 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidaPA: Privacy-Preserving Chatbot for Public Administration via Federated Learning
May 31, 2026We present GuidaPA, a privacy-preserving chatbot for the Italian Public Administration (PA) trained via Federated Learning (FL) on documentation from two national PA platforms, SIGESON and SIDFORS. Our corpus includes approximately 8 pages of SIGESON manuals and 31 pages of SIDFORS manuals/FAQs; while this study uses public documentation as a safe proxy, the intended deployment extends to restricted internal sources (e.g., tickets, officer manuals, database extracts) that can not be centrally pooled due to regulatory and organizational constraints. GuidaPA integrates role-based access control, secure client-side preprocessing, explicit monitoring of non-IID effects, and parameter-efficient federated fine-tuning of large language models. Using QLoRA (4-bit) over 15 federated rounds with an 80/20 train-test split per client, we evaluate answer quality with ROUGE, BLEU-4, and METEOR. The best federated model achieves ROUGE-1/2/L of 61.10/55.77/59.44, BLEU-4 of 45.02, and METEOR of 63.94-close to private centralized fine-tuning while keeping data on-site. Compared to the general-purpose baseline, domain fine-tuning improves ROUGE-1 from 41.45 to 62.18 and BLEU-4 from 26.97 to 50.90. Overall, the results indicate that FL can deliver high-quality conversational AI for public services without centralized data sharing
FedLECC: Cluster- and Loss-Guided Client Selection for Federated Learning under Non-IID Data
Mar 09, 2026Federated Learning (FL) enables distributed Artificial Intelligence (AI) across cloud-edge environments by allowing collaborative model training without centralizing data. In cross-device deployments, FL systems face strict communication and participation constraints, as well as strong non-independent and identically distributed (non-IID) data that degrades convergence and model quality. Since only a subset of devices (a.k.a clients) can participate per training round, intelligent client selection becomes a key systems challenge. This paper proposes FedLECC (Federated Learning with Enhanced Cluster Choice), a lightweight, cluster-aware, and loss-guided client selection strategy for cross-device FL. FedLECC groups clients by label-distribution similarity and prioritizes clusters and clients with higher local loss, enabling the selection of a small yet informative and diverse set of clients. Experimental results under severe label skew show that FedLECC improves test accuracy by up to 12%, while reducing communication rounds by approximately 22% and overall communication overhead by up to 50% compared to strong baselines. These results demonstrate that informed client selection improves the efficiency and scalability of FL workloads in cloud-edge systems.
A Proof of Concept for a Digital Twin of an Ultrasonic Fermentation System
Jan 16, 2026This paper presents the design and implementation of a proof of concept digital twin for an innovative ultrasonic-enhanced beer-fermentation system, developed to enable intelligent monitoring, prediction, and actuation in yeast-growth environments. A traditional fermentation tank is equipped with a piezoelectric transducer able to irradiate the tank with ultrasonic waves, providing an external abiotic stimulus to enhance the growth of yeast and accelerate the fermentation process. At its core, the digital twin incorporates a predictive model that estimates yeast's culture density over time based on the surrounding environmental conditions. To this end, we implement, tailor and extend the model proposed in Palacios et al., allowing us to effectively handle the limited number of available training samples by using temperature, ultrasonic frequency, and duty cycle as inputs. The results obtained along with the assessment of model performance demonstrate the feasibility of the proposed approach.
Clust-PSI-PFL: A Population Stability Index Approach for Clustered Non-IID Personalized Federated Learning
Dec 23, 2025Federated learning (FL) supports privacy-preserving, decentralized machine learning (ML) model training by keeping data on client devices. However, non-independent and identically distributed (non-IID) data across clients biases updates and degrades performance. To alleviate these issues, we propose Clust-PSI-PFL, a clustering-based personalized FL framework that uses the Population Stability Index (PSI) to quantify the level of non-IID data. We compute a weighted PSI metric, $WPSI^L$, which we show to be more informative than common non-IID metrics (Hellinger, Jensen-Shannon, and Earth Mover's distance). Using PSI features, we form distributionally homogeneous groups of clients via K-means++; the number of optimal clusters is chosen by a systematic silhouette-based procedure, typically yielding few clusters with modest overhead. Across six datasets (tabular, image, and text modalities), two partition protocols (Dirichlet with parameter $α$ and Similarity with parameter S), and multiple client sizes, Clust-PSI-PFL delivers up to 18% higher global accuracy than state-of-the-art baselines and markedly improves client fairness by a relative improvement of 37% under severe non-IID data. These results establish PSI-guided clustering as a principled, lightweight mechanism for robust PFL under label skew.
