 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Heterogeneity and Forgotten Labels in Split Federated Learning
Nov 12, 2025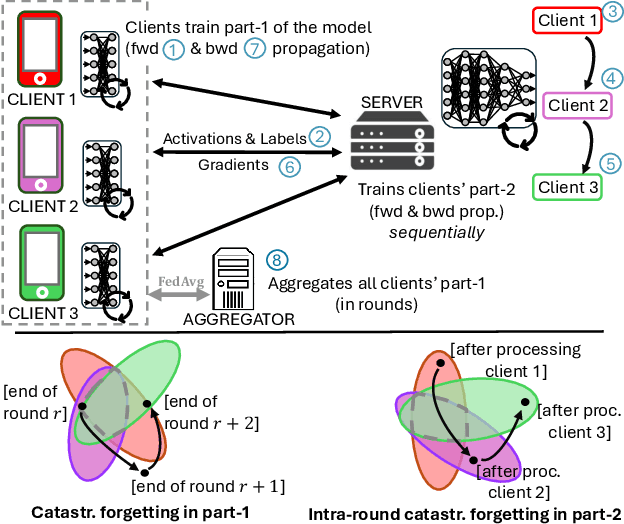
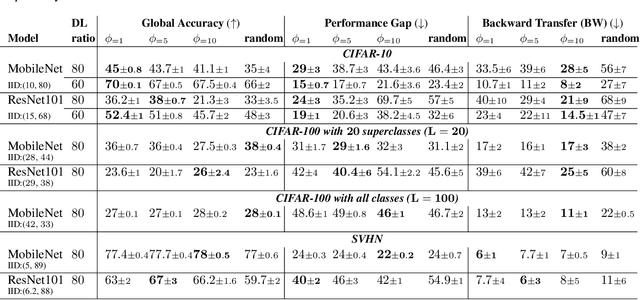


In Split Federated Learning (SFL), the clients collaboratively train a model with the help of a server by splitting the model into two parts. Part-1 is trained locally at each client and aggregated by the aggregator at the end of each round. Part-2 is trained at a server that sequentially processes the intermediate activations received from each client. We study the phenomenon of catastrophic forgetting (CF) in SFL in the presence of data heterogeneity. In detail, due to the nature of SFL, local updates of part-1 may drift away from global optima, while part-2 is sensitive to the processing sequence, similar to forgetting in continual learning (CL). Specifically, we observe that the trained model performs better in classes (labels) seen at the end of the sequence. We investigate this phenomenon with emphasis on key aspects of SFL, such as the processing order at the server and the cut layer. Based on our findings, we propose Hydra, a novel mitigation method inspired by multi-head neural networks and adapted for the SFL's setting. Extensive numerical evaluations show that Hydra outperforms baselines and methods from the literature.
Non-IID data in Federated Learning: A Systematic Review with Taxonomy, Metrics, Methods, Frameworks and Future Directions
Nov 19, 2024Recent advances in machine learning have highlighted Federated Learning (FL) as a promising approach that enables multiple distributed users (so-called clients) to collectively train ML models without sharing their private data. While this privacy-preserving method shows potential, it struggles when data across clients is not independent and identically distributed (non-IID) data. The latter remains an unsolved challenge that can result in poorer model performance and slower training times. Despite the significance of non-IID data in FL, there is a lack of consensus among researchers about its classification and quantification. This systematic review aims to fill that gap by providing a detailed taxonomy for non-IID data, partition protocols, and metrics to quantify data heterogeneity. Additionally, we describe popular solutions to address non-IID data and standardized frameworks employed in FL with heterogeneous data. Based on our state-of-the-art review, we present key lessons learned and suggest promising future research directions.
