 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Event Detection with Boundary-Aware Optimization and Inference
Jan 07, 2026Temporal detection problems appear in many fields including time-series estimation, activity recognition and sound event detection (SED). In this work, we propose a new approach to temporal event modeling by explicitly modeling event onsets and offsets, and by introducing boundary-aware optimization and inference strategies that substantially enhance temporal event detection. The presented methodology incorporates new temporal modeling layers - Recurrent Event Detection (RED) and Event Proposal Network (EPN) - which, together with tailored loss functions, enable more effective and precise temporal event detection. We evaluate the proposed method in the SED domain using a subset of the temporally-strongly annotated portion of AudioSet. Experimental results show that our approach not only outperforms traditional frame-wise SED models with state-of-the-art post-processing, but also removes the need for post-processing hyperparameter tuning, and scales to achieve new state-of-the-art performance across all AudioSet Strong classes.
PRIMUS: Pretraining IMU Encoders with Multimodal Self-Supervision
Nov 22, 2024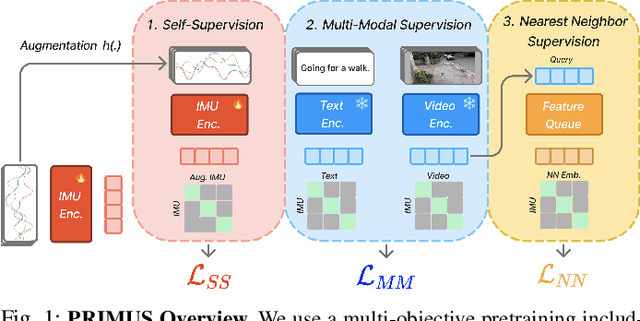
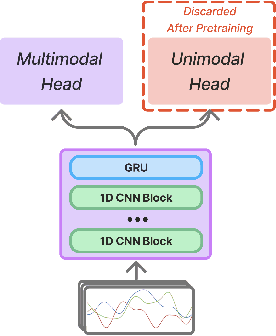
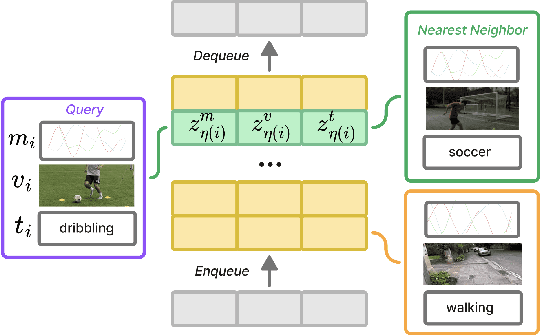
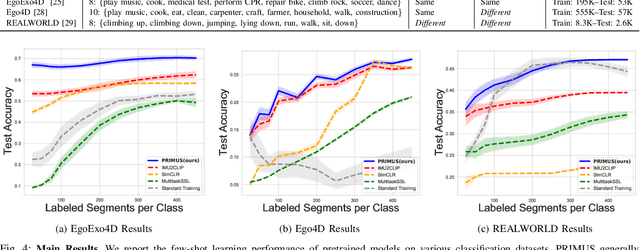
Sensing human motions through Inertial Measurement Units (IMUs) embedded in personal devices has enabled significant applications in health and wellness. While labeled IMU data is scarce, we can collect unlabeled or weakly labeled IMU data to model human motions. For video or text modalities, the "pretrain and adapt" approach utilizes large volumes of unlabeled or weakly labeled data for pretraining, building a strong feature extractor, followed by adaptation to specific tasks using limited labeled data. This approach has not been widely adopted in the IMU domain for two reasons: (1) pretraining methods are poorly understood in the context of IMU, and (2) open-source pretrained models that generalize across datasets are rarely publicly available. In this paper, we aim to address the first issue by proposing PRIMUS, a method for PRetraining IMU encoderS. We conduct a systematic and unified evaluation of various self-supervised and multimodal learning pretraining objectives. Our findings indicate that using PRIMUS, which combines self-supervision, multimodal supervision, and nearest-neighbor supervision, can significantly enhance downstream performance. With fewer than 500 labeled samples per class, PRIMUS effectively enhances downstream performance by up to 15% in held-out test data, compared to the state-of-the-art multimodal training method. To benefit the broader community, our code and pre-trained IMU encoders will be made publicly available at github.com/nokia-bell-labs upon publication.
