 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPTOOD: Uncertainty-Aware Fine-Tuning for Out-of-Distribution ECG Time Series Models
Jun 02, 2026Data samples used for training often differ from those encountered during fine-tuning and deployment, and while ML models show promise, their performance remains limited when only small annotated datasets are available. Performance often degrades under distribution shifts caused by diverse sensors, populations, and application settings. Although pre-training helps, models frequently encounter out-of-distribution (OOD) data in real-world settings, leading to reduced robustness. Existing adaptation methods usually assume fixed distribution shifts and struggle when multiple types or severities occur. In particular, they overlook shift severity, for example treating adaptation to a large familiar dataset the same as adaptation to a small dataset with a new task, which limits generalisation. To address this, we propose ADAPTOOD, a novel framework that leverages data uncertainty to quantify distribution shift severity and guide fine-tuning for time series. This uncertainty measures how strongly samples from the target deployment distribution deviate from the pre-training distribution, providing a direct signal of OOD severity. Our framework combines this uncertainty with low-rank model updates and adaptive hyperparameter optimisation to improve adaptation. We show that ADAPTOOD achieves up to 7% higher accuracy and 12.9% higher precision than existing methods in OOD tasks, maintaining strong performance as distribution shift severity increases.
Wearable Foundation Models Should Go Beyond Static Encoders
Mar 20, 2026Wearable foundation models (WFMs), trained on large volumes of data collected by affordable, always-on devices, have demonstrated strong performance on short-term, well-defined health monitoring tasks, including activity recognition, fitness tracking, and cardiovascular signal assessment. However, most existing WFMs primarily map short temporal windows to predefined labels via static encoders, emphasizing retrospective prediction rather than reasoning over evolving personal history, context, and future risk trajectories. As a result, they are poorly suited for modeling chronic, progressive, or episodic health conditions that unfold over weeks, months or years. Hence, we argue that WFMs must move beyond static encoders and be explicitly designed for longitudinal, anticipatory health reasoning. We identify three foundational shifts required to enable this transition: (1) Structurally rich data, which goes beyond isolated datasets or outcome-conditioned collection to integrated multimodal, long-term personal trajectories, and contextual metadata, ideally supported by open and interoperable data ecosystems; (2) Longitudinal-aware multimodal modeling, which prioritizes long-context inference, temporal abstraction, and personalization over cross-sectional or population-level prediction; and (3) Agentic inference systems, which move beyond static prediction to support planning, decision-making, and clinically grounded intervention under uncertainty. Together, these shifts reframe wearable health monitoring from retrospective signal interpretation toward continuous, anticipatory, and human-aligned health support.
Tempora: Characterising the Time-Contingent Utility of Online Test-Time Adaptation
Feb 05, 2026Test-time adaptation (TTA) offers a compelling remedy for machine learning (ML) models that degrade under domain shifts, improving generalisation on-the-fly with only unlabelled samples. This flexibility suits real deployments, yet conventional evaluations unrealistically assume unbounded processing time, overlooking the accuracy-latency trade-off. As ML increasingly underpins latency-sensitive and user-facing use-cases, temporal pressure constrains the viability of adaptable inference; predictions arriving too late to act on are futile. We introduce Tempora, a framework for evaluating TTA under this pressure. It consists of temporal scenarios that model deployment constraints, evaluation protocols that operationalise measurement, and time-contingent utility metrics that quantify the accuracy-latency trade-off. We instantiate the framework with three such metrics: (1) discrete utility for asynchronous streams with hard deadlines, (2) continuous utility for interactive settings where value decays with latency, and (3) amortised utility for budget-constrained deployments. Applying Tempora to seven TTA methods on ImageNet-C across 240 temporal evaluations reveals rank instability: conventional rankings do not predict rankings under temporal pressure; ETA, a state-of-the-art method in the conventional setting, falls short in 41.2% of evaluations. The highest-utility method varies with corruption type and temporal pressure, with no clear winner. By enabling systematic evaluation across diverse temporal constraints for the first time, Tempora reveals when and why rankings invert, offering practitioners a lens for method selection and researchers a target for deployable adaptation.
