 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSensus: Multi-Agent Collaboration for Multimodal Sensing
Jan 10, 2026Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world. However, accurately interpreting heterogeneous multimodal sensor data remains a fundamental challenge. We show that a single monolithic LLM often fails to reason coherently across modalities, leading to incomplete interpretations and prior-knowledge bias. We introduce ConSensus, a training-free multi-agent collaboration framework that decomposes multimodal sensing tasks into specialized, modality-aware agents. To aggregate agent-level interpretations, we propose a hybrid fusion mechanism that balances semantic aggregation, which enables cross-modal reasoning and contextual understanding, with statistical consensus, which provides robustness through agreement across modalities. While each approach has complementary failure modes, their combination enables reliable inference under sensor noise and missing data. We evaluate ConSensus on five diverse multimodal sensing benchmarks, demonstrating an average accuracy improvement of 7.1% over the single-agent baseline. Furthermore, ConSensus matches or exceeds the performance of iterative multi-agent debate methods while achieving a 12.7 times reduction in average fusion token cost through a single-round hybrid fusion protocol, yielding a robust and efficient solution for real-world multimodal sensing tasks.
UR2M: Uncertainty and Resource-Aware Event Detection on Microcontrollers
Feb 17, 2024Traditional machine learning techniques are prone to generating inaccurate predictions when confronted with shifts in the distribution of data between the training and testing phases. This vulnerability can lead to severe consequences, especially in applications such as mobile healthcare. Uncertainty estimation has the potential to mitigate this issue by assessing the reliability of a model's output. However, existing uncertainty estimation techniques often require substantial computational resources and memory, making them impractical for implementation on microcontrollers (MCUs). This limitation hinders the feasibility of many important on-device wearable event detection (WED) applications, such as heart