Past, Present, and Future of Sensor-based Human Activity Recognition using Wearables: A Surveying Tutorial on a Still Challenging Task
Nov 11, 2024In the many years since the inception of wearable sensor-based Human Activity Recognition (HAR), a wide variety of methods have been introduced and evaluated for their ability to recognize activities. Substantial gains have been made since the days of hand-crafting heuristics as features, yet, progress has seemingly stalled on many popular benchmarks, with performance falling short of what may be considered 'sufficient'-- despite the increase in computational power and scale of sensor data, as well as rising complexity in techniques being employed. The HAR community approaches a new paradigm shift, this time incorporating world knowledge from foundational models. In this paper, we take stock of sensor-based HAR -- surveying it from its beginnings to the current state of the field, and charting its future. This is accompanied by a hands-on tutorial, through which we guide practitioners in developing HAR systems for real-world application scenarios. We provide a compendium for novices and experts alike, of methods that aim at finally solving the activity recognition problem.
A collection of the accepted papers for the Human-Centric Representation Learning workshop at AAAI 2024
Mar 14, 2024This non-archival index is not complete, as some accepted papers chose to opt-out of inclusion. The list of all accepted papers is available on the workshop website.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.
Practical self-supervised continual learning with continual fine-tuning
Mar 30, 2023


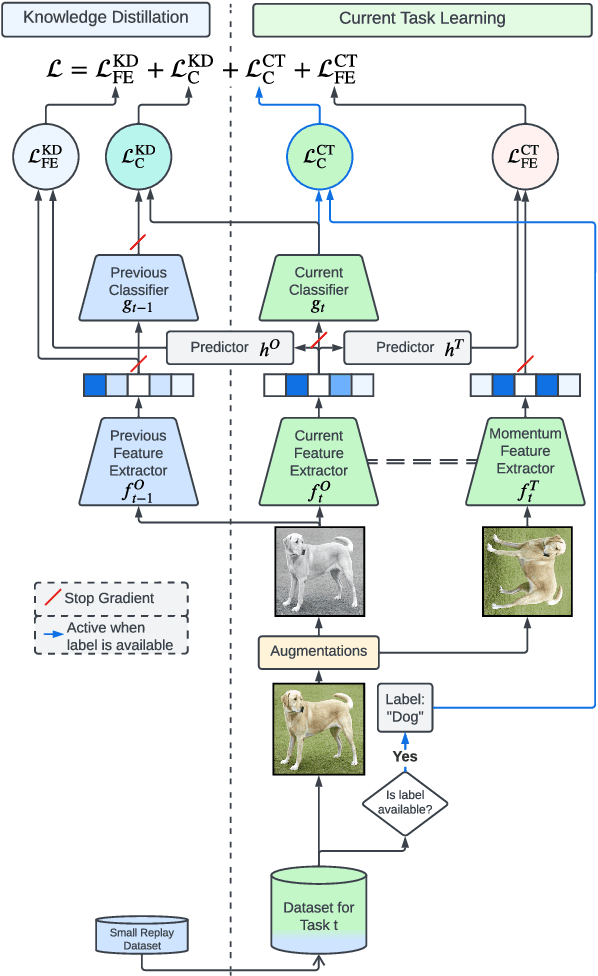
Self-supervised learning (SSL) has shown remarkable performance in computer vision tasks when trained offline. However, in a Continual Learning (CL) scenario where new data is introduced progressively, models still suffer from catastrophic forgetting. Retraining a model from scratch to adapt to newly generated data is time-consuming and inefficient. Previous approaches suggested re-purposing self-supervised objectives with knowledge distillation to mitigate forgetting across tasks, assuming that labels from all tasks are available during fine-tuning. In this paper, we generalize self-supervised continual learning in a practical setting where available labels can be leveraged in any step of the SSL process. With an increasing number of continual tasks, this offers more flexibility in the pre-training and fine-tuning phases. With Kaizen, we introduce a training architecture that is able to mitigate catastrophic forgetting for both the feature extractor and classifier with a carefully designed loss function. By using a set of comprehensive evaluation metrics reflecting different aspects of continual learning, we demonstrated that Kaizen significantly outperforms previous SSL models in competitive vision benchmarks, with up to 16.5% accuracy improvement on split CIFAR-100. Kaizen is able to balance the trade-off between knowledge retention and learning from new data with an end-to-end model, paving the way for practical deployment of continual learning systems.
