 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Reasoning in Large Audio-Language Models for Ambiguous Emotion Prediction
Mar 09, 2026Speech emotion recognition plays an important role in various applications. However, most existing approaches predict a single emotion label, oversimplifying the inherently ambiguous nature of human emotional expression. Recent large audio-language models show promise in generating richer outputs, but their reasoning ability for ambiguous emotional understanding remains limited. In this work, we reformulate ambiguous emotion recognition as a distributional reasoning problem and present the first systematic study of ambiguity-aware reasoning in LALMs. Our framework comprises two complementary components: an ambiguity-aware objective that aligns predictions with human perceptual distributions, and a structured ambiguity-aware chain-of-thought supervision that guides reasoning over emotional cues. Experiments on IEMOCAP and CREMA-D demonstrate consistent improvements across SFT, DPO, and GRPO training strategies.
E-BATS: Efficient Backpropagation-Free Test-Time Adaptation for Speech Foundation Models
Jun 08, 2025



Speech Foundation Models encounter significant performance degradation when deployed in real-world scenarios involving acoustic domain shifts, such as background noise and speaker accents. Test-time adaptation (TTA) has recently emerged as a viable strategy to address such domain shifts at inference time without requiring access to source data or labels. However, existing TTA approaches, particularly those relying on backpropagation, are memory-intensive, limiting their applicability in speech tasks and resource-constrained settings. Although backpropagation-free methods offer improved efficiency, existing ones exhibit poor accuracy. This is because they are predominantly developed for vision tasks, which fundamentally differ from speech task formulations, noise characteristics, and model architecture, posing unique transferability challenges. In this paper, we introduce E-BATS, the first Efficient BAckpropagation-free TTA framework designed explicitly for speech foundation models. E-BATS achieves a balance between adaptation effectiveness and memory efficiency through three key components: (i) lightweight prompt adaptation for a forward-pass-based feature alignment, (ii) a multi-scale loss to capture both global (utterance-level) and local distribution shifts (token-level) and (iii) a test-time exponential moving average mechanism for stable adaptation across utterances. Experiments conducted on four noisy speech datasets spanning sixteen acoustic conditions demonstrate consistent improvements, with 4.1%-13.5% accuracy gains over backpropagation-free baselines and 2.0-6.4 times GPU memory savings compared to backpropagation-based methods. By enabling scalable and robust adaptation under acoustic variability, this work paves the way for developing more efficient adaptation approaches for practical speech processing systems in real-world environments.
BoTTA: Benchmarking on-device Test Time Adaptation
Apr 16, 2025The performance of deep learning models depends heavily on test samples at runtime, and shifts from the training data distribution can significantly reduce accuracy. Test-time adaptation (TTA) addresses this by adapting models during inference without requiring labeled test data or access to the original training set. While research has explored TTA from various perspectives like algorithmic complexity, data and class distribution shifts, model architectures, and offline versus continuous learning, constraints specific to mobile and edge devices remain underexplored. We propose BoTTA, a benchmark designed to evaluate TTA methods under practical constraints on mobile and edge devices. Our evaluation targets four key challenges caused by limited resources and usage conditions: (i) limited test samples, (ii) limited exposure to categories, (iii) diverse distribution shifts, and (iv) overlapping shifts within a sample. We assess state-of-the-art TTA methods under these scenarios using benchmark datasets and report system-level metrics on a real testbed. Furthermore, unlike prior work, we align with on-device requirements by advocating periodic adaptation instead of continuous inference-time adaptation. Experiments reveal key insights: many recent TTA algorithms struggle with small datasets, fail to generalize to unseen categories, and depend on the diversity and complexity of distribution shifts. BoTTA also reports device-specific resource use. For example, while SHOT improves accuracy by $2.25\times$ with $512$ adaptation samples, it uses $1.08\times$ peak memory on Raspberry Pi versus the base model. BoTTA offers actionable guidance for TTA in real-world, resource-constrained deployments.
Benchmarking Federated Machine Unlearning methods for Tabular Data
Apr 01, 2025



Machine unlearning, which enables a model to forget specific data upon request, is increasingly relevant in the era of privacy-centric machine learning, particularly within federated learning (FL) environments. This paper presents a pioneering study on benchmarking machine unlearning methods within a federated setting for tabular data, addressing the unique challenges posed by cross-silo FL where data privacy and communication efficiency are paramount. We explore unlearning at the feature and instance levels, employing both machine learning, random forest and logistic regression models. Our methodology benchmarks various unlearning algorithms, including fine-tuning and gradient-based approaches, across multiple datasets, with metrics focused on fidelity, certifiability, and computational efficiency. Experiments demonstrate that while fidelity remains high across methods, tree-based models excel in certifiability, ensuring exact unlearning, whereas gradient-based methods show improved computational efficiency. This study provides critical insights into the design and selection of unlearning algorithms tailored to the FL environment, offering a foundation for further research in privacy-preserving machine learning.
