 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoSE: Mixture of Slimmable Experts for Efficient and Adaptive Language Models
Feb 05, 2026Mixture-of-Experts (MoE) models scale large language models efficiently by sparsely activating experts, but once an expert is selected, it is executed fully. Hence, the trade-off between accuracy and computation in an MoE model typically exhibits large discontinuities. We propose Mixture of Slimmable Experts (MoSE), an MoE architecture in which each expert has a nested, slimmable structure that can be executed at variable widths. This enables conditional computation not only over which experts are activated, but also over how much of each expert is utilized. Consequently, a single pretrained MoSE model can support a more continuous spectrum of accuracy-compute trade-offs at inference time. We present a simple and stable training recipe for slimmable experts under sparse routing, combining multi-width training with standard MoE objectives. During inference, we explore strategies for runtime width determination, including a lightweight test-time training mechanism that learns how to map router confidence/probabilities to expert widths under a fixed budget. Experiments on GPT models trained on OpenWebText demonstrate that MoSE matches or improves upon standard MoE at full width and consistently shifts the Pareto frontier for accuracy vs. cost, achieving comparable performance with significantly fewer FLOPs.
FlexRank: Nested Low-Rank Knowledge Decomposition for Adaptive Model Deployment
Feb 02, 2026The growing scale of deep neural networks, encompassing large language models (LLMs) and vision transformers (ViTs), has made training from scratch prohibitively expensive and deployment increasingly costly. These models are often used as computational monoliths with fixed cost, a rigidity that does not leverage overparametrized architectures and largely hinders adaptive deployment across different cost budgets. We argue that importance-ordered nested components can be extracted from pretrained models, and selectively activated on the available computational budget. To this end, our proposed FlexRank method leverages low-rank weight decomposition with nested, importance-based consolidation to extract submodels of increasing capabilities. Our approach enables a "train-once, deploy-everywhere" paradigm that offers a graceful trade-off between cost and performance without training from scratch for each budget - advancing practical deployment of large models.
LoFT: Low-Rank Adaptation That Behaves Like Full Fine-Tuning
May 27, 2025Large pre-trained models are commonly adapted to downstream tasks using parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA), which injects small trainable low-rank matrices instead of updating all weights. While LoRA dramatically reduces trainable parameters with little overhead, it can still underperform full fine-tuning in accuracy and often converges more slowly. We introduce LoFT, a novel low-rank adaptation method that behaves like full fine-tuning by aligning the optimizer's internal dynamics with those of updating all model weights. LoFT not only learns weight updates in a low-rank subspace (like LoRA) but also properly projects the optimizer's first and second moments (Adam's momentum and variance) into the same subspace, mirroring full-model updates. By aligning the low-rank update itself with the full update, LoFT eliminates the need for tuning extra hyperparameters, e.g., LoRA scaling factor $\alpha$. Empirically, this approach substantially narrows the performance gap between adapter-based tuning and full fine-tuning and consistently outperforms standard LoRA-style methods, all without increasing inference cost.
NoEsis: Differentially Private Knowledge Transfer in Modular LLM Adaptation
Apr 25, 2025Large Language Models (LLM) are typically trained on vast amounts of data from various sources. Even when designed modularly (e.g., Mixture-of-Experts), LLMs can leak privacy on their sources. Conversely, training such models in isolation arguably prohibits generalization. To this end, we propose a framework, NoEsis, which builds upon the desired properties of modularity, privacy, and knowledge transfer. NoEsis integrates differential privacy with a hybrid two-staged parameter-efficient fine-tuning that combines domain-specific low-rank adapters, acting as experts, with common prompt tokens, acting as a knowledge-sharing backbone. Results from our evaluation on CodeXGLUE showcase that NoEsis can achieve provable privacy guarantees with tangible knowledge transfer across domains, and empirically show protection against Membership Inference Attacks. Finally, on code completion tasks, NoEsis bridges at least 77% of the accuracy gap between the non-shared and the non-private baseline.
* ICLR 2025 MCDC workshop
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
May 23, 2024Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
MELTing point: Mobile Evaluation of Language Transformers
Mar 20, 2024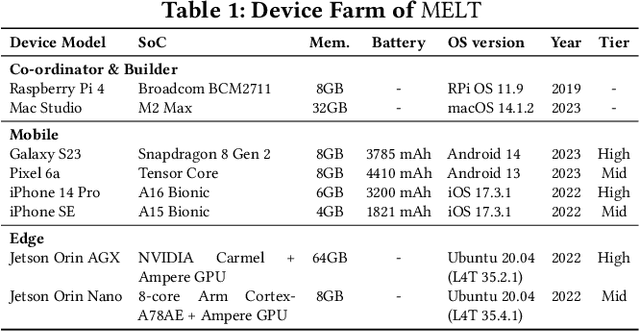
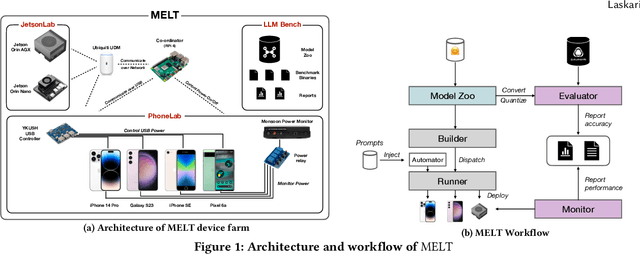