Orchestra: Unsupervised Federated Learning via Globally Consistent Clustering
May 23, 2022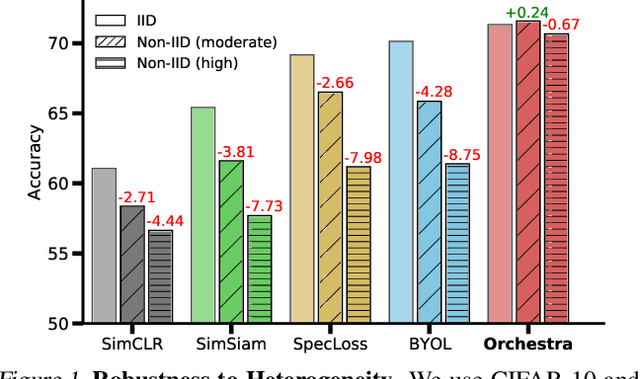
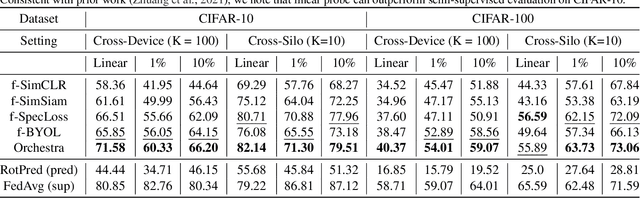
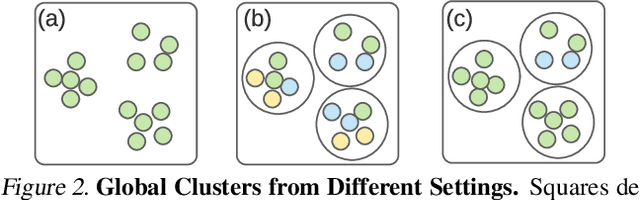
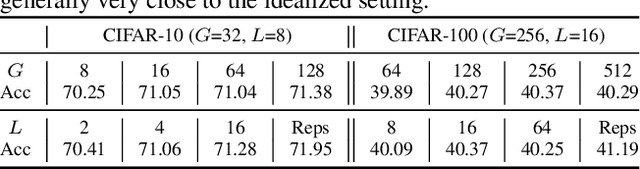
Federated learning is generally used in tasks where labels are readily available (e.g., next word prediction). Relaxing this constraint requires design of unsupervised learning techniques that can support desirable properties for federated training: robustness to statistical/systems heterogeneity, scalability with number of participants, and communication efficiency. Prior work on this topic has focused on directly extending centralized self-supervised learning techniques, which are not designed to have the properties listed above. To address this situation, we propose Orchestra, a novel unsupervised federated learning technique that exploits the federation's hierarchy to orchestrate a distributed clustering task and enforce a globally consistent partitioning of clients' data into discriminable clusters. We show the algorithmic pipeline in Orchestra guarantees good generalization performance under a linear probe, allowing it to outperform alternative techniques in a broad range of conditions, including variation in heterogeneity, number of clients, participation ratio, and local epochs.