attack detection. In this paper, we present UR2M, a novel Uncertainty and Resource-aware event detection framework for MCUs. Specifically, we (i) develop an uncertainty-aware WED based on evidential theory for accurate event detection and reliable uncertainty estimation; (ii) introduce a cascade ML framework to achieve efficient model inference via early exits, by sharing shallower model layers among different event models; (iii) optimize the deployment of the model and MCU library for system efficiency. We conducted extensive experiments and compared UR2M to traditional uncertainty baselines using three wearable datasets. Our results demonstrate that UR2M achieves up to 864% faster inference speed, 857% energy-saving for uncertainty estimation, 55% memory saving on two popular MCUs, and a 22% improvement in uncertainty quantification performance. UR2M can be deployed on a wide range of MCUs, significantly expanding real-time and reliable WED applications.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.
Practical self-supervised continual learning with continual fine-tuning
Mar 30, 2023


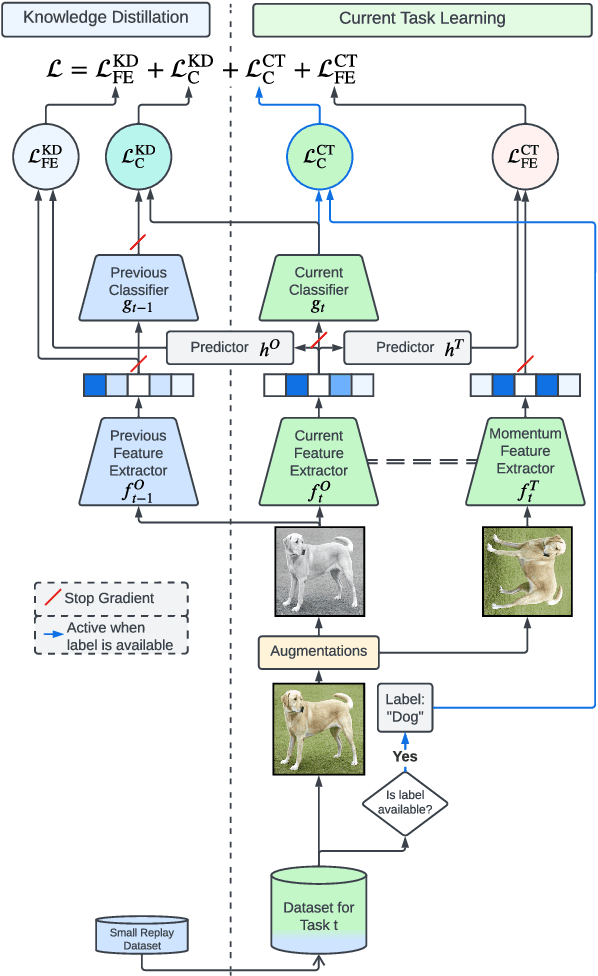
Self-supervised learning (SSL) has shown remarkable performance in computer vision tasks when trained offline. However, in a Continual Learning (CL) scenario where new data is introduced progressively, models still suffer from catastrophic forgetting. Retraining a model from scratch to adapt to newly generated data is time-consuming and inefficient. Previous approaches suggested re-purposing self-supervised objectives with knowledge distillation to mitigate forgetting across tasks, assuming that labels from all tasks are available during fine-tuning. In this paper, we generalize self-supervised continual learning in a practical setting where available labels can be leveraged in any step of the SSL process. With an increasing number of continual tasks, this offers more flexibility in the pre-training and fine-tuning phases. With Kaizen, we introduce a training architecture that is able to mitigate catastrophic forgetting for both the feature extractor and classifier with a carefully designed loss function. By using a set of comprehensive evaluation metrics reflecting different aspects