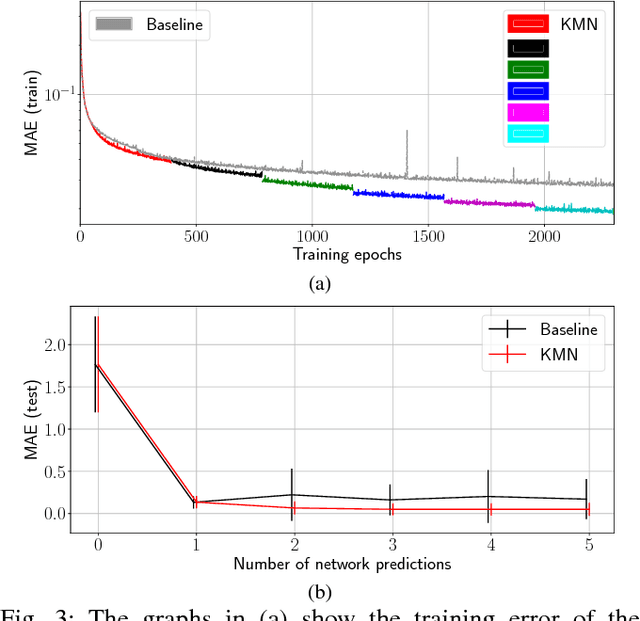

The transfer of a robot skill between different geometric environments is non-trivial since a wide variety of environments exists, sensor observations as well as robot motions are high-dimensional, and the environment might only be partially observed. We consider the problem of extracting a low-dimensional description of the manipulated environment in form of a kinematic model. This allows us to transfer a skill by defining a policy on a prototype model and morphing the observed environment to this prototype. A deep neural network is used to map depth image observations of the environment to morphing parameter, which include transformation and configuration parameters of the prototype model. Using the concatenation property of affine transformations and the ability to convert point clouds to depth images allows to apply the network in an iterative manner. The network is trained on data generated in a simulator and on augmented data that is created by using network predictions. The algorithm is evaluated on different tasks, where it is shown that iterative predictions lead to a higher accuracy than one-step predictions.
Identification of Unmodeled Objects from Symbolic Descriptions
Jan 23, 2017


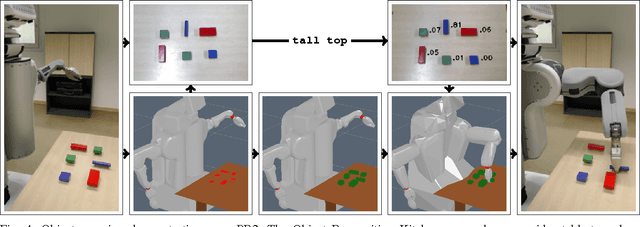
Successful human-robot cooperation hinges on each agent's ability to process and exchange information about the shared environment and the task at hand. Human communication is primarily based on symbolic abstractions of object properties, rather than precise quantitative measures. A comprehensive robotic framework thus requires an integrated communication module which is able to establish a link and convert between perceptual and abstract information. The ability to interpret composite symbolic descriptions enables an autonomous agent to a) operate in unstructured and cluttered environments, in tasks which involve unmodeled or never seen before objects; and b) exploit the aggregation of multiple symbolic properties as an instance of ensemble learning, to improve identification performance even when the individual predicates encode generic information or are imprecisely grounded. We propose a discriminative probabilistic model which interprets symbolic descriptions to identify the referent object contextually w.r.t.\ the structure of the environment and other objects. The model is trained using a collected dataset of identifications, and its performance is evaluated by quantitative measures and a live demo developed on the PR2 robot platform, which integrates elements of perception, object extraction, object identification and grasping.
Multi-Task Policy Search
Feb 12, 2014
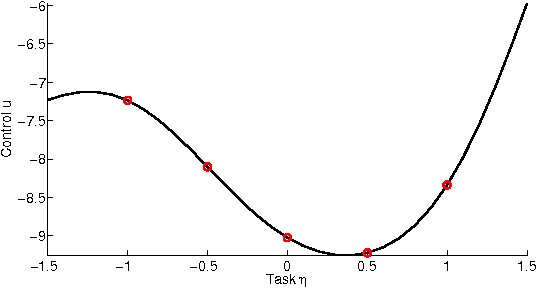

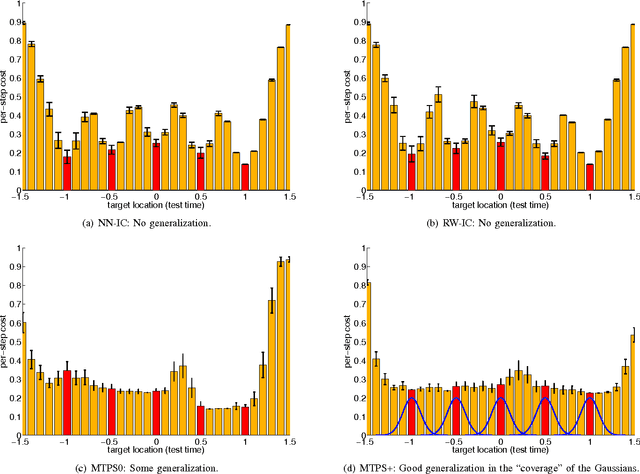
Learning policies that generalize across multiple tasks is an important and challenging research topic in reinforcement learning and robotics. Training individual policies for every single potential task is often impractical, especially for continuous task variations, requiring more principled approaches to share and transfer knowledge among similar tasks. We present a novel approach for learning a nonlinear feedback policy that generalizes across multiple tasks. The key idea is to define a parametrized policy as a function of both the state and the task, which allows learning a single policy that generalizes across multiple known and unknown tasks. Applications of our novel approach to reinforcement and imitation learning in real-robot experiments are shown.