Improving Feature Generalizability with Multitask Learning in Class Incremental Learning
Apr 26, 2022
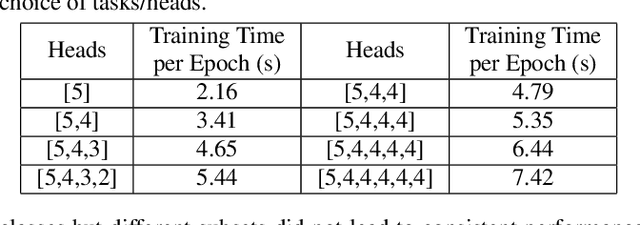

Many deep learning applications, like keyword spotting, require the incorporation of new concepts (classes) over time, referred to as Class Incremental Learning (CIL). The major challenge in CIL is catastrophic forgetting, i.e., preserving as much of the old knowledge as possible while learning new tasks. Various techniques, such as regularization, knowledge distillation, and the use of exemplars, have been proposed to resolve this issue. However, prior works primarily focus on the incremental learning step, while ignoring the optimization during the base model training. We hypothesize that a more transferable and generalizable feature representation from the base model would be beneficial to incremental learning. In this work, we adopt multitask learning during base model training to improve the feature generalizability. Specifically, instead of training a single model with all the base classes, we decompose the base classes into multiple subsets and regard each of them as a task. These tasks are trained concurrently and a shared feature extractor is obtained for incremental learning. We evaluate our approach on two datasets under various configurations. The results show that our approach enhances the average incremental learning accuracy by up to 5.5%, which enables more reliable and accurate keyword spotting over time. Moreover, the proposed approach can be combined with many existing techniques and provides additional performance gain.
ColloSSL: Collaborative Self-Supervised Learning for Human Activity Recognition
Feb 01, 2022
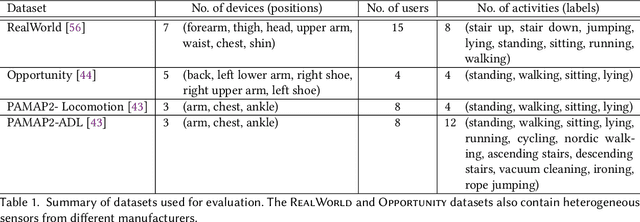

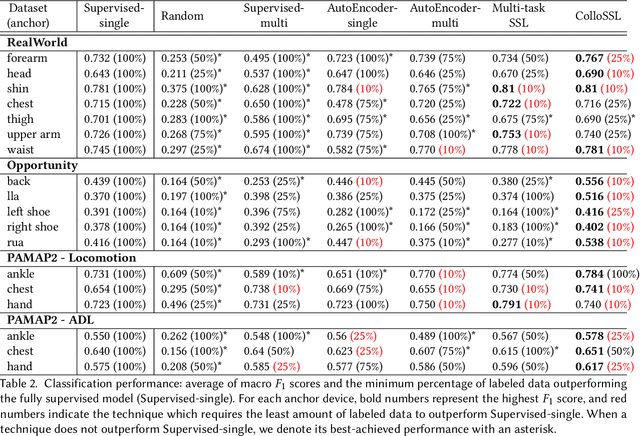
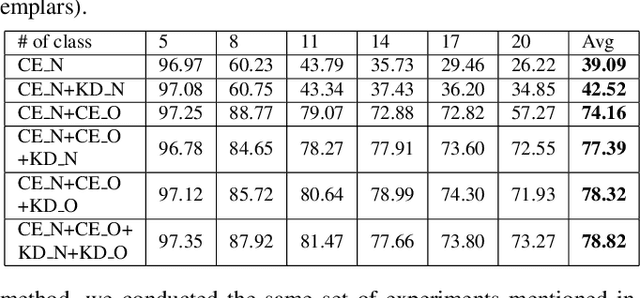
A major bottleneck in training robust Human-Activity Recognition models (HAR) is the need for large-scale labeled sensor datasets. Because labeling large amounts of sensor data is an expensive task, unsupervised and semi-supervised learning techniques have emerged that can learn good features from the data without requiring any labels. In this paper, we extend this line of research and present a novel technique called Collaborative Self-Supervised Learning (ColloSSL) which leverages unlabeled data collected from multiple devices worn by a user to learn high-quality features of the data. A key insight that underpins the design of ColloSSL is that