 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELTing point: Mobile Evaluation of Language Transformers
Mar 20, 2024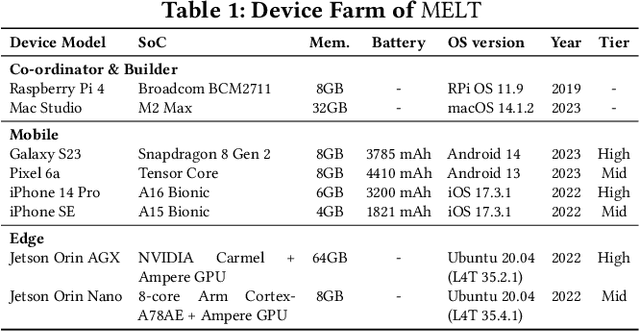
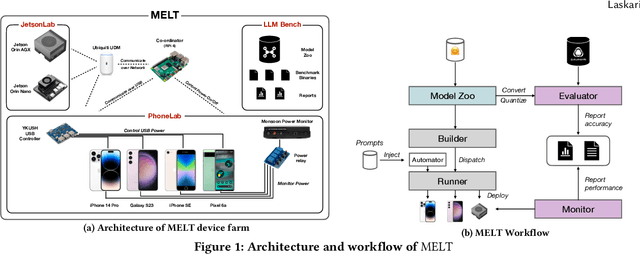

Transformers have revolutionized the machine learning landscape, gradually making their way into everyday tasks and equipping our computers with ``sparks of intelligence''. However, their runtime requirements have prevented them from being broadly deployed on mobile. As personal devices become increasingly powerful and prompt privacy becomes an ever more pressing issue, we explore the current state of mobile execution of Large Language Models (LLMs). To achieve this, we have created our own automation infrastructure, MELT, which supports the headless execution and benchmarking of LLMs on device, supporting different models, devices and frameworks, including Android, iOS and Nvidia Jetson devices. We evaluate popular instruction fine-tuned LLMs and leverage different frameworks to measure their end-to-end and granular performance, tracing their memory and energy requirements along the way. Our analysis is the first systematic study of on-device LLM execution, quantifying performance, energy efficiency and accuracy across various state-of-the-art models and showcases the state of on-device intelligence in the era of hyperscale models. Results highlight the performance heterogeneity across targets and corroborates that LLM inference is largely memory-bound. Quantization drastically reduces memory requirements and renders execution viable, but at a non-negligible accuracy cost. Drawing from its energy footprint and thermal behavior, the continuous execution of LLMs remains elusive, as both factors negatively affect user experience. Last, our experience shows that the ecosystem is still in its infancy, and algorithmic as well as hardware breakthroughs can significantly shift the execution cost. We expect NPU acceleration, and framework-hardware co-design to be the biggest bet towards efficient standalone execution, with the alternative of offloading tailored towards edge deployments.
P4L: Privacy Preserving Peer-to-Peer Learning for Infrastructureless Setups
Feb 26, 2023



Distributed (or Federated) learning enables users to train machine learning models on their very own devices, while they share only the gradients of their models usually in a differentially private way (utility loss). Although such a strategy provides better privacy guarantees than the traditional centralized approach, it requires users to blindly trust a centralized infrastructure that may also become a bottleneck with the increasing number of users. In this paper, we design and implement P4L: a privacy preserving peer-to-peer learning system for users to participate in an asynchronous, collaborative learning scheme without requiring any sort of infrastructure or relying on differential privacy. Our design uses strong cryptographic primitives to preserve both the confidentiality and utility of the shared gradients, a set of peer-to-peer mechanisms for fault tolerance and user churn, proximity and cross device communications. Extensive simulations under different network settings and ML scenarios for three real-life datasets show that P4L provides competitive performance to baselines, while it is resilient to different poisoning attacks. We implement P4L and experimental results show that the performance overhead and power consumption is minimal (less than 3mAh of discharge).
