 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoMerger: An Ontology Integration Library for Deduplicating and Connecting Knowledge Graph Nodes
Jun 05, 2022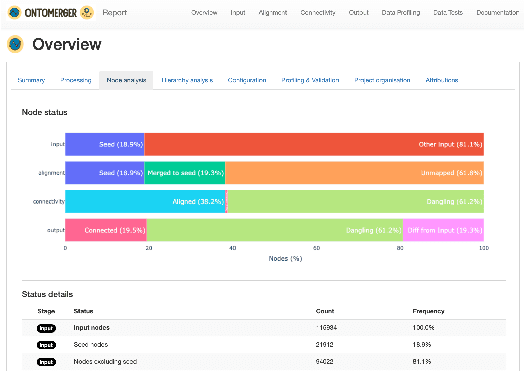

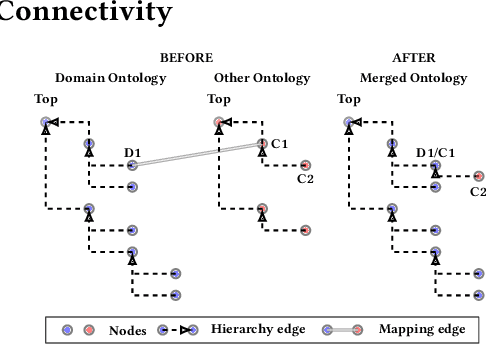

Duplication of nodes is a common problem encountered when building knowledge graphs (KGs) from heterogeneous datasets, where it is crucial to be able to merge nodes having the same meaning. OntoMerger is a Python ontology integration library whose functionality is to deduplicate KG nodes. Our approach takes a set of KG nodes, mappings and disconnected hierarchies and generates a set of merged nodes together with a connected hierarchy. In addition, the library provides analytic and data testing functionalities that can be used to fine-tune the inputs, further reducing duplication, and to increase connectivity of the output graph. OntoMerger can be applied to a wide variety of ontologies and KGs. In this paper we introduce OntoMerger and illustrate its functionality on a real-world biomedical KG.
TigerLily: Finding drug interactions in silico with the Graph
Apr 18, 2022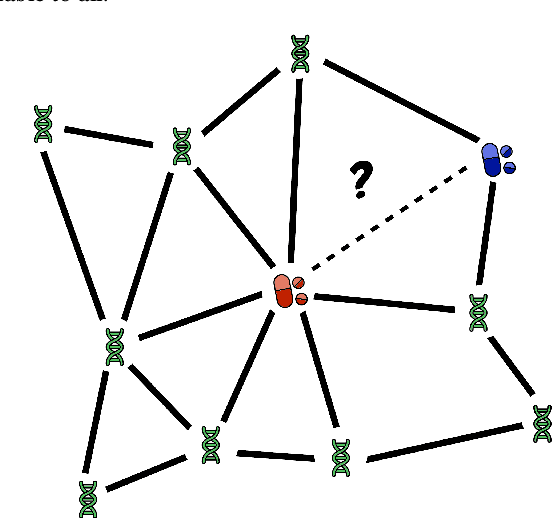



Tigerlily is a TigerGraph based system designed to solve the drug interaction prediction task. In this machine learning task, we want to predict whether two drugs have an adverse interaction. Our framework allows us to solve this highly relevant real-world problem using graph mining techniques in these steps: (a) Using PyTigergraph we create a heterogeneous biological graph of drugs and proteins. (b) We calculate the personalized PageRank scores of drug nodes in the TigerGraph Cloud. (c) We embed the nodes using sparse non-negative matrix factorization of the personalized PageRank matrix. (d) Using the node embeddings we train a gradient boosting based drug interaction predictor.