unlabeled sensor datasets simultaneously captured by multiple devices can be viewed as natural transformations of each other, and leveraged to generate a supervisory signal for representation learning. We present three technical innovations to extend conventional self-supervised learning algorithms to a multi-device setting: a Device Selection approach which selects positive and negative devices to enable contrastive learning, a Contrastive Sampling algorithm which samples positive and negative examples in a multi-device setting, and a loss function called Multi-view Contrastive Loss which extends standard contrastive loss to a multi-device setting. Our experimental results on three multi-device datasets show that ColloSSL outperforms both fully-supervised and semi-supervised learning techniques in majority of the experiment settings, resulting in an absolute increase of upto 7.9% in F_1 score compared to the best performing baselines. We also show that ColloSSL outperforms the fully-supervised methods in a low-data regime, by just using one-tenth of the available labeled data in the best case.
Evaluating Contrastive Learning on Wearable Timeseries for Downstream Clinical Outcomes
Nov 13, 2021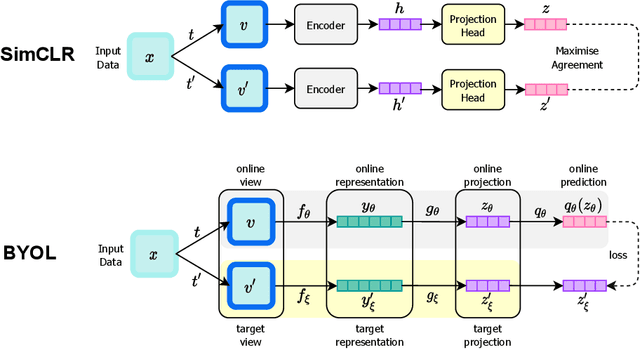


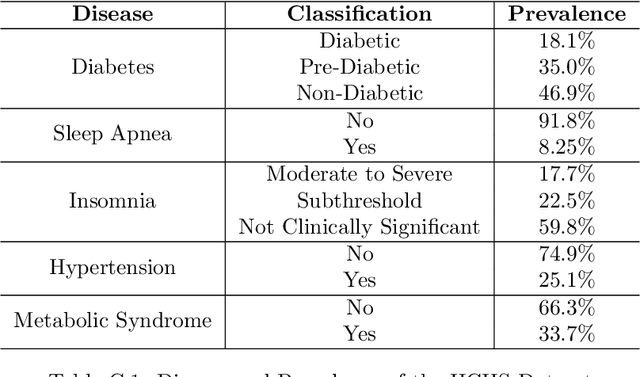
Vast quantities of person-generated health data (wearables) are collected but the process of annotating to feed to machine learning models is impractical. This paper discusses ways in which self-supervised approaches that use contrastive losses, such as SimCLR and BYOL, previously applied to the vision domain, can be applied to high-dimensional health signals for downstream classification tasks of various diseases spanning sleep, heart, and metabolic conditions. To this end, we adapt the data augmentation step and the overall architecture to suit the temporal nature of the data (wearable traces) and evaluate on 5 downstream tasks by comparing other state-of-the-art methods including supervised learning and an adversarial unsupervised representation learning method. We show that SimCLR outperforms the adversarial method and a fully-supervised method in the majority of the downstream evaluation tasks, and that all self-supervised methods outperform the fully-supervised methods. This work provides a comprehensive benchmark for contrastive methods applied to the wearable time-series domain, showing the promise of task-agnostic representations for downstream clinical outcomes.