Choosing the Best of Both Worlds: Diverse and Novel Recommendations through Multi-Objective Reinforcement Learning
Oct 28, 2021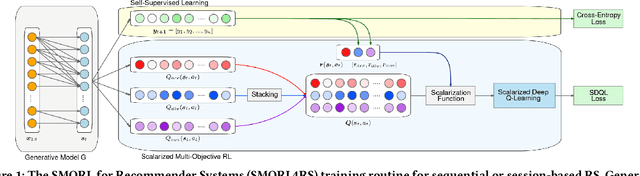
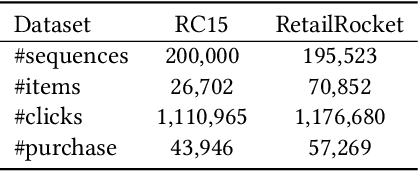

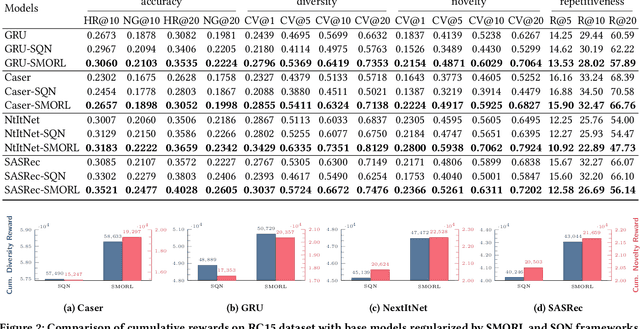
Since the inception of Recommender Systems (RS), the accuracy of the recommendations in terms of relevance has been the golden criterion for evaluating the quality of RS algorithms. However, by focusing on item relevance, one pays a significant price in terms of other important metrics: users get stuck in a "filter bubble" and their array of options is significantly reduced, hence degrading the quality of the user experience and leading to churn. Recommendation, and in particular session-based/sequential recommendation, is a complex task with multiple - and often conflicting objectives - that existing state-of-the-art approaches fail to address. In this work, we take on the aforementioned challenge and introduce Scalarized Multi-Objective Reinforcement Learning (SMORL) for the RS setting, a novel Reinforcement Learning (RL) framework that can effectively address multi-objective recommendation tasks. The proposed SMORL agent augments standard recommendation models with additional RL layers that enforce it to simultaneously satisfy three principal objectives: accuracy, diversity, and novelty of recommendations. We integrate this framework with four state-of-the-art session-based recommendation models and compare it with a single-objective RL agent that only focuses on accuracy. Our experimental results on two real-world datasets reveal a substantial increase in aggregate diversity, a moderate increase in accuracy, reduced repetitiveness of recommendations, and demonstrate the importance of reinforcing diversity and novelty as complementary objectives.
PPFL: Privacy-preserving Federated Learning with Trusted Execution Environments
Apr 29, 2021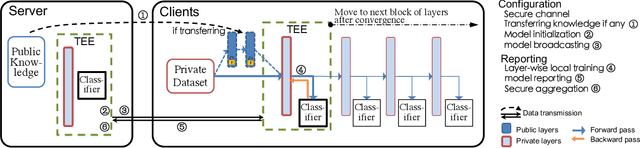

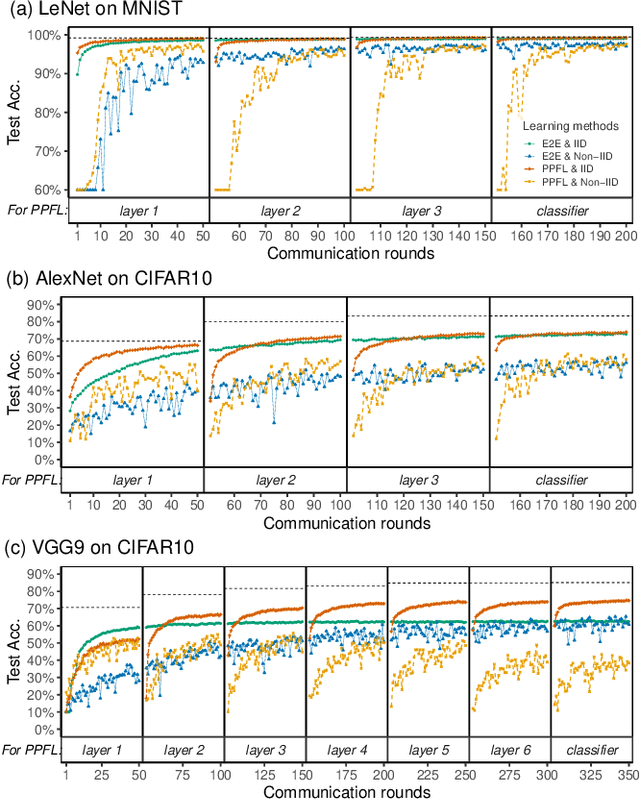