FLea: Addressing Data Scarcity and Label Skew in Federated Learning via Privacy-preserving Feature Augmentation
Jun 13, 2024Federated Learning (FL) enables model development by leveraging data distributed across numerous edge devices without transferring local data to a central server. However, existing FL methods still face challenges when dealing with scarce and label-skewed data across devices, resulting in local model overfitting and drift, consequently hindering the performance of the global model. In response to these challenges, we propose a pioneering framework called FLea, incorporating the following key components: i) A global feature buffer that stores activation-target pairs shared from multiple clients to support local training. This design mitigates local model drift caused by the absence of certain classes; ii) A feature augmentation approach based on local and global activation mix-ups for local training. This strategy enlarges the training samples, thereby reducing the risk of local overfitting; iii) An obfuscation method to minimize the correlation between intermediate activations and the source data, enhancing the privacy of shared features. To verify the superiority of FLea, we conduct extensive experiments using a wide range of data modalities, simulating different levels of local data scarcity and label skew. The results demonstrate that FLea consistently outperforms state-of-the-art FL counterparts (among 13 of the experimented 18 settings, the improvement is over 5% while concurrently mitigating the privacy vulnerabilities associated with shared features. Code is available at https://github.com/XTxiatong/FLea.git.
FLea: Improving federated learning on scarce and label-skewed data via privacy-preserving feature augmentation
Dec 04, 2023Learning a global model by abstracting the knowledge, distributed across multiple clients, without aggregating the raw data is the primary goal of Federated Learning (FL). Typically, this works in rounds alternating between parallel local training at several clients, followed by model aggregation at a server. We found that existing FL methods under-perform when local datasets are small and present severe label skew as these lead to over-fitting and local model bias. This is a realistic setting in many real-world applications. To address the