 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELTing point: Mobile Evaluation of Language Transformers
Mar 20, 2024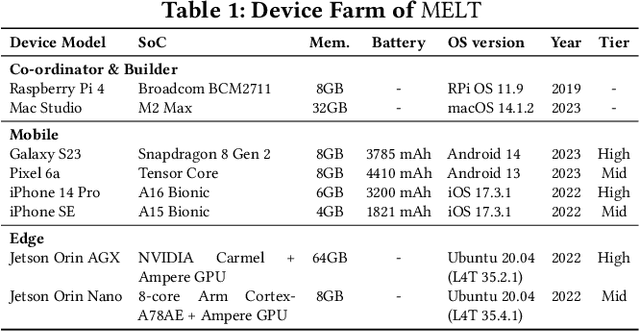
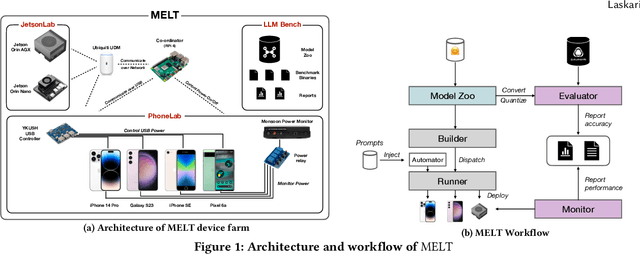

Transformers have revolutionized the machine learning landscape, gradually making their way into everyday tasks and equipping our computers with ``sparks of intelligence''. However, their runtime requirements have prevented them from being broadly deployed on mobile. As personal devices become increasingly powerful and prompt privacy becomes an ever more pressing issue, we explore the current state of mobile execution of Large Language Models (LLMs). To achieve this, we have created our own automation infrastructure, MELT, which supports the headless execution and benchmarking of LLMs on device, supporting different models, devices and frameworks, including Android, iOS and Nvidia Jetson devices. We evaluate popular instruction fine-tuned LLMs and leverage different frameworks to measure their end-to-end and granular performance, tracing their memory and energy requirements along the way. Our analysis is the first systematic study of on-device LLM execution, quantifying performance, energy efficiency and accuracy across various state-of-the-art models and showcases the state of on-device intelligence in the era of hyperscale models. Results highlight the performance heterogeneity across targets and corroborates that LLM inference is largely memory-bound. Quantization drastically reduces memory requirements and renders execution viable, but at a non-negligible accuracy cost. Drawing from its energy footprint and thermal behavior, the continuous execution of LLMs remains elusive, as both factors negatively affect user experience. Last, our experience shows that the ecosystem is still in its infancy, and algorithmic as well as hardware breakthroughs can significantly shift the execution cost. We expect NPU acceleration, and framework-hardware co-design to be the biggest bet towards efficient standalone execution, with the alternative of offloading tailored towards edge deployments.
Stronger Privacy for Federated Collaborative Filtering with Implicit Feedback
May 11, 2021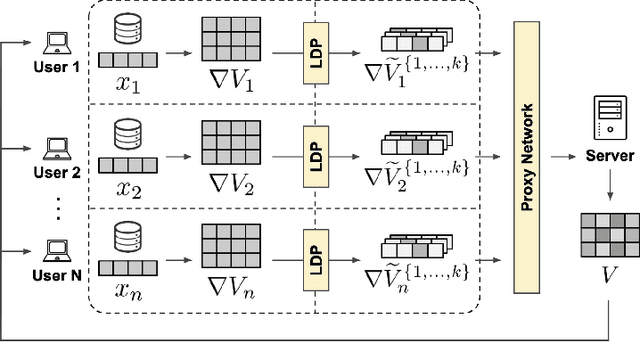
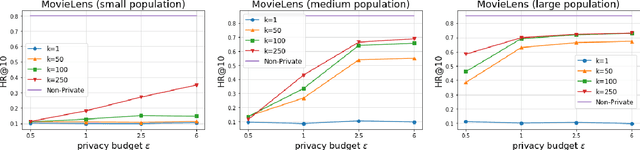
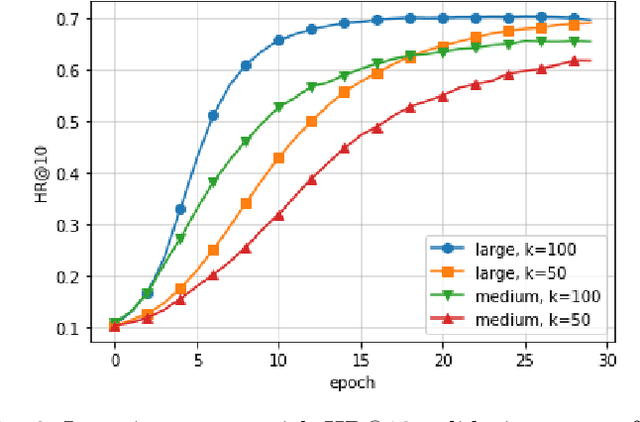
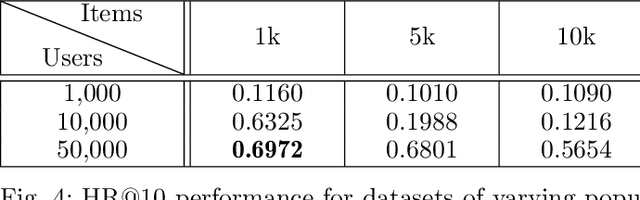
Recommender systems are commonly trained on centrally collected user interaction data like views or clicks. This practice however raises serious privacy concerns regarding the recommender's collection and handling of potentially sensitive data. Several privacy-aware recommender systems have been proposed in recent literature, but comparatively little attention has been given to systems at the intersection of implicit feedback and privacy. To address this shortcoming, we propose a practical federated recommender system for implicit data under user-level local differential privacy (LDP). The privacy-utility trade-off is controlled by parameters $\epsilon$ and $k$, regulating the per-update privacy budget and the number of $\epsilon$-LDP gradient updates sent by each user respectively. To further protect the user's privacy, we introduce a proxy network to reduce the fingerprinting surface by anonymizing and shuffling the reports before forwarding them to the recommender. We empirically demonstrate the effectiveness of our framework on the MovieLens dataset, achieving up to Hit Ratio with K=10 (HR@10) 0.68 on 50k users with 5k items. Even on the full dataset, we show that it is possible to achieve reasonable utility with HR@10>0.5 without compromising user privacy.