We propose and implement a Privacy-preserving Federated Learning (PPFL) framework for mobile systems to limit privacy leakages in federated learning. Leveraging the widespread presence of Trusted Execution Environments (TEEs) in high-end and mobile devices, we utilize TEEs on clients for local training, and on servers for secure aggregation, so that model/gradient updates are hidden from adversaries. Challenged by the limited memory size of current TEEs, we leverage greedy layer-wise training to train each model's layer inside the trusted area until its convergence. The performance evaluation of our implementation shows that PPFL can significantly improve privacy while incurring small system overheads at the client-side. In particular, PPFL can successfully defend the trained model against data reconstruction, property inference, and membership inference attacks. Furthermore, it can achieve comparable model utility with fewer communication rounds (0.54x) and a similar amount of network traffic (1.002x) compared to the standard federated learning of a complete model. This is achieved while only introducing up to ~15% CPU time, ~18% memory usage, and ~21% energy consumption overhead in PPFL's client-side.
FLaaS: Federated Learning as a Service
Nov 18, 2020
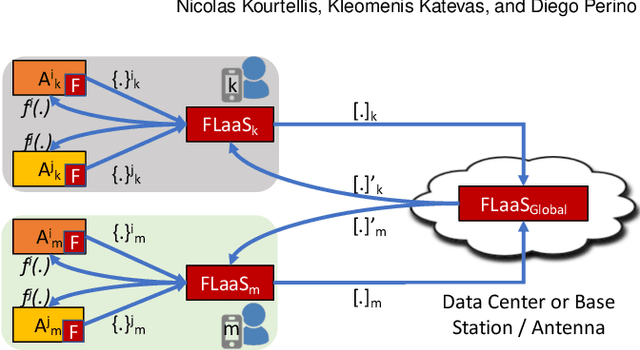
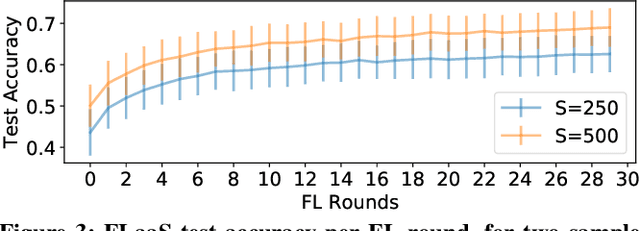
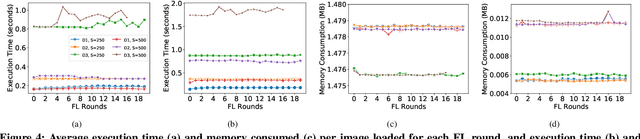
Federated Learning (FL) is emerging as a promising technology to build machine learning models in a decentralized, privacy-preserving fashion. Indeed, FL enables local training on user devices, avoiding user data to be transferred to centralized servers, and can be enhanced with differential privacy mechanisms. Although FL has been recently deployed in real systems, the possibility of collaborative modeling across different 3rd-party applications has not yet been explored. In this paper, we tackle this problem and present Federated Learning as a Service (FLaaS), a system enabling different scenarios of 3rd-party application collaborative model building and addressing the consequent challenges of permission and privacy management, usability, and hierarchical model training. FLaaS can be deployed in different operational environments. As a proof of concept, we implement it on a mobile phone setting and discuss practical implications of results on simulated and real devices with respect to on-device training CPU cost, memory footprint and power consumed per FL model round. Therefore, we demonstrate FLaaS's feasibility in building unique or joint FL models across applications for image object detection in a few hours, across 100 devices.