Synthetic Graph Generation to Benchmark Graph Learning
Apr 04, 2022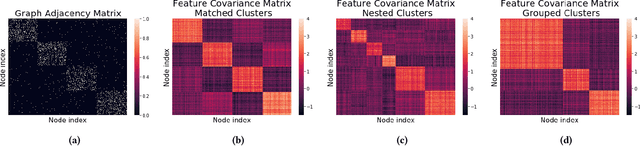
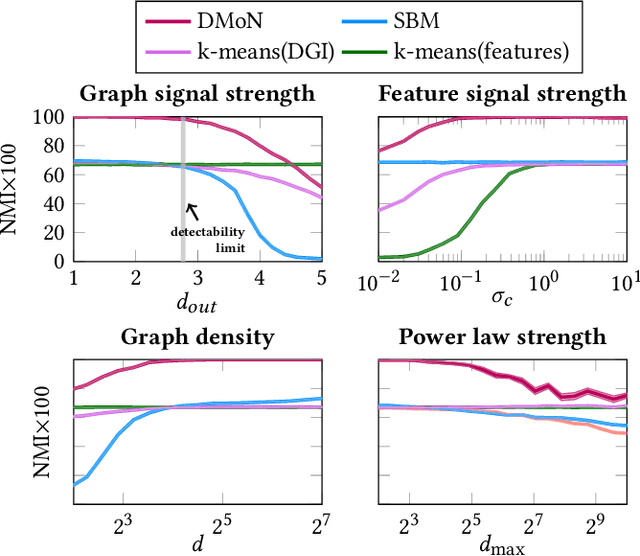
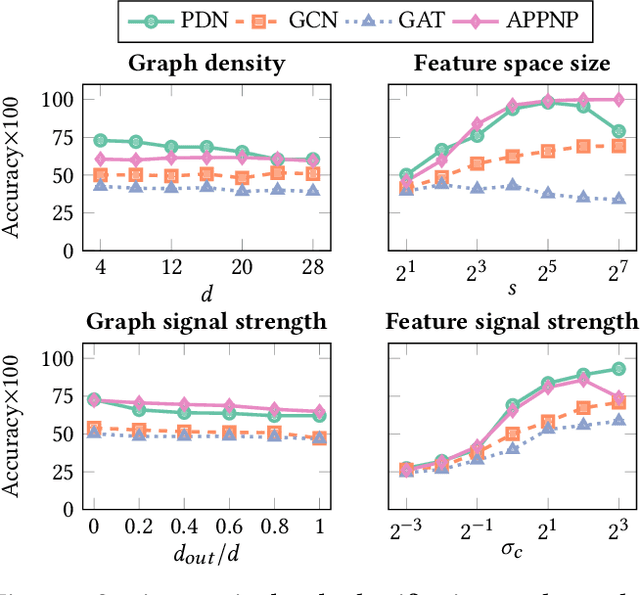
Graph learning algorithms have attained state-of-the-art performance on many graph analysis tasks such as node classification, link prediction, and clustering. It has, however, become hard to track the field's burgeoning progress. One reason is due to the very small number of datasets used in practice to benchmark the performance of graph learning algorithms. This shockingly small sample size (~10) allows for only limited scientific insight into the problem. In this work, we aim to address this deficiency. We propose to generate synthetic graphs, and study the behaviour of graph learning algorithms in a controlled scenario. We develop a fully-featured synthetic graph generator that allows deep inspection of different models. We argue that synthetic graph generations allows for thorough investigation of algorithms and provides more insights than overfitting on three citation datasets. In the case study, we show how our framework provides insight into unsupervised and supervised graph neural network models.