PUFFLE: Balancing Privacy, Utility, and Fairness in Federated Learning
Jul 21, 2024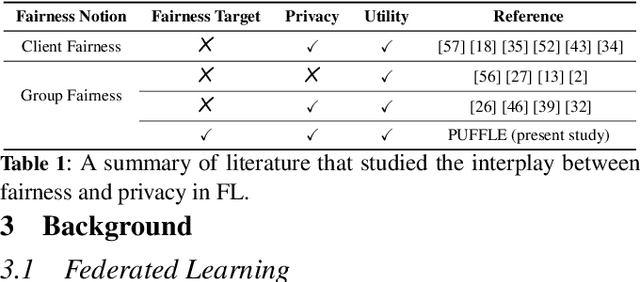
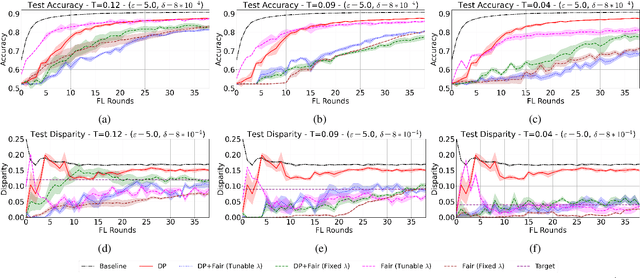
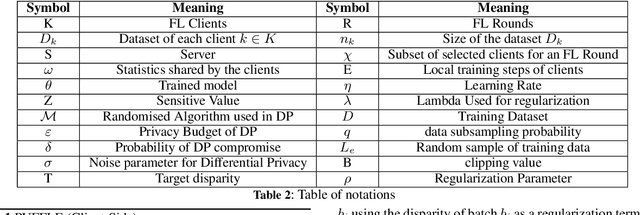
Training and deploying Machine Learning models that simultaneously adhere to principles of fairness and privacy while ensuring good utility poses a significant challenge. The interplay between these three factors of trustworthiness is frequently underestimated and remains insufficiently explored. Consequently, many efforts focus on ensuring only two of these factors, neglecting one in the process. The decentralization of the datasets and the variations in distributions among the clients exacerbate the complexity of achieving this ethical trade-off in the context of Federated Learning (FL). For the first time in FL literature, we address these three factors of trustworthiness. We introduce PUFFLE, a high-level parameterised approach that can help in the exploration of the balance between utility, privacy, and fairness in FL scenarios. We prove that PUFFLE can be effective across diverse datasets, models, and data distributions, reducing the model unfairness up to 75%, with a maximum reduction in the utility of 17% in the worst-case scenario, while maintaining strict privacy guarantees during the FL training.
Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Mar 08, 2024



As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 69 input perturbations which are intended to simulate various corruptions that ASR models may encounter in the physical and digital world. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as discrete representations, and self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females, and observed noticeable disparities in the model's robustness across subgroups. We believe that SRB will facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset
Jan 18, 2024The accuracy and fairness of perception systems in autonomous driving are crucial, particularly for vulnerable road users. Mainstream research has looked into improving the performance metrics for classification accuracy. However, the hidden traits of bias inheritance in the AI models, class imbalances and disparities in the datasets are often overlooked. In this context, our study examines the class imbalances for vulnerable road users by focusing on class distribution analysis, performance evaluation, and bias impact assessment. We identify the concern of imbalances in class representation, leading to potential biases in detection accuracy. Utilizing popular CNN models and Vision Transformers (ViTs) with the nuScenes dataset, our performance evaluation reveals detection disparities for underrepresented classes. We propose a methodology for model optimization and bias mitigation, which includes data augmentation, resampling, and metric-specific learning. Using the proposed mitigation approaches, we see improvement in IoU(%) and NDS(%) metrics from 71.3 to 75.6 and 80.6 to 83.7 respectively, for the CNN model. Similarly, for ViT, we observe improvement in IoU and NDS metrics from 74.9 to 79.2 and 83.8 to 87.1 respectively. This research contributes to developing more reliable models and datasets, enhancing inclusiveness for minority classes.