of continual learning, we demonstrated that Kaizen significantly outperforms previous SSL models in competitive vision benchmarks, with up to 16.5% accuracy improvement on split CIFAR-100. Kaizen is able to balance the trade-off between knowledge retention and learning from new data with an end-to-end model, paving the way for practical deployment of continual learning systems.
Enhancing the Security & Privacy of Wearable Brain-Computer Interfaces
Jan 19, 2022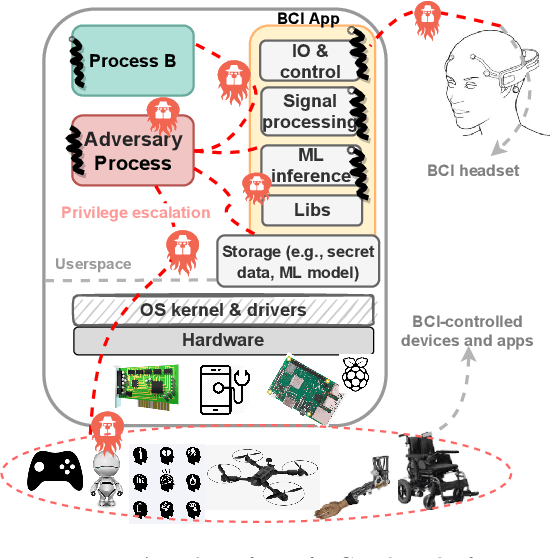

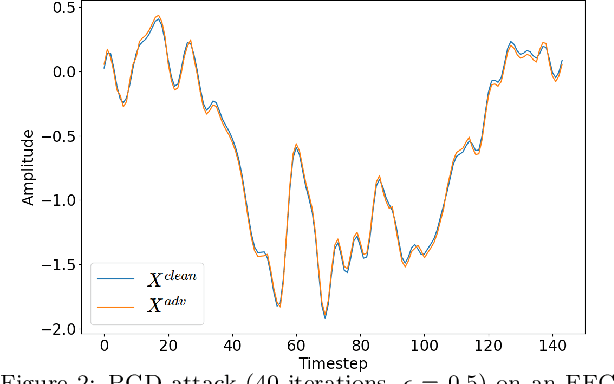
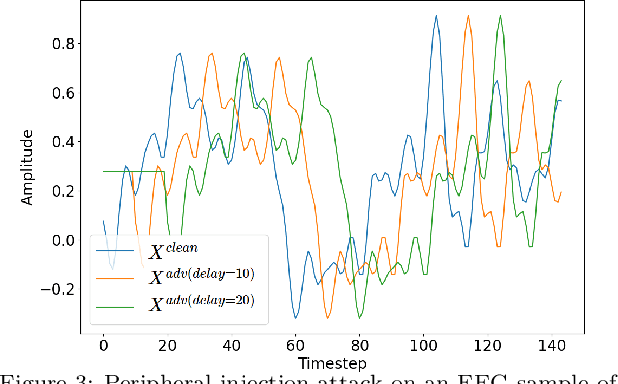
Brain computing interfaces (BCI) are used in a plethora of safety/privacy-critical applications, ranging from healthcare to smart communication and control. Wearable BCI setups typically involve a head-mounted sensor connected to a mobile device, combined with ML-based data processing. Consequently, they are susceptible to a multiplicity of attacks across the hardware, software, and networking stacks used that can leak users' brainwave data or at worst relinquish control of BCI-assisted devices to remote attackers. In this paper, we: (i) analyse the whole-system security and privacy threats to existing wearable BCI products from an operating system and adversarial machine learning perspective; and (ii) introduce Argus, the first information flow control system for wearable BCI applications that mitigates these attacks. Argus' domain-specific design leads to a lightweight implementation on Linux ARM platforms suitable for existing BCI use-cases. Our proof of concept attacks on real-world BCI devices (Muse, NeuroSky, and OpenBCI) led us to discover more than 300 vulnerabilities across the stacks of six major attack vectors. Our evaluation shows Argus is highly effective in tracking sensitive dataflows and restricting these attacks with an acceptable memory and performance overhead (<15%).
High Frequency EEG Artifact Detection with Uncertainty via Early Exit Paradigm
Jul 21, 2021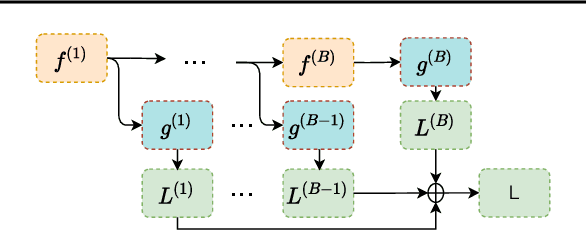
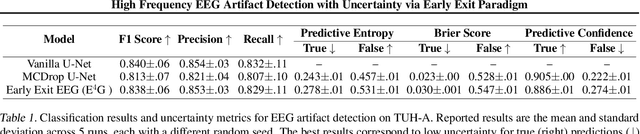
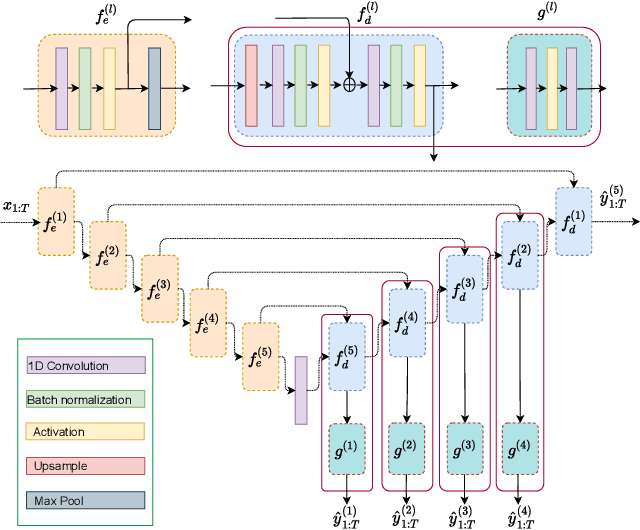
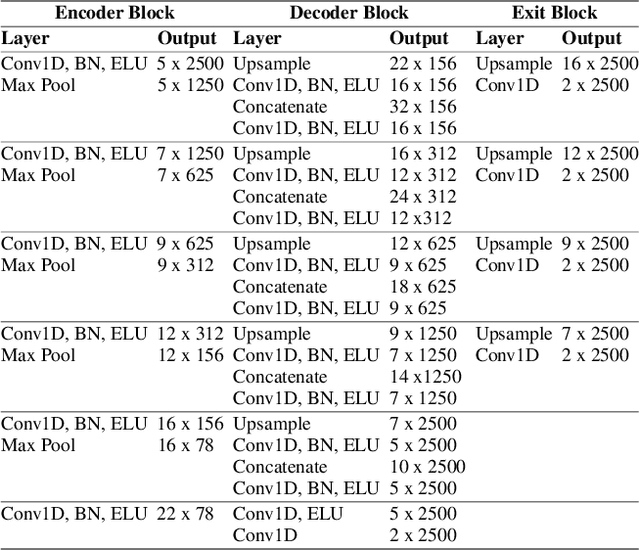