Continual and Sliding Window Release for Private Empirical Risk Minimization
Mar 07, 2022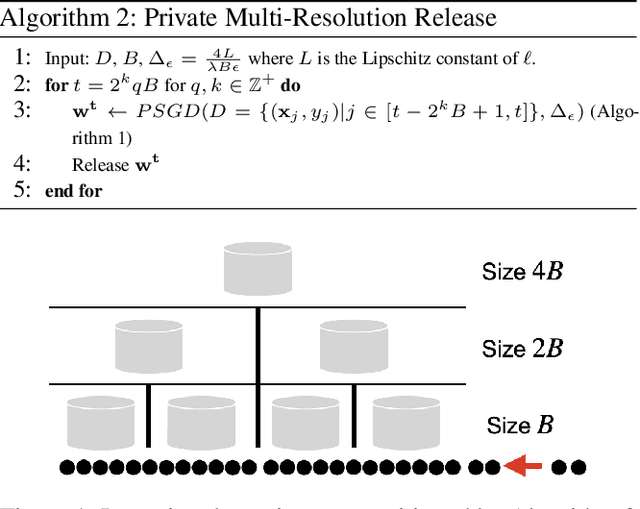
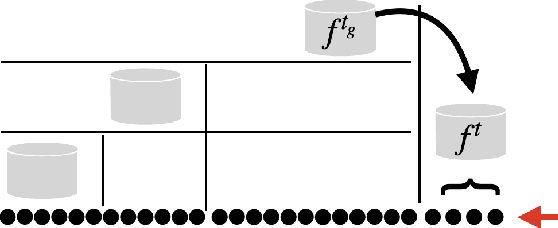
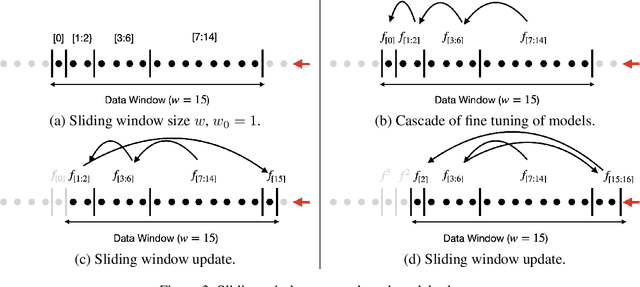
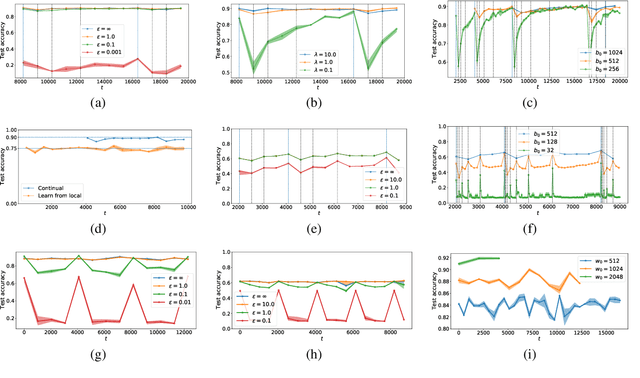
It is difficult to continually update private machine learning models with new data while maintaining privacy. Data incur increasing privacy loss -- as measured by differential privacy -- when they are used in repeated computations. In this paper, we describe regularized empirical risk minimization algorithms that continually release models for a recent window of data. One version of the algorithm uses the entire data history to improve the model for the recent window. The second version uses a sliding window of constant size to improve the model, ensuring more relevant models in case of evolving data. The algorithms operate in the framework of stochastic gradient descent. We prove that even with releasing a model at each time-step over an infinite time horizon, the privacy cost of any data point is bounded by a constant $\epsilon$ differential privacy, and the accuracy of the output models are close to optimal. Experiments on MNIST and Arxiv publications data show results consistent with the theory.