* 7 pages, 4 figures, 7 subfigures, 34 references
DarkneTZ: Towards Model Privacy at the Edge using Trusted Execution Environments
Apr 12, 2020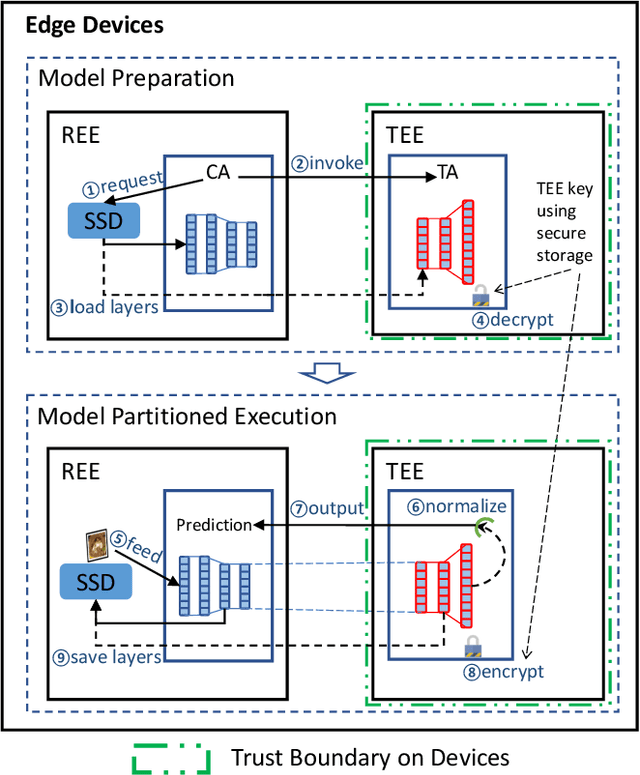
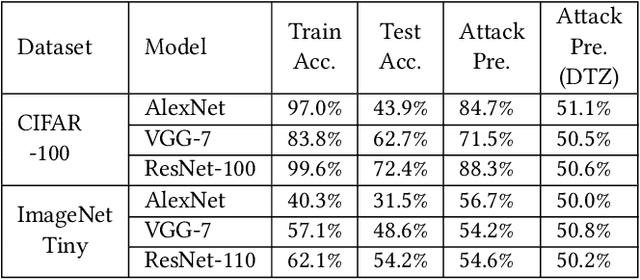
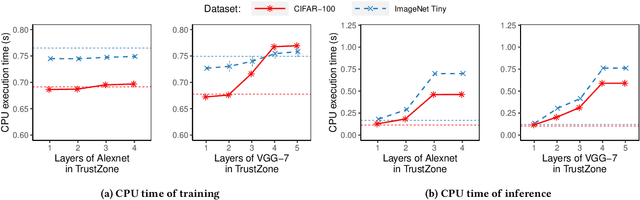
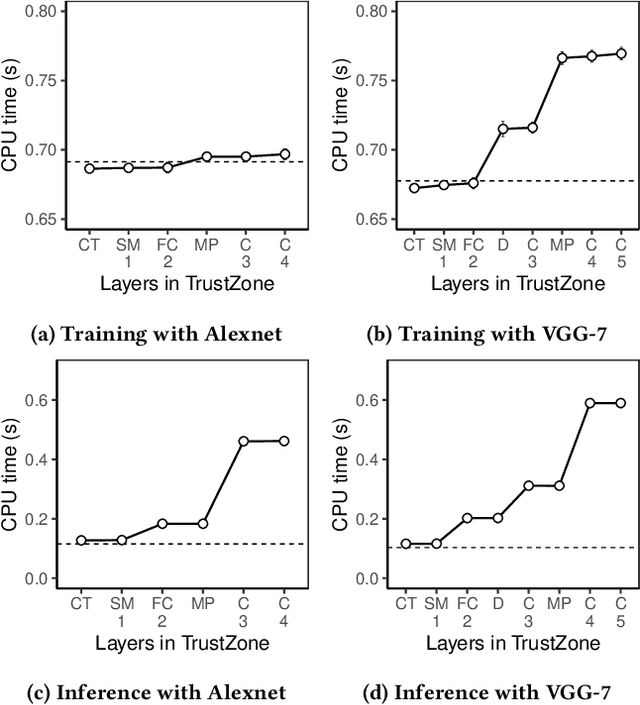
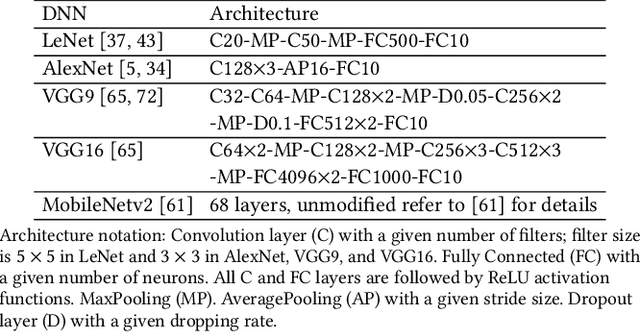
We present DarkneTZ, a framework that uses an edge device's Trusted Execution Environment (TEE) in conjunction with model partitioning to limit the attack surface against Deep Neural Networks (DNNs). Increasingly, edge devices (smartphones and consumer IoT devices) are equipped with pre-trained DNNs for a variety of applications. This trend comes with privacy risks as models can leak information about their training data through effective membership inference attacks (MIAs). We evaluate the performance of DarkneTZ, including CPU execution time, memory usage, and accurate power consumption, using two small and six large image classification models. Due to the limited memory of the edge device's TEE, we partition model layers into more sensitive layers (to be executed inside the device TEE), and a set of layers to be executed in the untrusted part of the operating system. Our results show that even if a single layer is hidden, we can provide reliable model privacy and defend against state of the art MIAs, with only 3% performance overhead. When fully utilizing the TEE, DarkneTZ provides model protections with up to 10% overhead.