Non-IID data in Federated Learning: A Systematic Review with Taxonomy, Metrics, Methods, Frameworks and Future Directions
Nov 19, 2024Recent advances in machine learning have highlighted Federated Learning (FL) as a promising approach that enables multiple distributed users (so-called clients) to collectively train ML models without sharing their private data. While this privacy-preserving method shows potential, it struggles when data across clients is not independent and identically distributed (non-IID) data. The latter remains an unsolved challenge that can result in poorer model performance and slower training times. Despite the significance of non-IID data in FL, there is a lack of consensus among researchers about its classification and quantification. This systematic review aims to fill that gap by providing a detailed taxonomy for non-IID data, partition protocols, and metrics to quantify data heterogeneity. Additionally, we describe popular solutions to address non-IID data and standardized frameworks employed in FL with heterogeneous data. Based on our state-of-the-art review, we present key lessons learned and suggest promising future research directions.
Predicting Award Winning Research Papers at Publication Time
Jun 18, 2024


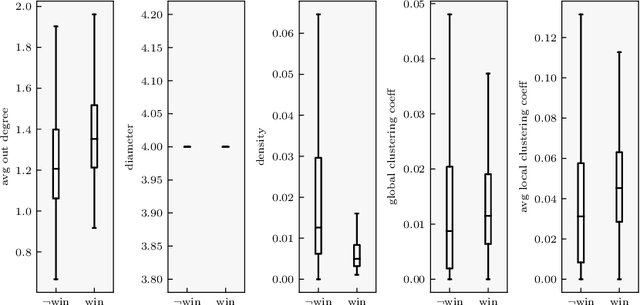
In recent years, many studies have been focusing on predicting the scientific impact of research papers. Most of these predictions are based on citations count or rely on features obtainable only from already published papers. In this study, we predict the likelihood for a research paper of winning an award only relying on information available at publication time. For each paper, we build the citation subgraph induced from its bibliography. We initially consider some features of this subgraph, such as the density and the global clustering coefficient, to make our prediction. Then, we mix this information with textual features, extracted from the abstract and the title, to obtain a more accurate final prediction. We made our experiments considering the ArnetMiner citation graph, while the ground truth on award-winning papers has been obtained from a collection of best paper awards from 32 computer science conferences. In our experiment, we obtained an encouraging F1 score of 0.694. Remarkably, The high recall and the low false negatives rate, show how the model performs very well at identifying papers that will not win an award. This behavior can help researchers in getting a first evaluation of their work at publication time. Lastly, we made some first experiments on interpretability. Our results highlight some interesting patterns both in topological and textual features.
Application of federated learning techniques for arrhythmia classification using 12-lead ECG signals
Aug 23, 2022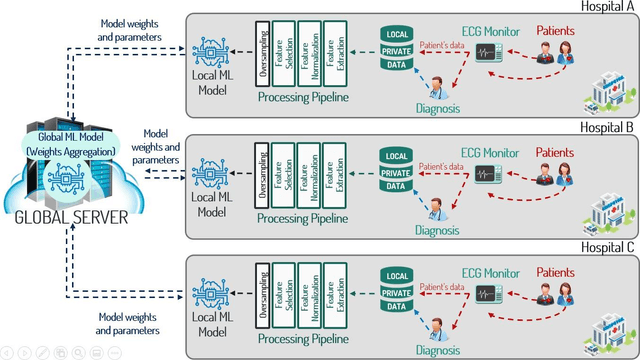
Background: AI-based analysis of sufficiently large, curated medical datasets has been shown to be promising for providing early detection, faster diagnosis, better decision-making, and more effective treatment. However, accessing such highly confidential and very sensitive medical data, obtained from a variety of sources, is usually highly restricted since improper use, unsafe storage, data leakage or abuse could violate a person's privacy. In this work we apply a federated learning paradigm over a heterogeneous, siloed sets of high-definition electrocardiogram arriving from 12-leads ECG sensors arrays to train AI models. We evaluated the capacity of the resulting models to achieve equivalent performance when compared to state-of-the-art models trained when the same data is collected in a central place. Methods: We propose a privacy preserving methodology for training AI models based on the federated learning paradigm over a heterogeneous, distributed, dataset. The methodology is applied to a broad range of machine learning techniques based on gradient boosting, convolutional neural network and recurrent neural networks with long short-term memory. The models were trained over a ECG dataset containing 12-leads recordings collected from 43,059 patients from six geographically separate and heterogeneous sources. Findings: The resulting set of AI models for detecting cardiovascular abnormalities achieved comparable predictive performances against models trained using a centralised learning approach. Interpretation: The approach of compute parameters contributing to the global model locally and then exchange only such parameters instead of the whole sensitive data as in ML contributes to preserve medical data privacy.