ChemicalX: A Deep Learning Library for Drug Pair Scoring
Feb 14, 2022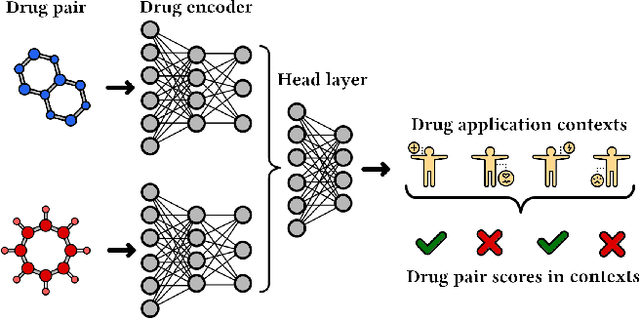
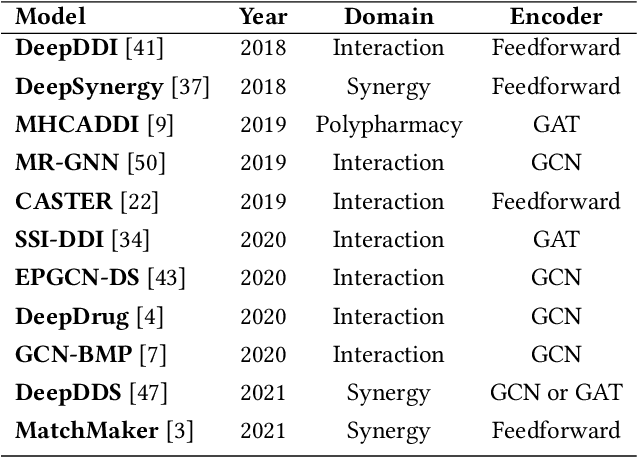
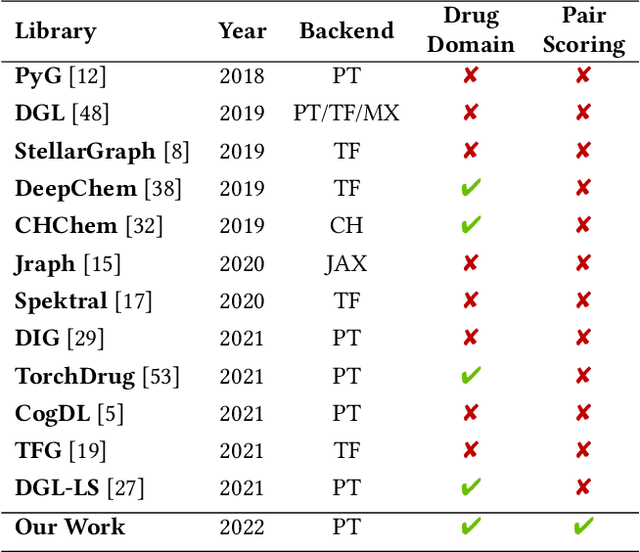
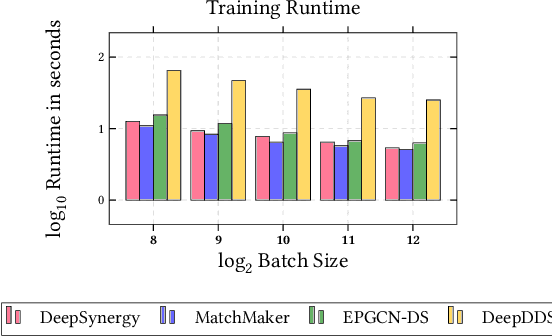
In this paper, we introduce ChemicalX, a PyTorch-based deep learning library designed for providing a range of state of the art models to solve the drug pair scoring task. The primary objective of the library is to make deep drug pair scoring models accessible to machine learning researchers and practitioners in a streamlined framework.The design of ChemicalX reuses existing high level model training utilities, geometric deep learning, and deep chemistry layers from the PyTorch ecosystem. Our system provides neural network layers, custom pair scoring architectures, data loaders, and batch iterators for end users. We showcase these features with example code snippets and case studies to highlight the characteristics of ChemicalX. A range of experiments on real world drug-drug interaction, polypharmacy side effect, and combination synergy prediction tasks demonstrate that the models available in ChemicalX are effective at solving the pair scoring task. Finally, we show that ChemicalX could be used to train and score machine learning models on large drug pair datasets with hundreds of thousands of compounds on commodity hardware.