Decentralized Policy-Based Private Analytics
Mar 14, 2020

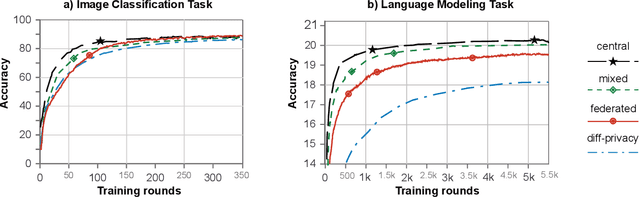
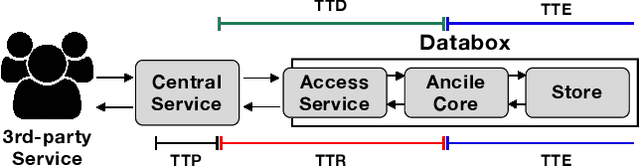
We are increasingly surrounded by applications, connected devices, services, and smart environments which require fine-grained access to various personal data. The inherent complexities of our personal and professional policies and preferences in interactions with these analytics services raise important challenges in privacy. Moreover, due to sensitivity of the data and regulatory and technical barriers, it is not always feasible to do these policy negotiations in a centralized manner. In this paper we present PoliBox, a decentralized, edge-based framework for policy-based personal data analytics. PoliBox brings together a number of existing established components to provide privacy-preserving analytics within a distributed setting. We evaluate our framework using a popular exemplar of private analytics, Federated Learning, and demonstrate that for varying model sizes and use cases, PoliBox is able to perform accurate model training and inference within very reasonable resource and time budgets.
