 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multimodal Zero-Shot ECG Diagnosis via Structured Clinical Knowledge Alignment
Oct 24, 2025



Electrocardiogram (ECG) interpretation is essential for cardiovascular disease diagnosis, but current automated systems often struggle with transparency and generalization to unseen conditions. To address this, we introduce ZETA, a zero-shot multimodal framework designed for interpretable ECG diagnosis aligned with clinical workflows. ZETA uniquely compares ECG signals against structured positive and negative clinical observations, which are curated through an LLM-assisted, expert-validated process, thereby mimicking differential diagnosis. Our approach leverages a pre-trained multimodal model to align ECG and text embeddings without disease-specific fine-tuning. Empirical evaluations demonstrate ZETA's competitive zero-shot classification performance and, importantly, provide qualitative and quantitative evidence of enhanced interpretability, grounding predictions in specific, clinically relevant positive and negative diagnostic features. ZETA underscores the potential of aligning ECG analysis with structured clinical knowledge for building more transparent, generalizable, and trustworthy AI diagnostic systems. We will release the curated observation dataset and code to facilitate future research.
Q-Heart: ECG Question Answering via Knowledge-Informed Multimodal LLMs
May 07, 2025Electrocardiography (ECG) offers critical cardiovascular insights, such as identifying arrhythmias and myocardial ischemia, but enabling automated systems to answer complex clinical questions directly from ECG signals (ECG-QA) remains a significant challenge. Current approaches often lack robust multimodal reasoning capabilities or rely on generic architectures ill-suited for the nuances of physiological signals. We introduce Q-Heart, a novel multimodal framework designed to bridge this gap. Q-Heart leverages a powerful, adapted ECG encoder and integrates its representations with textual information via a specialized ECG-aware transformer-based mapping layer. Furthermore, Q-Heart leverages dynamic prompting and retrieval of relevant historical clinical reports to guide tuning the language model toward knowledge-aware ECG reasoning. Extensive evaluations on the benchmark ECG-QA dataset show Q-Heart achieves state-of-the-art performance, outperforming existing methods by a 4% improvement in exact match accuracy. Our work demonstrates the effectiveness of combining domain-specific architectural adaptations with knowledge-augmented LLM instruction tuning for complex physiological ECG analysis, paving the way for more capable and potentially interpretable clinical patient care systems.
On-demand Test-time Adaptation for Edge Devices
May 02, 2025Continual Test-time adaptation (CTTA) continuously adapts the deployed model on every incoming batch of data. While achieving optimal accuracy, existing CTTA approaches present poor real-world applicability on resource-constrained edge devices, due to the substantial memory overhead and energy consumption. In this work, we first introduce a novel paradigm -- on-demand TTA -- which triggers adaptation only when a significant domain shift is detected. Then, we present OD-TTA, an on-demand TTA framework for accurate and efficient adaptation on edge devices. OD-TTA comprises three innovative techniques: 1) a lightweight domain shift detection mechanism to activate TTA only when it is needed, drastically reducing the overall computation overhead, 2) a source domain selection module that chooses an appropriate source model for adaptation, ensuring high and robust accuracy, 3) a decoupled Batch Normalization (BN) update scheme to enable memory-efficient adaptation with small batch sizes. Extensive experiments show that OD-TTA achieves comparable and even better performance while reducing the energy and computation overhead remarkably, making TTA a practical reality.
Pushing the Limit of PPG Sensing in Sedentary Conditions by Addressing Poor Skin-sensor Contact
Apr 03, 2025Photoplethysmography (PPG) is a widely used non-invasive technique for monitoring cardiovascular health and various physiological parameters on consumer and medical devices. While motion artifacts are well-known challenges in dynamic settings, suboptimal skin-sensor contact in sedentary conditions - a critical issue often overlooked in existing literature - can distort PPG signal morphology, leading to the loss or shift of essential waveform features and therefore degrading sensing performance. In this work, we propose CP-PPG, a novel approach that transforms Contact Pressure-distorted PPG signals into ones with the ideal morphology. CP-PPG incorporates a novel data collection approach, a well-crafted signal processing pipeline, and an advanced deep adversarial model trained with a custom PPG-aware loss function. We validated CP-PPG through comprehensive evaluations, including 1) morphology transformation performance on our self-collected dataset, 2) downstream physiological monitoring performance on public datasets, and 3) in-the-wild performance. Extensive experiments demonstrate substantial and consistent improvements in signal fidelity (Mean Absolute Error: 0.09, 40% improvement over the original signal) as well as downstream performance across all evaluations in Heart Rate (HR), Heart Rate Variability (HRV), Respiration Rate (RR), and Blood Pressure (BP) estimation (on average, 21% improvement in HR; 41-46% in HRV; 6% in RR; and 4-5% in BP). These findings highlight the critical importance of addressing skin-sensor contact issues for accurate and dependable PPG-based physiological monitoring. Furthermore, CP-PPG can serve as a generic, plug-in API to enhance PPG signal quality.