The Shapley Value in Machine Learning
Feb 11, 2022
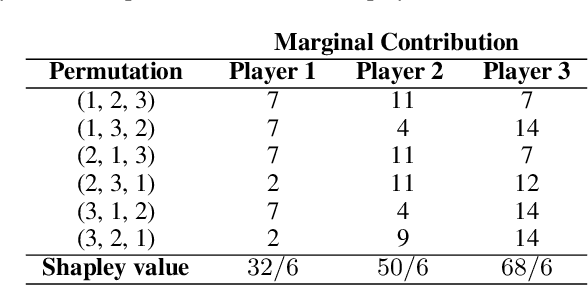
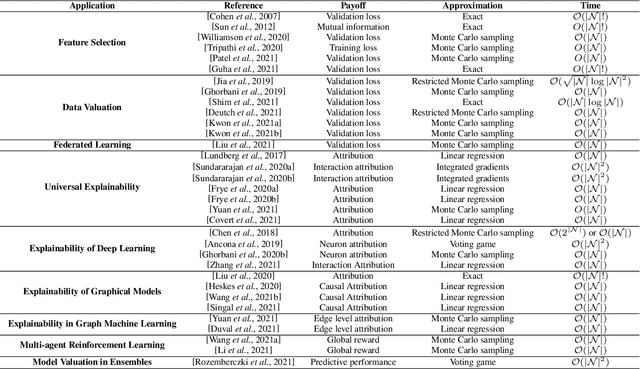
Over the last few years, the Shapley value, a solution concept from cooperative game theory, has found numerous applications in machine learning. In this paper, we first discuss fundamental concepts of cooperative game theory and axiomatic properties of the Shapley value. Then we give an overview of the most important applications of the Shapley value in machine learning: feature selection, explainability, multi-agent reinforcement learning, ensemble pruning, and data valuation. We examine the most crucial limitations of the Shapley value and point out directions for future research.
Explainable Biomedical Recommendations via Reinforcement Learning Reasoning on Knowledge Graphs
Nov 20, 2021



For Artificial Intelligence to have a greater impact in biology and medicine, it is crucial that recommendations are both accurate and transparent. In other domains, a neurosymbolic approach of multi-hop reasoning on knowledge graphs has been shown to produce transparent explanations. However, there is a lack of research applying it to complex biomedical datasets and problems. In this