Towards Characterizing and Limiting Information Exposure in DNN Layers
Jul 13, 2019
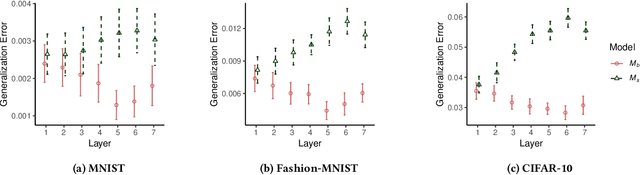
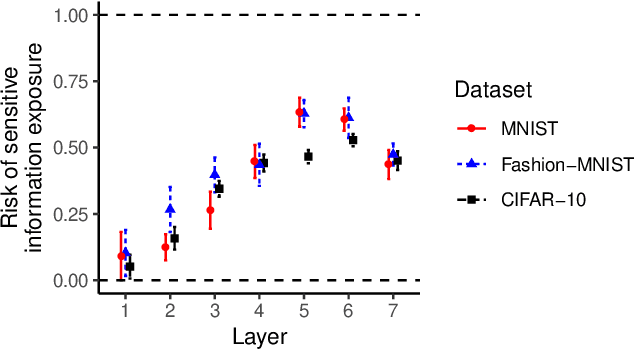
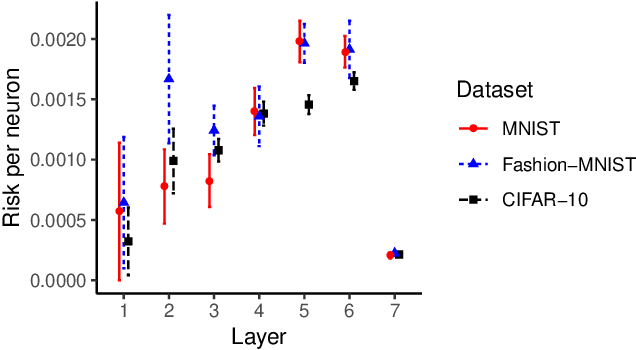
Pre-trained Deep Neural Network (DNN) models are increasingly used in smartphones and other user devices to enable prediction services, leading to potential disclosures of (sensitive) information from training data captured inside these models. Based on the concept of generalization error, we propose a framework to measure the amount of sensitive information memorized in each layer of a DNN. Our results show that, when considered individually, the last layers encode a larger amount of information from the training data compared to the first layers. We find that, while the neuron of convolutional layers can expose more (sensitive) information than that of fully connected layers, the same DNN architecture trained with different datasets has similar exposure per layer. We evaluate an architecture to protect the most sensitive layers within the memory limits of Trusted Execution Environment (TEE) against potential white-box membership inference attacks without the significant computational overhead.
Finding Dory in the Crowd: Detecting Social Interactions using Multi-Modal Mobile Sensing
Aug 30, 2018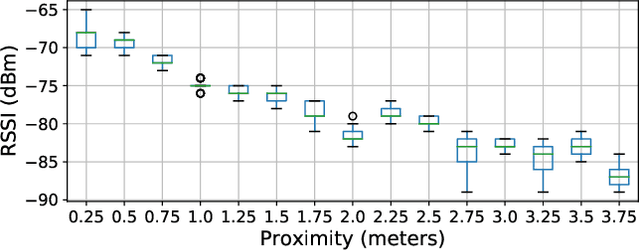
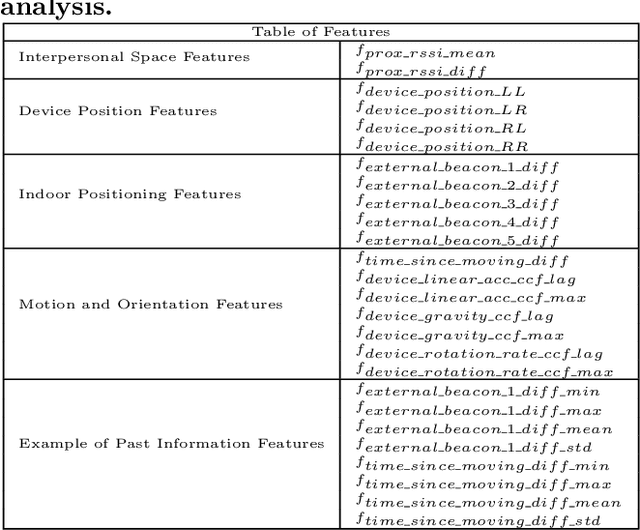
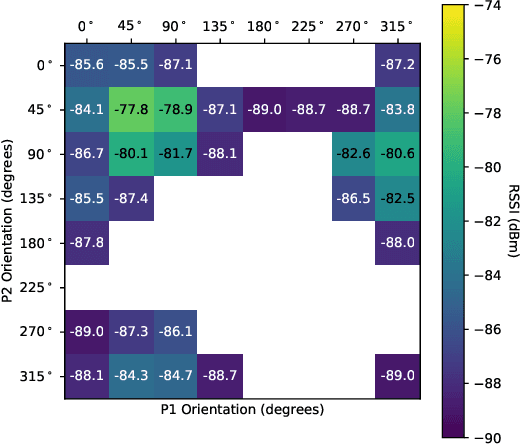
Remembering our day-to-day social interactions is challenging even if you aren't a blue memory challenged fish. The ability to automatically detect and remember these types of interactions is not only beneficial for individuals interested in their behavior in crowded situations, but also of interest to those who analyze crowd behavior. Currently, detecting social interactions is often performed using a variety of methods including ethnographic studies, computer vision techniques and manual annotation-based data analysis. However, mobile phones offer easier means for data collection that is easy to analyze and can preserve the user's privacy. In this work, we present a system for detecting stationary social interactions inside crowds, leveraging multi-modal mobile sensing data such as Bluetooth Smart (BLE), accelerometer and gyroscope. To inform the development of such system, we conducted a study with 24 participants, where we asked them to socialize with each other for 45 minutes. We built a machine learning system based on gradient-boosted trees that predicts both 1:1 and group interactions with 77.8% precision and 86.5% recall, a 30.2% performance increase compared to a proximity-based approach. By utilizing a community detection based method, we further detected the various group formation that exist within the crowd. Using mobile phone sensors already carried by the majority of people in a crowd makes our approach particularly well suited to real-life analysis of crowd behaviour and influence strategies.