Electroencephalography (EEG) is crucial for the monitoring and diagnosis of brain disorders. However, EEG signals suffer from perturbations caused by non-cerebral artifacts limiting their efficacy. Current artifact detection pipelines are resource-hungry and rely heavily on hand-crafted features. Moreover, these pipelines are deterministic in nature, making them unable to capture predictive uncertainty. We propose E4G, a deep learning framework for high frequency EEG artifact detection. Our framework exploits the early exit paradigm, building an implicit ensemble of models capable of capturing uncertainty. We evaluate our approach on the Temple University Hospital EEG Artifact Corpus (v2.0) achieving state-of-the-art classification results. In addition, E4G provides well-calibrated uncertainty metrics comparable to sampling techniques like Monte Carlo dropout in just a single forward pass. E4G opens the door to uncertainty-aware artifact detection supporting clinicians-in-the-loop frameworks.
Stochastic-Shield: A Probabilistic Approach Towards Training-Free Adversarial Defense in Quantized CNNs
May 13, 2021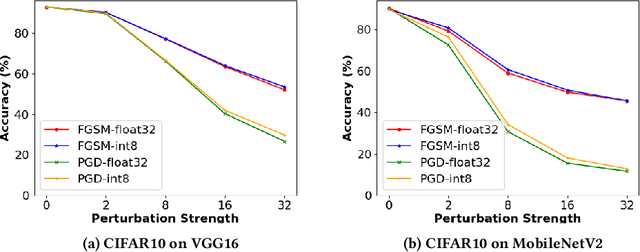
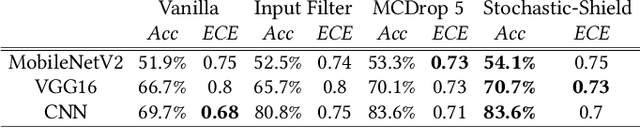
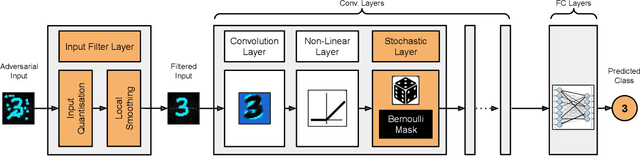
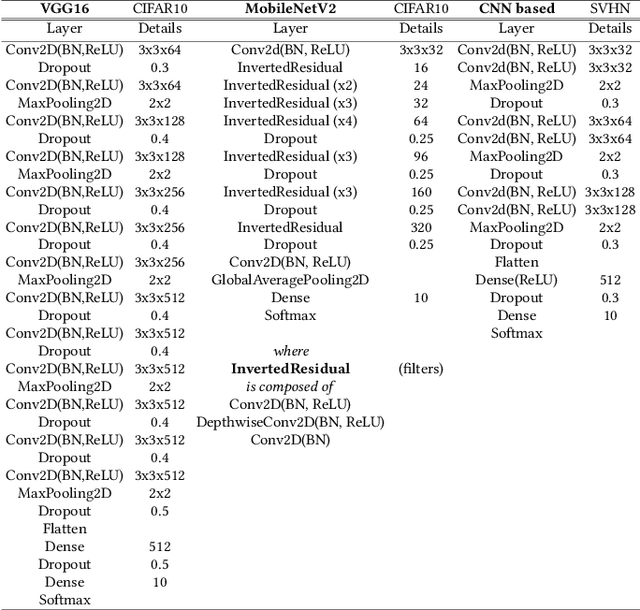
Quantized neural networks (NN) are the common standard to efficiently deploy deep learning models on tiny hardware platforms. However, we notice that quantized NNs are as vulnerable to adversarial attacks as the full-precision models. With the proliferation of neural networks on small devices that we carry or surround us, there is a need for efficient models without sacrificing trust in the prediction in presence of malign perturbations. Current mitigation approaches often need adversarial training or are bypassed when the strength of adversarial examples is increased. In this work, we investigate how a probabilistic framework would assist in overcoming the aforementioned limitations for quantized deep learning models. We explore Stochastic-Shield: a flexible defense mechanism that leverages input filtering and a probabilistic deep learning approach materialized via Monte Carlo Dropout. We show that it is possible to jointly achieve efficiency and robustness by accurately enabling each module without the burden of re-retraining or ad hoc fine-tuning.
Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data
Apr 05, 2021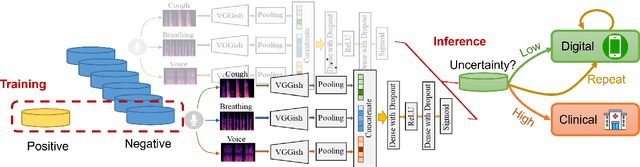
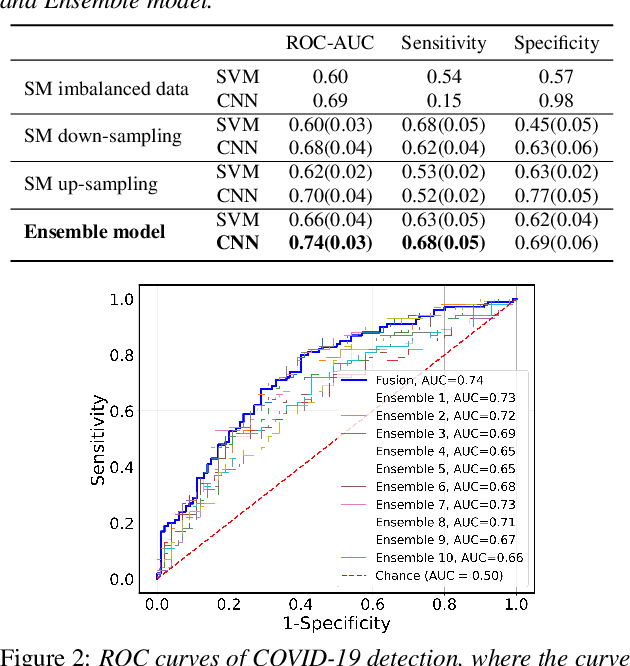
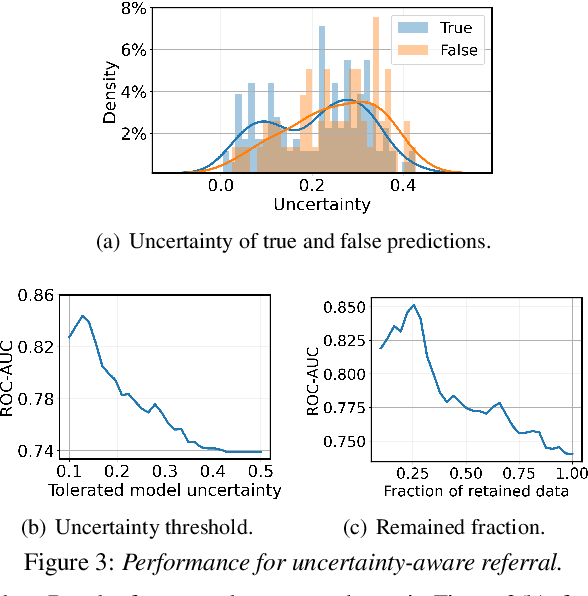
Recently, sound-based COVID-19 detection studies have shown great promise to achieve scalable and prompt digital pre-screening. However, there are still two unsolved issues hindering the practice. First, collected datasets for model training are often imbalanced, with a considerably smaller proportion of users tested positive, making it harder to learn representative and robust features. Second, deep learning models are generally overconfident in their predictions. Clinically, false predictions aggravate healthcare costs. Estimation of the uncertainty of screening would aid this. To handle these issues, we propose an ensemble framework where multiple deep learning models for sound-based COVID-19 detection are developed from different but balanced subsets from original data. As such, data are utilized more effectively compared to traditional up-sampling and down-sampling approaches: an AUC of 0.74 with a sensitivity of 0.68 and a specificity of 0.69 is achieved. Simultaneously, we estimate uncertainty from the disagreement across multiple models. It is shown that false predictions often yield higher uncertainty, enabling us to suggest the users with certainty higher than a threshold to repeat the audio test on their phones or to take clinical tests if digital diagnosis still fails. This study paves the way for a more robust sound-based COVID-19 automated screening system.