paper, the approach is explored for drug discovery to draw solid conclusions on its applicability. For the first time, we systematically apply it to multiple biomedical datasets and recommendation tasks with fair benchmark comparisons. The approach is found to outperform the best baselines by 21.7% on average whilst producing novel, biologically relevant explanations.
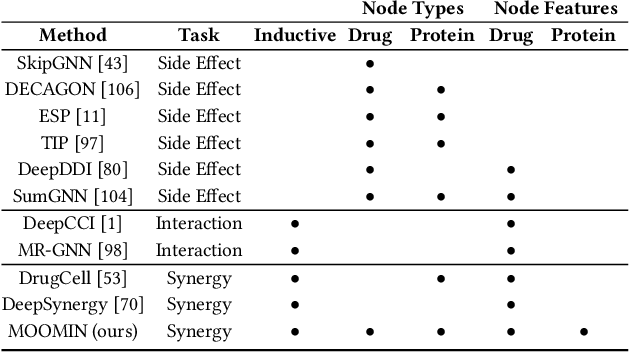
A Unified View of Relational Deep Learning for Drug Pair Scoring
Nov 14, 2021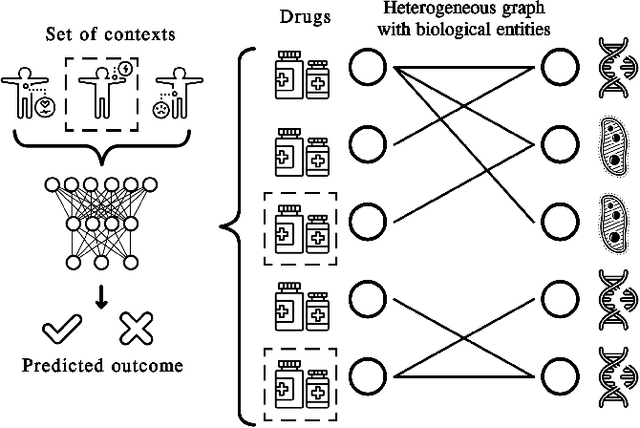
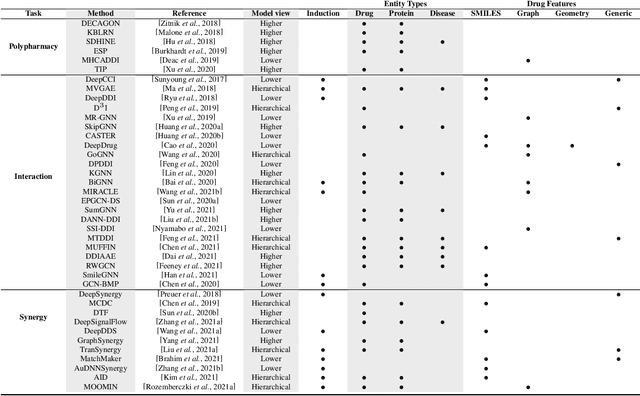
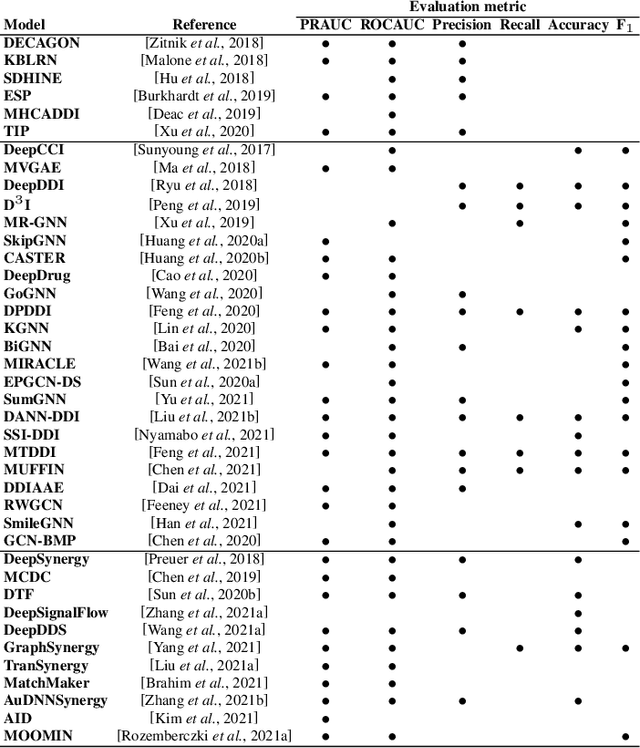
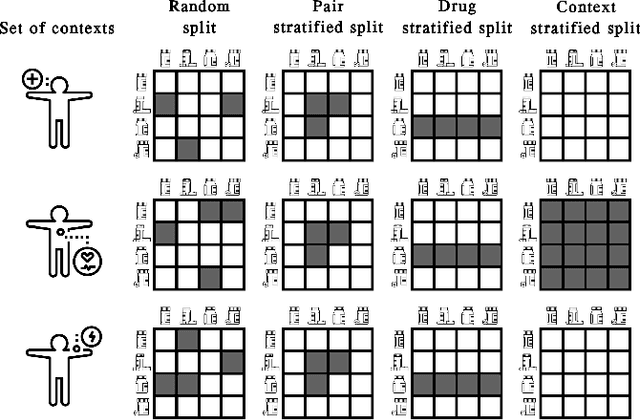
In recent years, numerous machine learning models which attempt to solve polypharmacy side effect identification, drug-drug interaction prediction and combination therapy design tasks have been proposed. Here, we present a unified theoretical view of relational machine learning models which can address these tasks. We provide fundamental definitions, compare existing model architectures and discuss performance metrics, datasets and evaluation protocols. In addition, we emphasize possible high impact applications and important future research directions in this domain.