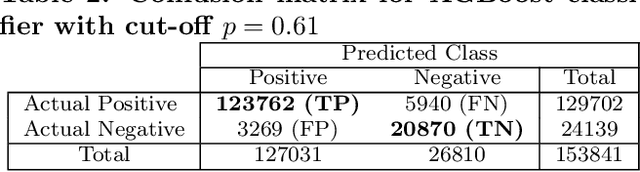
A Hybrid Deep Learning Architecture for Privacy-Preserving Mobile Analytics
Apr 18, 2018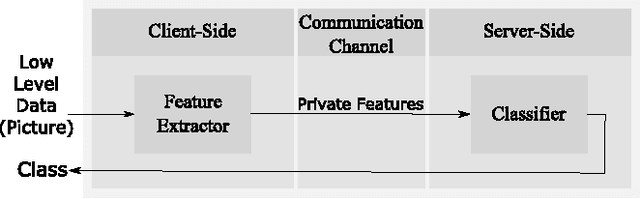
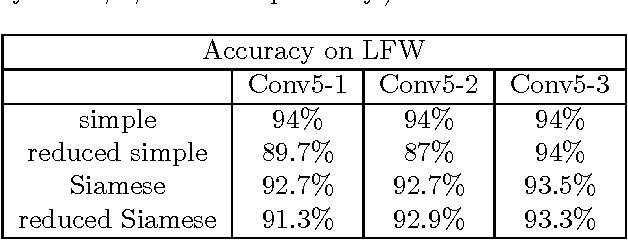
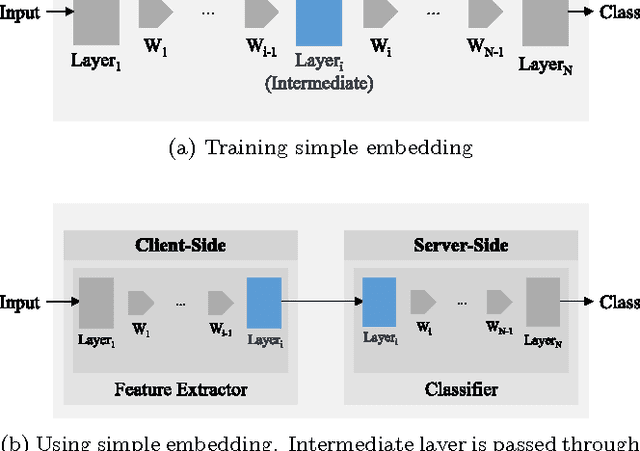
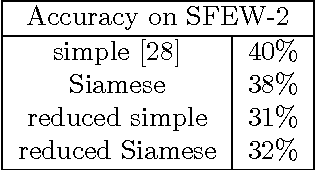
Deep Neural Networks are increasingly being used in a variety of machine learning applications applied to user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a suitable way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also assess the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing cost, we can greatly reduce the level of information available to unintended tasks applied to the data features on the cloud, and hence achieving the desired tradeoff between privacy and performance.