C-MELT: Contrastive Enhanced Masked Auto-Encoders for ECG-Language Pre-Training
Oct 03, 2024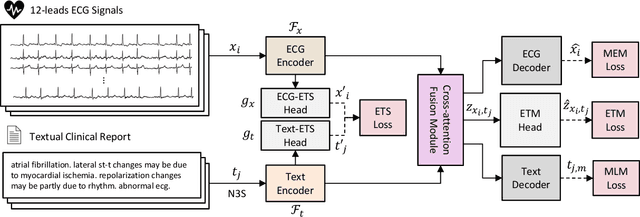
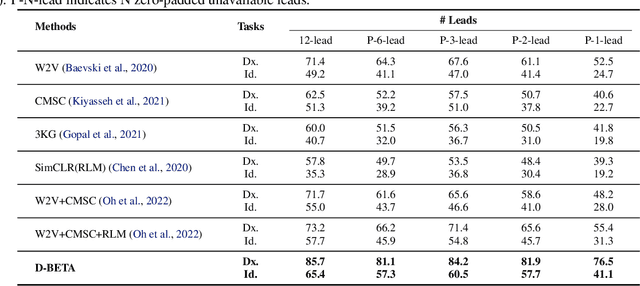
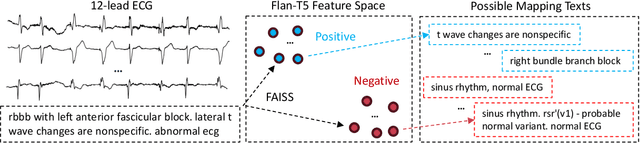
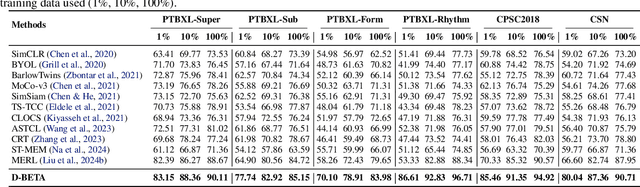
Accurate interpretation of Electrocardiogram (ECG) signals is pivotal for diagnosing cardiovascular diseases. Integrating ECG signals with their accompanying textual reports holds immense potential to enhance clinical diagnostics through the combination of physiological data and qualitative insights. However, this integration faces significant challenges due to inherent modality disparities and the scarcity of labeled data for robust cross-modal learning. To address these obstacles, we propose C-MELT, a novel framework that pre-trains ECG and text data using a contrastive masked auto-encoder architecture. C-MELT uniquely combines the strengths of generative with enhanced discriminative capabilities to achieve robust cross-modal representations. This is accomplished through masked modality modeling, specialized loss functions, and an improved negative sampling strategy tailored for cross-modal alignment. Extensive experiments on five public datasets across diverse downstream tasks demonstrate that C-MELT significantly outperforms existing methods, achieving 15% and 2% increases in linear probing and zero-shot performance over state-of-the-art models, respectively. These results highlight the effectiveness of C-MELT, underscoring its potential to advance automated clinical diagnostics through multi-modal representations.
RespEar: Earable-Based Robust Respiratory Rate Monitoring
Jul 09, 2024



Respiratory rate (RR) monitoring is integral to understanding physical and mental health and tracking fitness. Existing studies have demonstrated the feasibility of RR monitoring under specific user conditions (e.g., while remaining still, or while breathing heavily). Yet, performing accurate, continuous and non-obtrusive RR monitoring across diverse daily routines and activities remains challenging. In this work, we present RespEar, an earable-based system for robust RR monitoring. By leveraging the unique properties of in-ear microphones in earbuds, RespEar enables the use of Respiratory Sinus Arrhythmia (RSA) and Locomotor Respiratory Coupling (LRC), physiological couplings between cardiovascular activity, gait and respiration, to indirectly determine RR. This effectively addresses the challenges posed by the almost imperceptible breathing signals under daily activities. We further propose a suite of meticulously crafted signal processing schemes to improve RR estimation accuracy and robustness. With data collected from 18 subjects over 8 activities, RespEar measures RR with a mean absolute error (MAE) of 1.48 breaths per minutes (BPM) and a mean absolute percent error (MAPE) of 9.12% in sedentary conditions, and a MAE of 2.28 BPM and a MAPE of 11.04% in active conditions, respectively, which is unprecedented for a method capable of generalizing across conditions with a single modality.