Poster: Sponge ML Model Attacks of Mobile Apps
Mar 01, 2023
Machine Learning (ML)-powered apps are used in pervasive devices such as phones, tablets, smartwatches and IoT devices. Recent advances in collaborative, distributed ML such as Federated Learning (FL) attempt to solve privacy concerns of users and data owners, and thus used by tech industry leaders such as Google, Facebook and Apple. However, FL systems and models are still vulnerable to adversarial membership and attribute inferences and model poisoning attacks, especially in FL-as-a-Service ecosystems recently proposed, which can enable attackers to access multiple ML-powered apps. In this work, we focus on the recently proposed Sponge attack: It is designed to soak up energy consumed while executing inference (not training) of ML model, without hampering the classifier's performance. Recent work has shown sponge attacks on ASCI-enabled GPUs can potentially escalate the power consumption and inference time. For the first time, in this work, we investigate this attack in the mobile setting and measure the effect it can have on ML models running inside apps on mobile devices.
FNDaaS: Content-agnostic Detection of Fake News sites
Dec 13, 2022
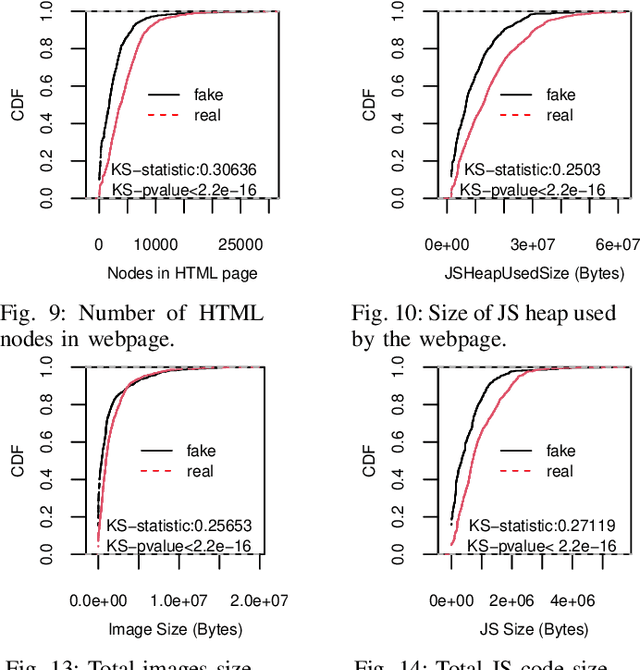


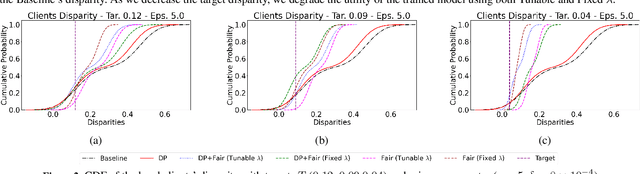
Automatic fake news detection is a challenging problem in misinformation spreading, and it has tremendous real-world political and social impacts. Past studies have proposed machine learning-based methods for detecting such fake news, focusing on different properties of the published news articles, such as linguistic characteristics of the actual content, which however have limitations due to the apparent language barriers. Departing from such efforts, we propose FNDaaS, the first automatic, content-agnostic fake news detection method, that considers new and unstudied features such as network and structural characteristics per news website. This method can be enforced as-a-Service, either at the ISP-side for easier scalability and maintenance, or user-side for better end-user privacy. We demonstrate the efficacy of our method using data crawled from existing lists of 637 fake and 1183 real news websites, and by building and testing a proof of concept system that materializes our proposal. Our analysis of data collected from these websites shows that the vast majority of fake news domains are very young and appear to have lower time periods of an IP associated with their domain than real news ones. By conducting various experiments with machine learning classifiers, we demonstrate that FNDaaS can achieve an AUC score of up to 0.967 on past sites, and up to 77-92% accuracy on newly-flagged ones.
