 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP4L: Privacy Preserving Peer-to-Peer Learning for Infrastructureless Setups
Feb 26, 2023



Distributed (or Federated) learning enables users to train machine learning models on their very own devices, while they share only the gradients of their models usually in a differentially private way (utility loss). Although such a strategy provides better privacy guarantees than the traditional centralized approach, it requires users to blindly trust a centralized infrastructure that may also become a bottleneck with the increasing number of users. In this paper, we design and implement P4L: a privacy preserving peer-to-peer learning system for users to participate in an asynchronous, collaborative learning scheme without requiring any sort of infrastructure or relying on differential privacy. Our design uses strong cryptographic primitives to preserve both the confidentiality and utility of the shared gradients, a set of peer-to-peer mechanisms for fault tolerance and user churn, proximity and cross device communications. Extensive simulations under different network settings and ML scenarios for three real-life datasets show that P4L provides competitive performance to baselines, while it is resilient to different poisoning attacks. We implement P4L and experimental results show that the performance overhead and power consumption is minimal (less than 3mAh of discharge).
FNDaaS: Content-agnostic Detection of Fake News sites
Dec 13, 2022Automatic fake news detection is a challenging problem in misinformation spreading, and it has tremendous real-world political and social impacts. Past studies have proposed machine learning-based methods for detecting such fake news, focusing on different properties of the published news articles, such as linguistic characteristics of the actual content, which however have limitations due to the apparent language barriers. Departing from such efforts, we propose FNDaaS, the first automatic, content-agnostic fake news detection method, that considers new and unstudied features such as network and structural characteristics per news website. This method can be enforced as-a-Service, either at the ISP-side for easier scalability and maintenance, or user-side for better end-user privacy. We demonstrate the efficacy of our method using data crawled from existing lists of 637 fake and 1183 real news websites, and by building and testing a proof of concept system that materializes our proposal. Our analysis of data collected from these websites shows that the vast majority of fake news domains are very young and appear to have lower time periods of an IP associated with their domain than real news ones. By conducting various experiments with machine learning classifiers, we demonstrate that FNDaaS can achieve an AUC score of up to 0.967 on past sites, and up to 77-92% accuracy on newly-flagged ones.
The Rise and Fall of Fake News sites: A Traffic Analysis
Mar 16, 2021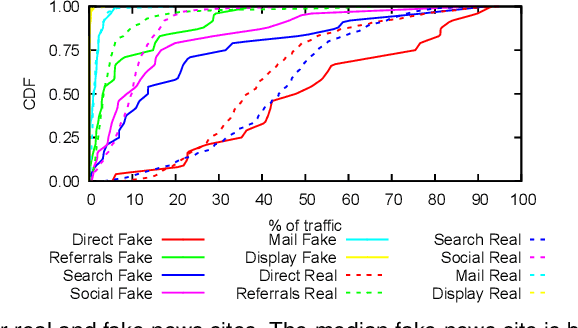
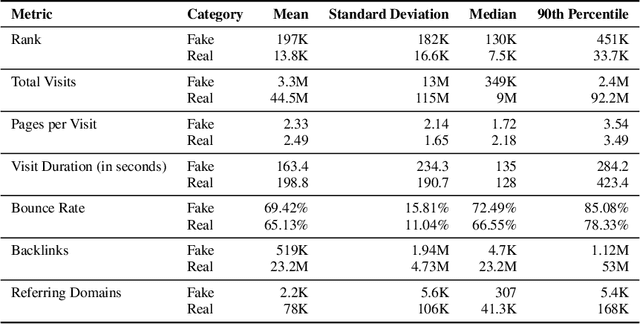
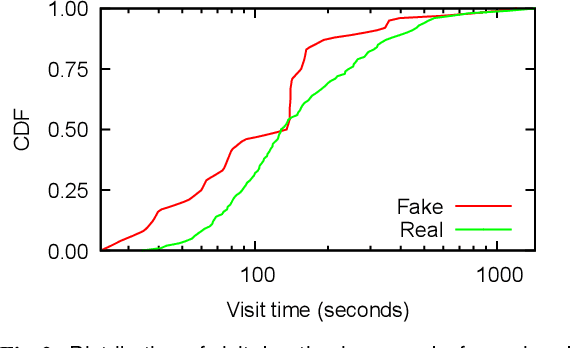

Over the past decade, we have witnessed the rise of misinformation on the Internet, with online users constantly falling victims of fake news. A multitude of past studies have analyzed fake news diffusion mechanics and detection and mitigation techniques. However, there are still open questions about their operational behavior such as: How old are fake news websites? Do they typically stay online for long periods of time? Do such websites synchronize with each other their up and down time? Do they share similar content through time? Which third-parties support their operations? How much user traffic do they attract, in comparison to mainstream or real news websites? In this paper, we perform a first of its kind investigation to answer such questions regarding the online presence of fake news websites and characterize their behavior in comparison to real news websites. Based on our findings, we build a content-agnostic ML classifier for automatic detection of fake news websites (i.e. accuracy) that are not yet included in manually curated blacklists.