DiTMoS: Delving into Diverse Tiny-Model Selection on Microcontrollers
Mar 14, 2024Enabling efficient and accurate deep neural network (DNN) inference on microcontrollers is non-trivial due to the constrained on-chip resources. Current methodologies primarily focus on compressing larger models yet at the expense of model accuracy. In this paper, we rethink the problem from the inverse perspective by constructing small/weak models directly and improving their accuracy. Thus, we introduce DiTMoS, a novel DNN training and inference framework with a selector-classifiers architecture, where the selector routes each input sample to the appropriate classifier for classification. DiTMoS is grounded on a key insight: a composition of weak models can exhibit high diversity and the union of them can significantly boost the accuracy upper bound. To approach the upper bound, DiTMoS introduces three strategies including diverse training data splitting to increase the classifiers' diversity, adversarial selector-classifiers training to ensure synergistic interactions thereby maximizing their complementarity, and heterogeneous feature aggregation to improve the capacity of classifiers. We further propose a network slicing technique to alleviate the extra memory overhead incurred by feature aggregation. We deploy DiTMoS on the Neucleo STM32F767ZI board and evaluate it based on three time-series datasets for human activity recognition, keywords spotting, and emotion recognition, respectively. The experiment results manifest that: (a) DiTMoS achieves up to 13.4% accuracy improvement compared to the best baseline; (b) network slicing almost completely eliminates the memory overhead incurred by feature aggregation with a marginal increase of latency.
UR2M: Uncertainty and Resource-Aware Event Detection on Microcontrollers
Feb 17, 2024Traditional machine learning techniques are prone to generating inaccurate predictions when confronted with shifts in the distribution of data between the training and testing phases. This vulnerability can lead to severe consequences, especially in applications such as mobile healthcare. Uncertainty estimation has the potential to mitigate this issue by assessing the reliability of a model's output. However, existing uncertainty estimation techniques often require substantial computational resources and memory, making them impractical for implementation on microcontrollers (MCUs). This limitation hinders the feasibility of many important on-device wearable event detection (WED) applications, such as heart attack detection. In this paper, we present UR2M, a novel Uncertainty and Resource-aware event detection framework for MCUs. Specifically, we (i) develop an uncertainty-aware WED based on evidential theory for accurate event detection and reliable uncertainty estimation; (ii) introduce a cascade ML framework to achieve efficient model inference via early exits, by sharing shallower model layers among different event models; (iii) optimize the deployment of the model and MCU library for system efficiency. We conducted extensive experiments and compared UR2M to traditional uncertainty baselines using three wearable datasets. Our results demonstrate that UR2M achieves up to 864% faster inference speed, 857% energy-saving for uncertainty estimation, 55% memory saving on two popular MCUs, and a 22% improvement in uncertainty quantification performance. UR2M can be deployed on a wide range of MCUs, significantly expanding real-time and reliable WED applications.
Channelized analog microwave short-time Fourier transform in the optical domain with improved measurement performance
May 25, 2023



In this article, analog microwave short-time Fourier transform (STFT) with improved measurement performance is implemented in the optical domain by employing stimulated Brillouin scattering (SBS) and channelization. By jointly using three optical frequency combs and filter- and SBS-based frequency-to-time mapping (FTTM), the time-frequency information of the signal under test (SUT) in different frequency intervals is measured in different channels. Then, by using the channel label introduced through subcarriers after photodetection, the obtained low-speed electrical pulses in different channels mixed in the time domain are distinguished and the time-frequency information of the SUT in different channels is respectively obtained and spliced to implement the STFT. For the first time, channelization measurement technology is introduced in the STFT system based on frequency sweeping and FTTM, greatly reducing the frequency-sweep range of the required frequency-sweep signal to the analysis bandwidth divided by the number of channels. In addition, channelization can also be used to improve the time and frequency resolution of the STFT system. A proof-of-concept experiment is performed. 12-GHz and 10-GHz analysis bandwidth is implemented by using a 4-GHz frequency-sweep signal and 3 channels and a 2-GHz frequency-sweep signal and 5 channels. Measurement performance improvement is also demonstrated.