Privacy-Preserving Online Content Moderation: A Federated Learning Use Case
Sep 23, 2022



Users are daily exposed to a large volume of harmful content on various social network platforms. One solution is developing online moderation tools using Machine Learning techniques. However, the processing of user data by online platforms requires compliance with privacy policies. Federated Learning (FL) is an ML paradigm where the training is performed locally on the users' devices. Although the FL framework complies, in theory, with the GDPR policies, privacy leaks can still occur. For instance, an attacker accessing the final trained model can successfully perform unwanted inference of the data belonging to the users who participated in the training process. In this paper, we propose a privacy-preserving FL framework for online content moderation that incorporates Differential Privacy (DP). To demonstrate the feasibility of our approach, we focus on detecting harmful content on Twitter - but the overall concept can be generalized to other types of misbehavior. We simulate a text classifier - in FL fashion - which can detect tweets with harmful content. We show that the performance of the proposed FL framework can be close to the centralized approach - for both the DP and non-DP FL versions. Moreover, it has a high performance even if a small number of clients (each with a small number of data points) are available for the FL training. When reducing the number of clients (from 50 to 10) or the data points per client (from 1K to 0.1K), the classifier can still achieve ~81% AUC. Furthermore, we extend the evaluation to four other Twitter datasets that capture different types of user misbehavior and still obtain a promising performance (61% - 80% AUC). Finally, we explore the overhead on the users' devices during the FL training phase and show that the local training does not introduce excessive CPU utilization and memory consumption overhead.
Hierarchical Federated Learning with Privacy
Jun 10, 2022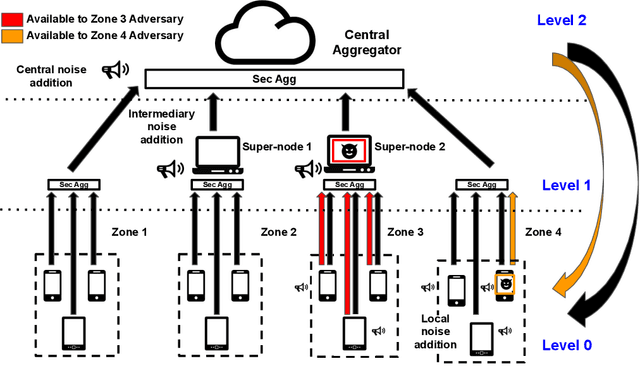
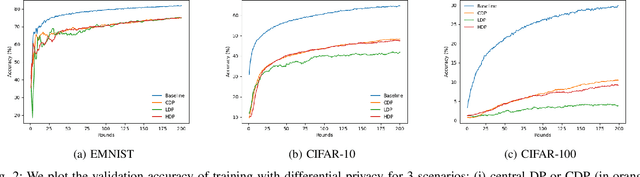
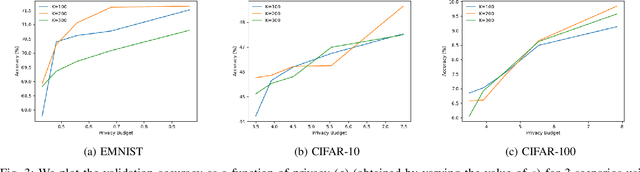

Federated learning (FL), where data remains at the federated clients, and where only gradient updates are shared with a central aggregator, was assumed to be private. Recent work demonstrates that adversaries with gradient-level access can mount successful inference and reconstruction attacks. In such settings, differentially private (DP) learning is known to provide resilience. However, approaches used in the status quo (\ie central and local DP) introduce disparate utility vs. privacy trade-offs. In this work, we take the first step towards mitigating such trade-offs through {\em hierarchical FL (HFL)}. We demonstrate that by the introduction of a new intermediary level where calibrated DP noise can be added, better privacy vs. utility trade-offs can be obtained; we term this {\em hierarchical DP (HDP)}. Our experiments with 3 different datasets (commonly used as benchmarks for FL) suggest that HDP produces models as accurate as those obtained using central DP, where noise is added at a central aggregator. Such an approach also provides comparable benefit against inference adversaries as in the local DP case, where noise is added at the federated clients.