Rethinking Large Language Models For Irregular Time Series Classification In Critical Care
Jan 26, 2026Time series data from the Intensive Care Unit (ICU) provides critical information for patient monitoring. While recent advancements in applying Large Language Models (LLMs) to time series modeling (TSM) have shown great promise, their effectiveness on the irregular ICU data, characterized by particularly high rates of missing values, remains largely unexplored. This work investigates two key components underlying the success of LLMs for TSM: the time series encoder and the multimodal alignment strategy. To this end, we establish a systematic testbed to evaluate their impact across various state-of-the-art LLM-based methods on benchmark ICU datasets against strong supervised and self-supervised baselines. Results reveal that the encoder design is more critical than the alignment strategy. Encoders that explicitly model irregularity achieve substantial performance gains, yielding an average AUPRC increase of $12.8\%$ over the vanilla Transformer. While less impactful, the alignment strategy is also noteworthy, with the best-performing semantically rich, fusion-based strategy achieving a modest $2.9\%$ improvement over cross-attention. However, LLM-based methods require at least 10$\times$ longer training than the best-performing irregular supervised models, while delivering only comparable performance. They also underperform in data-scarce few-shot learning settings. These findings highlight both the promise and current limitations of LLMs for irregular ICU time series. The code is available at https://github.com/mHealthUnimelb/LLMTS.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
LeanTTA: A Backpropagation-Free and Stateless Approach to Quantized Test-Time Adaptation on Edge Devices
Mar 20, 2025While there are many advantages to deploying machine learning models on edge devices, the resource constraints of mobile platforms, the dynamic nature of the environment, and differences between the distribution of training versus in-the-wild data make such deployments challenging. Current test-time adaptation methods are often memory-intensive and not designed to be quantization-compatible or deployed on low-resource devices. To address these challenges, we present LeanTTA, a novel backpropagation-free and stateless framework for quantized test-time adaptation tailored to edge devices. Our approach minimizes computational costs by dynamically updating normalization statistics without backpropagation, which frees LeanTTA from the common pitfall of relying on large batches and historical data, making our method robust to realistic deployment scenarios. Our approach is the first to enable further computational gains by combining partial adaptation with quantized module fusion. We validate our framework across sensor modalities, demonstrating significant improvements over state-of-the-art TTA methods, including a 15.7% error reduction, peak memory usage of only 11.2MB for ResNet18, and fast adaptation within an order-of-magnitude of normal inference speeds on-device. LeanTTA provides a robust solution for achieving the right trade offs between accuracy and system efficiency in edge deployments, addressing the unique challenges posed by limited data and varied operational conditions.
Electrocardiogram-Language Model for Few-Shot Question Answering with Meta Learning
Oct 18, 2024Electrocardiogram (ECG) interpretation requires specialized expertise, often involving synthesizing insights from ECG signals with complex clinical queries posed in natural language. The scarcity of labeled ECG data coupled with the diverse nature of clinical inquiries presents a significant challenge for developing robust and adaptable ECG diagnostic systems. This work introduces a novel multimodal meta-learning method for few-shot ECG question answering, addressing the challenge of limited labeled data while leveraging the rich knowledge encoded within large language models (LLMs). Our LLM-agnostic approach integrates a pre-trained ECG encoder with a frozen LLM (e.g., LLaMA and Gemma) via a trainable fusion module, enabling the language model to reason about ECG data and generate clinically meaningful answers. Extensive experiments demonstrate superior generalization to unseen diagnostic tasks compared to supervised baselines, achieving notable performance even with limited ECG leads. For instance, in a 5-way 5-shot setting, our method using LLaMA-3.1-8B achieves accuracy of 84.6%, 77.3%, and 69.6% on single verify, choose and query question types, respectively. These results highlight the potential of our method to enhance clinical ECG interpretation by combining signal processing with the nuanced language understanding capabilities of LLMs, particularly in data-constrained scenarios.
StatioCL: Contrastive Learning for Time Series via Non-Stationary and Temporal Contrast
Oct 14, 2024Contrastive learning (CL) has emerged as a promising approach for representation learning in time series data by embedding similar pairs closely while distancing dissimilar ones. However, existing CL methods often introduce false negative pairs (FNPs) by neglecting inherent characteristics and then randomly selecting distinct segments as dissimilar pairs, leading to erroneous representation learning, reduced model performance, and overall inefficiency. To address these issues, we systematically define and categorize FNPs in time series into semantic false negative pairs and temporal false negative pairs for the first time: the former arising from overlooking similarities in label categories, which correlates with similarities in non-stationarity and the latter from neglecting temporal proximity. Moreover, we introduce StatioCL, a novel CL framework that captures non-stationarity and temporal dependency to mitigate both FNPs and rectify the inaccuracies in learned representations. By interpreting and differentiating non-stationary states, which reflect the correlation between trends or temporal dynamics with underlying data patterns, StatioCL effectively captures the semantic characteristics and eliminates semantic FNPs. Simultaneously, StatioCL establishes fine-grained similarity levels based on temporal dependencies to capture varying temporal proximity between segments and to mitigate temporal FNPs. Evaluated on real-world benchmark time series classification datasets, StatioCL demonstrates a substantial improvement over state-of-the-art CL methods, achieving a 2.9% increase in Recall and a 19.2% reduction in FNPs. Most importantly, StatioCL also shows enhanced data efficiency and robustness against label scarcity.