problem, we propose \textit{FLea}, a unified framework that tackles over-fitting and local bias by encouraging clients to exchange privacy-protected features to aid local training. The features refer to activations from an intermediate layer of the model, which are obfuscated before being shared with other clients to protect sensitive information in the data. \textit{FLea} leverages a novel way of combining local and shared features as augmentations to enhance local model learning. Our extensive experiments demonstrate that \textit{FLea} outperforms the start-of-the-art FL methods, sharing only model parameters, by up to $17.6\%$, and FL methods that share data augmentations by up to $6.3\%$, while reducing the privacy vulnerability associated with shared data augmentations.
Cross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023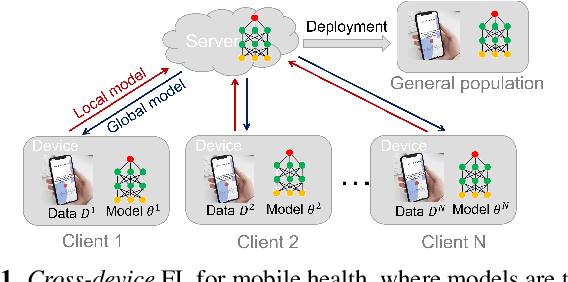
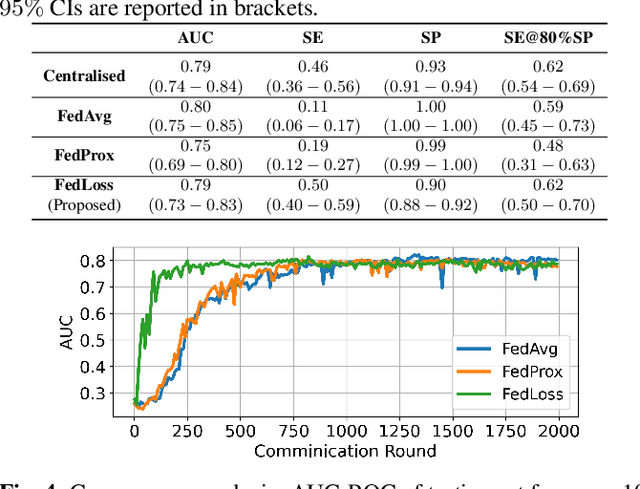
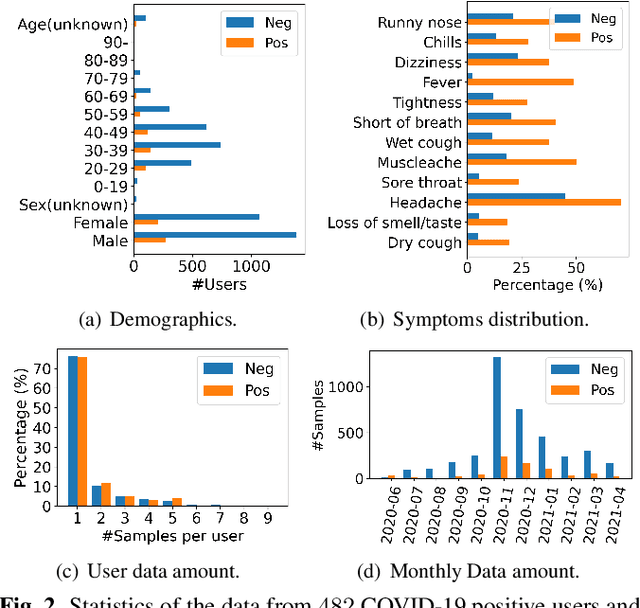
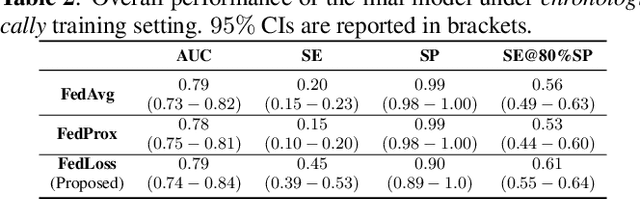
Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
Continual and Sliding Window Release for Private Empirical Risk Minimization
Mar 07, 2022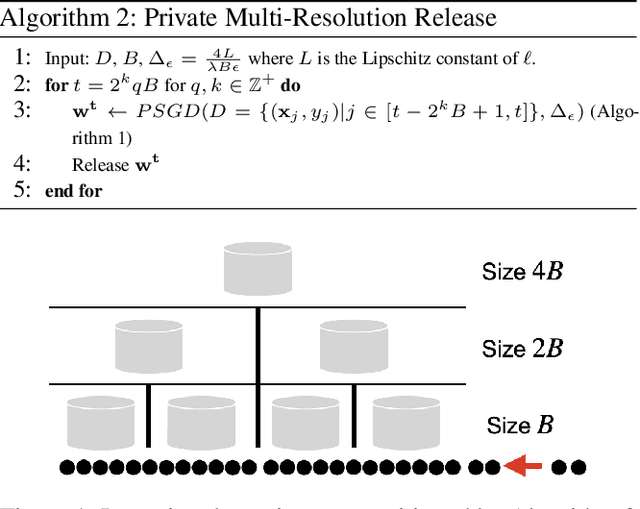
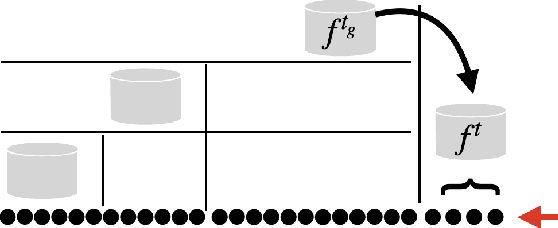
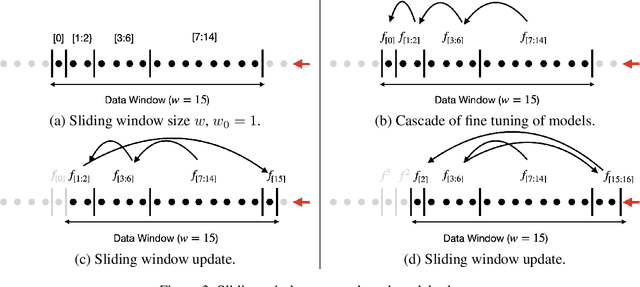
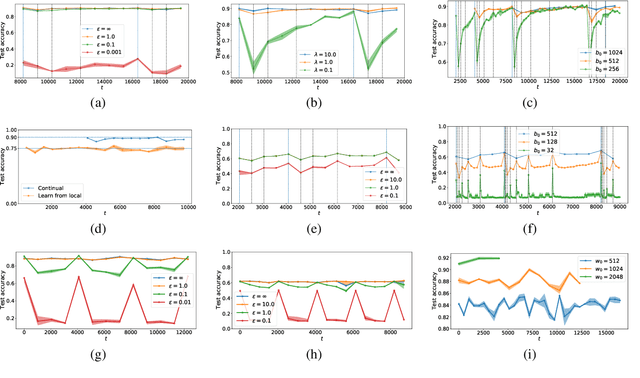
It is difficult to continually update private machine learning models with new data while maintaining privacy. Data incur increasing privacy loss -- as measured by differential privacy -- when they are used in repeated computations. In this paper, we describe regularized empirical risk minimization algorithms that continually release models for a recent window of data. One version of the algorithm uses the entire data history to improve the model for the recent window. The second version uses a sliding window of constant size to improve the model, ensuring more relevant models in case of evolving data. The algorithms operate in the framework of stochastic gradient descent. We prove that even with releasing a model at each time-step over an infinite time horizon, the privacy cost of any data point is bounded by a constant $\epsilon$ differential privacy, and the accuracy of the output models are close to optimal. Experiments on MNIST and Arxiv publications data show results consistent with the theory.