MOOMIN: Deep Molecular Omics Network for Anti-Cancer Drug Combination Therapy
Oct 28, 2021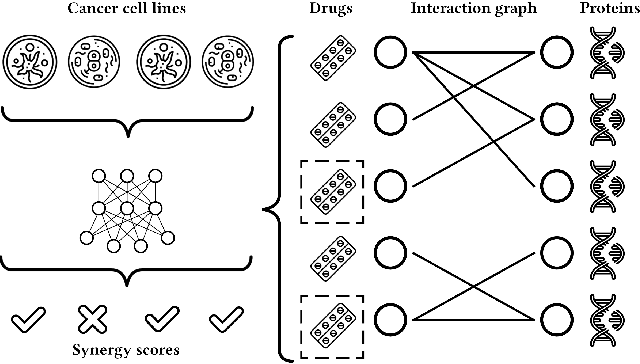

We propose the molecular omics network (MOOMIN) a multimodal graph neural network that can predict the synergistic effect of drug combinations for cancer treatment. Our model captures the representation based on the context of drugs at multiple scales based on a drug-protein interaction network and metadata. Structural properties of the compounds and proteins are encoded to create vertex features for a message-passing scheme that operates on the bipartite interaction graph. Propagated messages form multi-resolution drug representations which we utilized to create drug pair descriptors. By conditioning the drug combination representations on the cancer cell type we define a synergy scoring function that can inductively score unseen pairs of drugs. Experimental results on the synergy scoring task demonstrate that MOOMIN outperforms state-of-the-art graph fingerprinting, proximity preserving node embedding, and existing deep learning approaches. Further results establish that the predictive performance of our model is robust to hyperparameter changes. We demonstrate that the model makes high-quality predictions over a wide range of cancer cell line tissues, out-of-sample predictions can be validated with external synergy databases, and that the proposed model is data-efficient at learning.