Photonics-enabled wavelet-like transform via nonlinear optical frequency sweeping and stimulated Brillouin scattering-based frequency-to-time mapping
Aug 19, 2022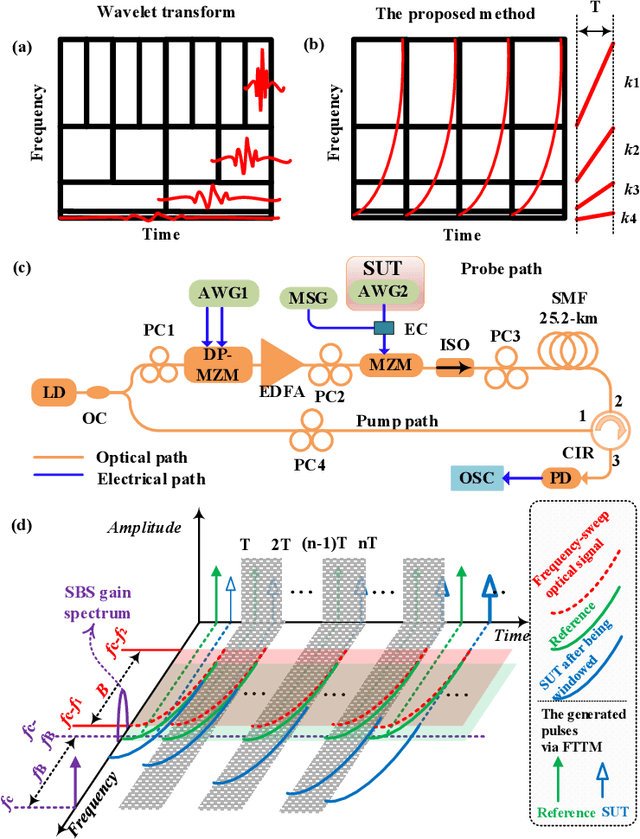
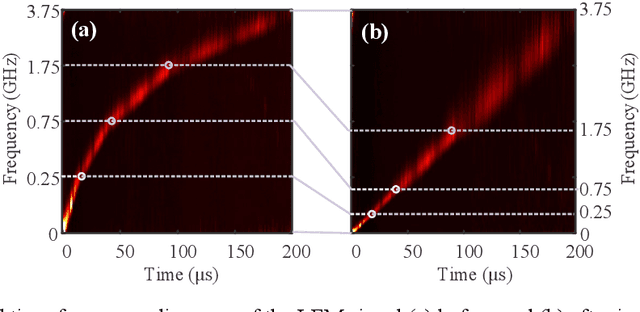
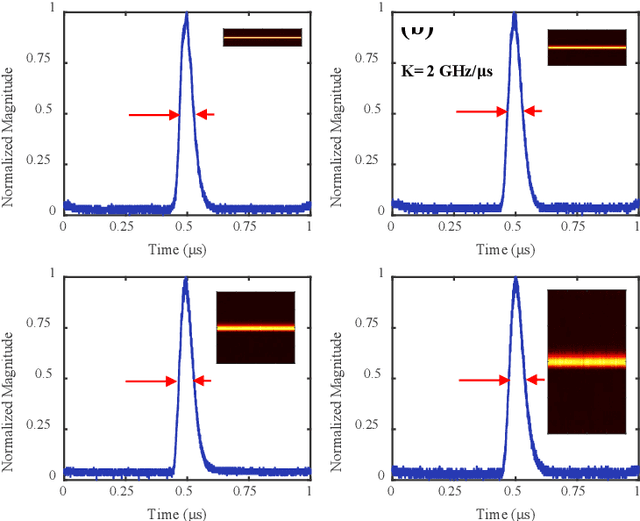
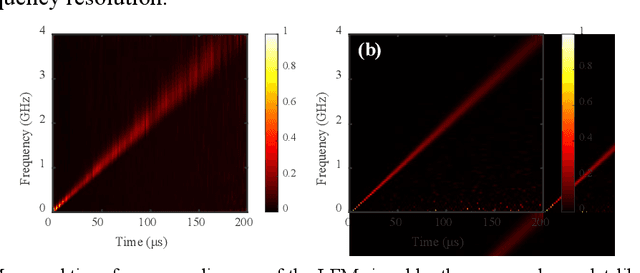
A photonics-enabled wavelet-like transform system, characterized by multi-resolution time-frequency analysis, is proposed based on a typical stimulated Brillouin scattering (SBS) pump-probe setup using an optical nonlinear frequency-sweep signal. In the pump path, a continuous-wave optical signal is injected into an SBS medium to generate an SBS gain. In the probe path, a periodic nonlinear frequency-sweep optical signal with a time-varying chirp rate is generated, which is then modulated at a Mach-Zehnder modulator (MZM) by the electrical signal under test (SUT). The optical signal from the MZM is selectively amplified by the SBS gain and converted back to the electrical domain using a low-speed photodetector, implementing the periodic SBS-based frequency-to-time mapping (FTTM). The frequency-domain information corresponding to different periods is mapped to the time domain via the FTTM in the form of low-speed electrical pulses, which is then spliced to analyze the time-frequency relationship of the SUT in real-time. The time-varying chirp rate in each sweep period makes the signals with different frequencies have different frequency resolutions in the FTTM process, which is very similar to the characteristics of the wavelet transform, so we call it wavelet-like transform. An experiment is carried out. Multi-resolution time-frequency analysis of a variety of RF signals is carried out in a 4-GHz bandwidth limited only by the equipment.