Transformers have revolutionized the machine learning landscape, gradually making their way into everyday tasks and equipping our computers with ``sparks of intelligence''. However, their runtime requirements have prevented them from being broadly deployed on mobile. As personal devices become increasingly powerful and prompt privacy becomes an ever more pressing issue, we explore the current state of mobile execution of Large Language Models (LLMs). To achieve this, we have created our own automation infrastructure, MELT, which supports the headless execution and benchmarking of LLMs on device, supporting different models, devices and frameworks, including Android, iOS and Nvidia Jetson devices. We evaluate popular instruction fine-tuned LLMs and leverage different frameworks to measure their end-to-end and granular performance, tracing their memory and energy requirements along the way. Our analysis is the first systematic study of on-device LLM execution, quantifying performance, energy efficiency and accuracy across various state-of-the-art models and showcases the state of on-device intelligence in the era of hyperscale models. Results highlight the performance heterogeneity across targets and corroborates that LLM inference is largely memory-bound. Quantization drastically reduces memory requirements and renders execution viable, but at a non-negligible accuracy cost. Drawing from its energy footprint and thermal behavior, the continuous execution of LLMs remains elusive, as both factors negatively affect user experience. Last, our experience shows that the ecosystem is still in its infancy, and algorithmic as well as hardware breakthroughs can significantly shift the execution cost. We expect NPU acceleration, and framework-hardware co-design to be the biggest bet towards efficient standalone execution, with the alternative of offloading tailored towards edge deployments.
A collection of the accepted papers for the Human-Centric Representation Learning workshop at AAAI 2024
Mar 14, 2024This non-archival index is not complete, as some accepted papers chose to opt-out of inclusion. The list of all accepted papers is available on the workshop website.
Maestro: Uncovering Low-Rank Structures via Trainable Decomposition
Aug 28, 2023Deep Neural Networks (DNNs) have been a large driver and enabler for AI breakthroughs in recent years. These models have been getting larger in their attempt to become more accurate and tackle new upcoming use-cases, including AR/VR and intelligent assistants. However, the training process of such large models is a costly and time-consuming process, which typically yields a single model to fit all targets. To mitigate this, various techniques have been proposed in the literature, including pruning, sparsification or quantization of the model weights and updates. While able to achieve high compression rates, they often incur computational overheads or accuracy penalties. Alternatively, factorization methods have been leveraged to incorporate low-rank compression in the training process. Similarly, such techniques (e.g.,~SVD) frequently rely on the computationally expensive decomposition of layers and are potentially sub-optimal for non-linear models, such as DNNs. In this work, we take a further step in designing efficient low-rank models and propose Maestro, a framework for trainable low-rank layers. Instead of regularly applying a priori decompositions such as SVD, the low-rank structure is built into the training process through a generalized variant of Ordered Dropout. This method imposes an importance ordering via sampling on the decomposed DNN structure. Our theoretical analysis demonstrates that our method recovers the SVD decomposition of linear mapping on uniformly distributed data and PCA for linear autoencoders. We further apply our technique on DNNs and empirically illustrate that Maestro enables the extraction of lower footprint models that preserve model performance while allowing for graceful accuracy-latency tradeoff for the deployment to devices of different capabilities.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022



Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.
The Future of Consumer Edge-AI Computing
Oct 19, 2022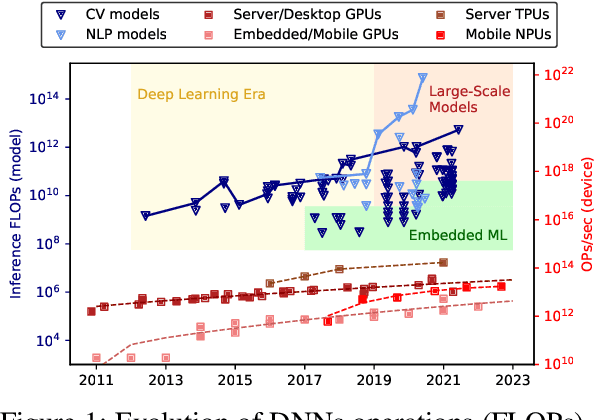
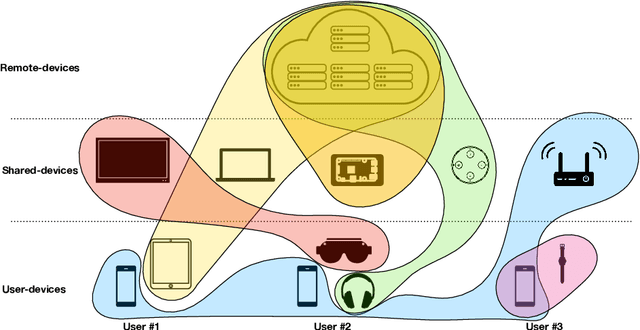

Deep Learning has proliferated dramatically across consumer devices in less than a decade, but has been largely powered through the hardware acceleration within isolated devices. Nonetheless, clear signals exist that the next decade of consumer intelligence will require levels of resources, a mixing of modalities and a collaboration of devices that will demand a significant pivot beyond hardware alone. To accomplish this, we believe a new Edge-AI paradigm will be necessary for this transition to be possible in a sustainable manner, without trespassing user-privacy or hurting quality of experience.