RespLLM: Unifying Audio and Text with Multimodal LLMs for Generalized Respiratory Health Prediction
Oct 07, 2024
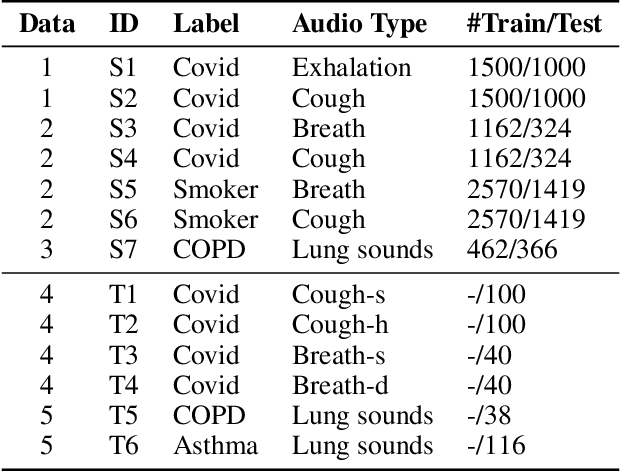
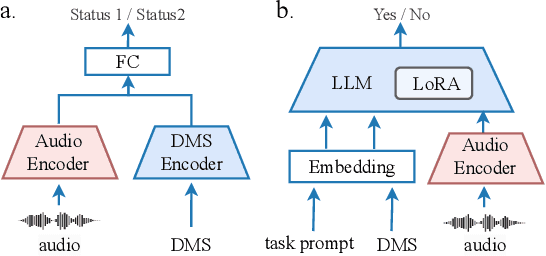
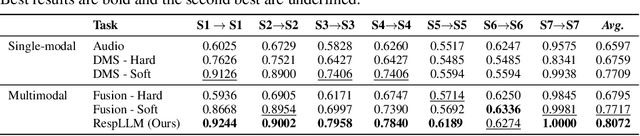
The high incidence and mortality rates associated with respiratory diseases underscores the importance of early screening. Machine learning models can automate clinical consultations and auscultation, offering vital support in this area. However, the data involved, spanning demographics, medical history, symptoms, and respiratory audio, are heterogeneous and complex. Existing approaches are insufficient and lack generalizability, as they typically rely on limited training data, basic fusion techniques, and task-specific models. In this paper, we propose RespLLM, a novel multimodal large language model (LLM) framework that unifies text and audio representations for respiratory health prediction. RespLLM leverages the extensive prior knowledge of pretrained LLMs and enables effective audio-text fusion through cross-modal attentions. Instruction tuning is employed to integrate diverse data from multiple sources, ensuring generalizability and versatility of the model. Experiments on five real-world datasets demonstrate that RespLLM outperforms leading baselines by an average of 4.6% on trained tasks, 7.9% on unseen datasets, and facilitates zero-shot predictions for new tasks. Our work lays the foundation for multimodal models that can perceive, listen to, and understand heterogeneous data, paving the way for scalable respiratory health diagnosis.
Electrocardiogram Report Generation and Question Answering via Retrieval-Augmented Self-Supervised Modeling
Sep 13, 2024



Interpreting electrocardiograms (ECGs) and generating comprehensive reports remain challenging tasks in cardiology, often requiring specialized expertise and significant time investment. To address these critical issues, we propose ECG-ReGen, a retrieval-based approach for ECG-to-text report generation and question answering. Our method leverages a self-supervised learning for the ECG encoder, enabling efficient similarity searches and report retrieval. By combining pre-training with dynamic retrieval and Large Language Model (LLM)-based refinement, ECG-ReGen effectively analyzes ECG data and answers related queries, with the potential of improving patient care. Experiments conducted on the PTB-XL and MIMIC-IV-ECG datasets demonstrate superior performance in both in-domain and cross-domain scenarios for report generation. Furthermore, our approach exhibits competitive performance on ECG-QA dataset compared to fully supervised methods when utilizing off-the-shelf LLMs for zero-shot question answering. This approach, effectively combining self-supervised encoder and LLMs, offers a scalable and efficient solution for accurate ECG interpretation, holding significant potential to enhance clinical decision-making.