The Benefit of the Doubt: Uncertainty Aware Sensing for Edge Computing Platforms
Feb 11, 2021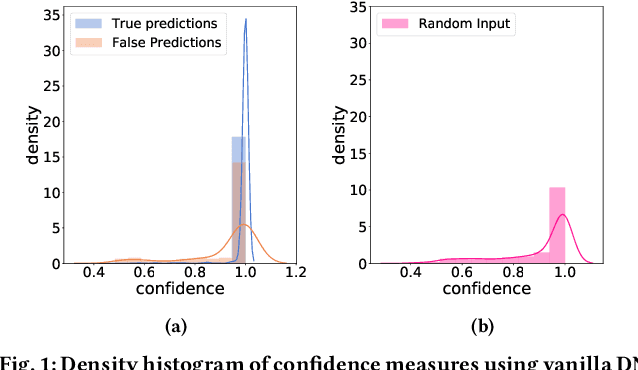


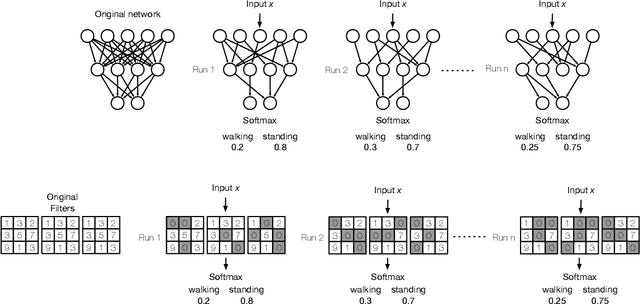
Neural networks (NNs) lack measures of "reliability" estimation that would enable reasoning over their predictions. Despite the vital importance, especially in areas of human well-being and health, state-of-the-art uncertainty estimation techniques are computationally expensive when applied to resource-constrained devices. We propose an efficient framework for predictive uncertainty estimation in NNs deployed on embedded edge systems with no need for fine-tuning or re-training strategies. To meet the energy and latency requirements of these embedded platforms the framework is built from the ground up to provide predictive uncertainty based only on one forward pass and a negligible amount of additional matrix multiplications with theoretically proven correctness. Our aim is to enable already trained deep learning models to generate uncertainty estimates on resource-limited devices at inference time focusing on classification tasks. This framework is founded on theoretical developments casting dropout training as approximate inference in Bayesian NNs. Our layerwise distribution approximation to the convolution layer cascades through the network, providing uncertainty estimates in one single run which ensures minimal overhead, especially compared with uncertainty techniques that require multiple forwards passes and an equal linear rise in energy and latency requirements making them unsuitable in practice. We demonstrate that it yields better performance and flexibility over previous work based on multilayer perceptrons to obtain uncertainty estimates. Our evaluation with mobile applications datasets shows that our approach not only obtains robust and accurate uncertainty estimations but also outperforms state-of-the-art methods in terms of systems performance, reducing energy consumption (up to 28x), keeping the memory overhead at a minimum while still improving accuracy (up to 16%).