PPFL: Privacy-preserving Federated Learning with Trusted Execution Environments
Apr 29, 2021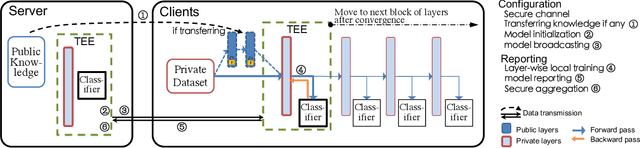
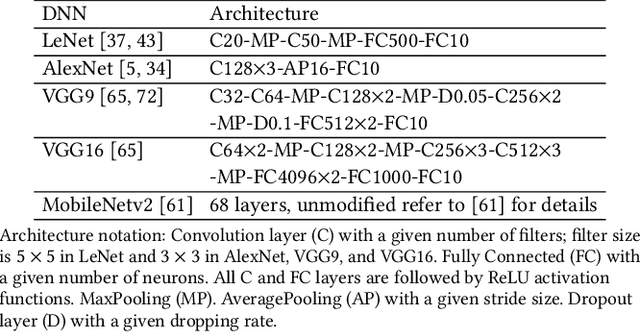

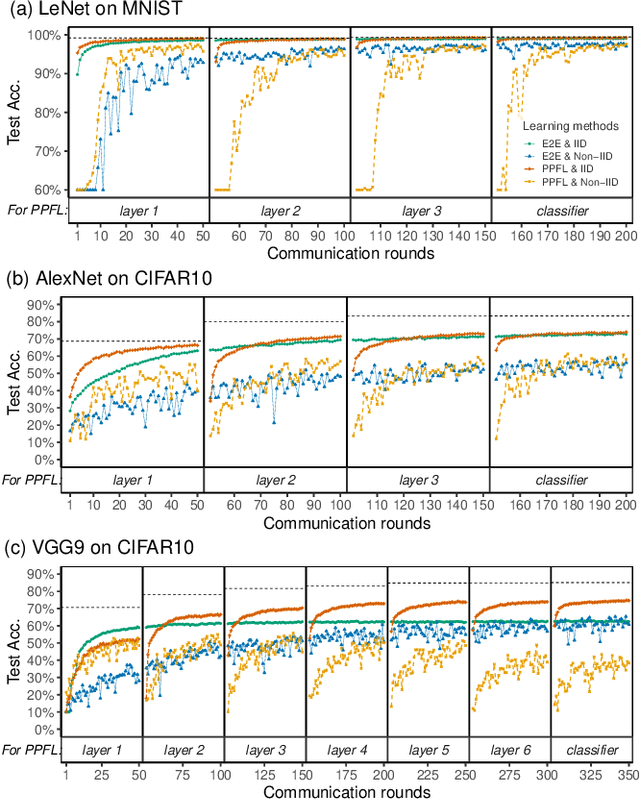
We propose and implement a Privacy-preserving Federated Learning (PPFL) framework for mobile systems to limit privacy leakages in federated learning. Leveraging the widespread presence of Trusted Execution Environments (TEEs) in high-end and mobile devices, we utilize TEEs on clients for local training, and on servers for secure aggregation, so that model/gradient updates are hidden from adversaries. Challenged by the limited memory size of current TEEs, we leverage greedy layer-wise training to train each model's layer inside the trusted area until its convergence. The performance evaluation of our implementation shows that PPFL can significantly improve privacy while incurring small system overheads at the client-side. In particular, PPFL can successfully defend the trained model against data reconstruction, property inference, and membership inference attacks. Furthermore, it can achieve comparable model utility with fewer communication rounds (0.54x) and a similar amount of network traffic (1.002x) compared to the standard federated learning of a complete model. This is achieved while only introducing up to ~15% CPU time, ~18% memory usage, and ~21% energy consumption overhead in PPFL's client-side.