PyTorch Geometric Temporal: Spatiotemporal Signal Processing with Neural Machine Learning Models
Apr 30, 2021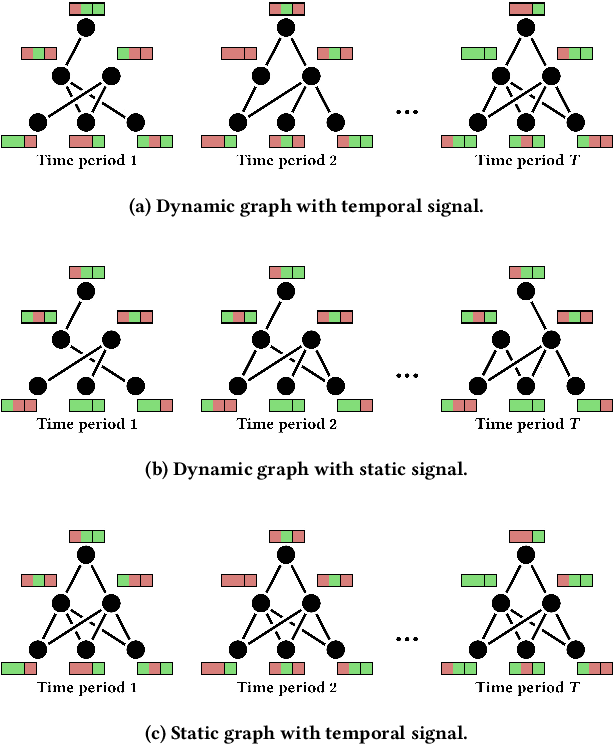
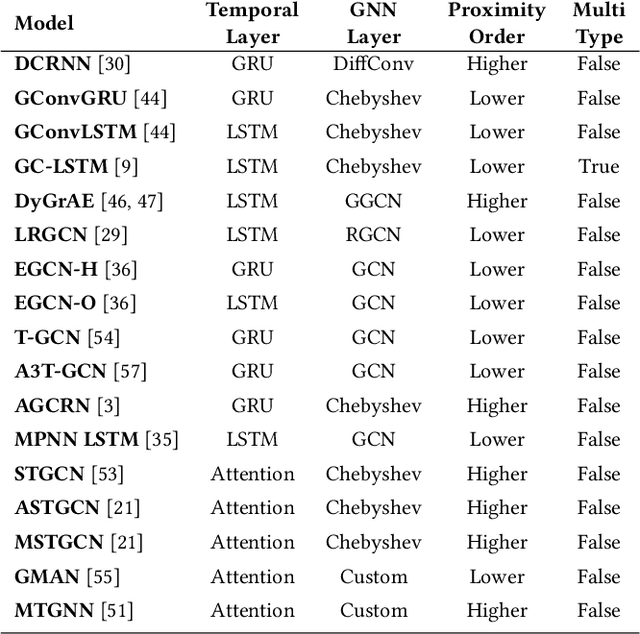
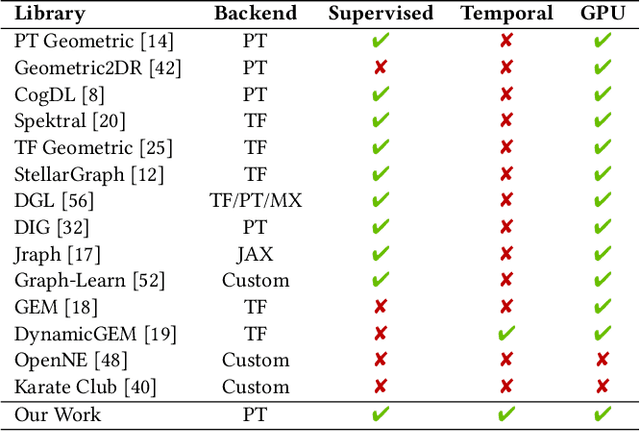
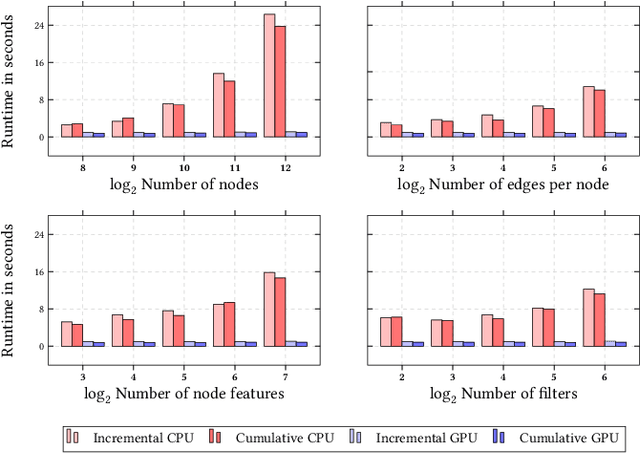
We present PyTorch Geometric Temporal a deep learning framework combining state-of-the-art machine learning algorithms for neural spatiotemporal signal processing. The main goal of the library is to make temporal geometric deep learning available for researchers and machine learning practitioners in a unified easy-to-use framework. PyTorch Geometric Temporal was created with foundations on existing libraries in the PyTorch eco-system, streamlined neural network layer definitions, temporal snapshot generators for batching, and integrated benchmark datasets. These features are illustrated with a tutorial-like case study. Experiments demonstrate the predictive performance of the models implemented in the library on real world problems such as epidemiological forecasting, ridehail demand prediction and web-traffic management. Our sensitivity analysis of runtime shows that the framework can potentially operate on web-scale datasets with rich temporal features and spatial structure.