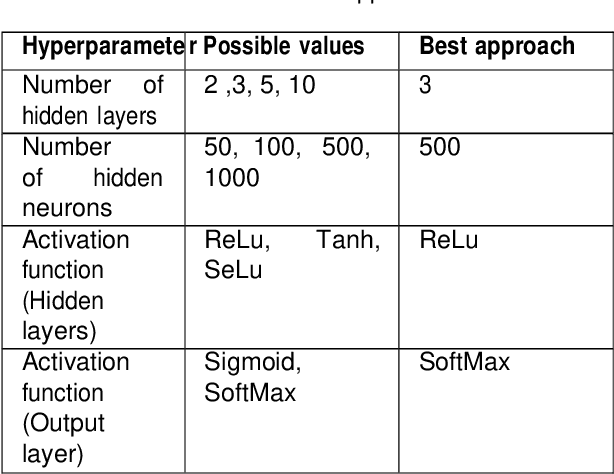
Comparison of Decision Tree Based Classification Strategies to Detect External Chemical Stimuli from Raw and Filtered Plant Electrical Response
May 13, 2017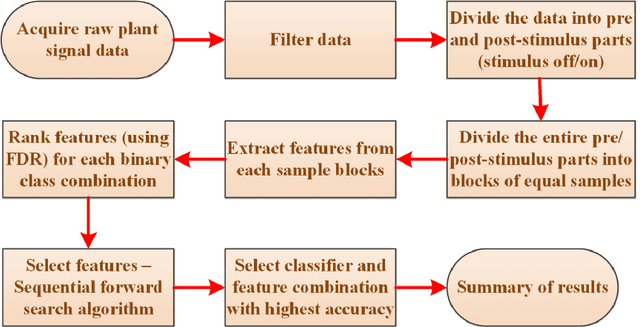
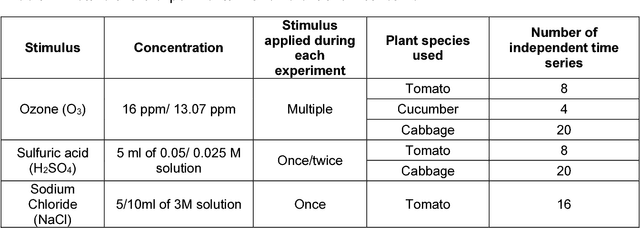
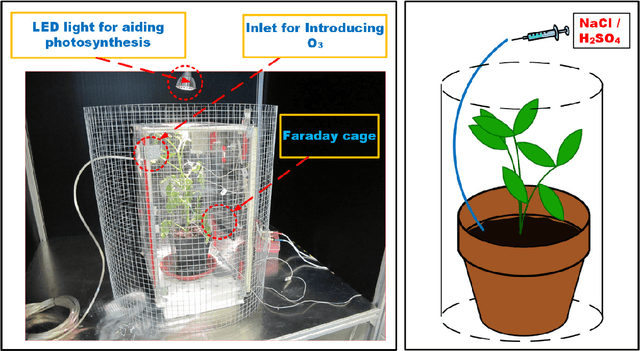

Plants monitor their surrounding environment and control their physiological functions by producing an electrical response. We recorded electrical signals from different plants by exposing them to Sodium Chloride (NaCl), Ozone (O3) and Sulfuric Acid (H2SO4) under laboratory conditions. After applying pre-processing techniques such as filtering and drift removal, we extracted few statistical features from the acquired plant electrical signals. Using these features, combined with different classification algorithms, we used a decision tree based multi-class classification strategy to identify the three different external chemical stimuli. We here present our exploration to obtain the optimum set of ranked feature and classifier combination that can separate a particular chemical stimulus from the incoming stream of plant electrical signals. The paper also reports an exhaustive comparison of similar feature based classification using the filtered and the raw plant signals, containing the high frequency stochastic part and also the low frequency trends present in it, as two different cases for feature extraction. The work, presented in this paper opens up new possibilities for using plant electrical signals to monitor and detect other environmental stimuli apart from NaCl, O3 and H2SO4 in future.
Exploring Strategies for Classification of External Stimuli Using Statistical Features of the Plant Electrical Response
Nov 29, 2016
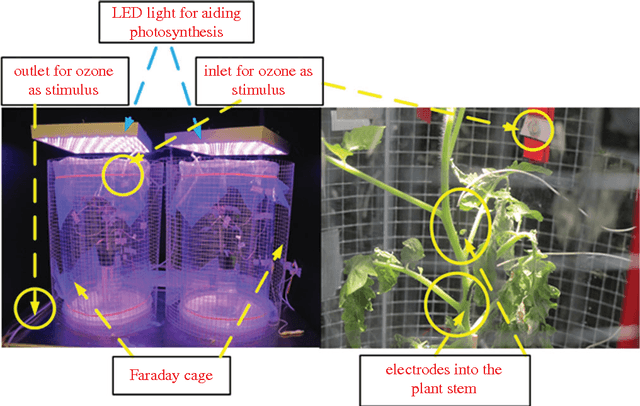
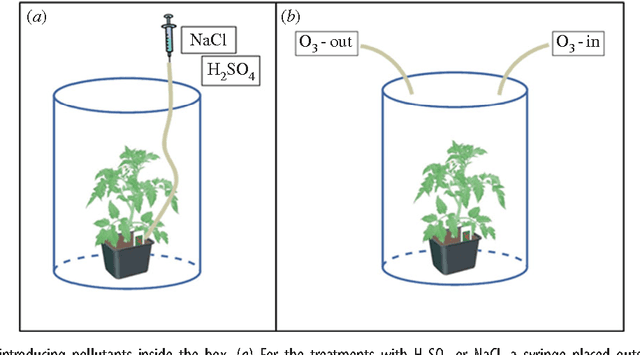
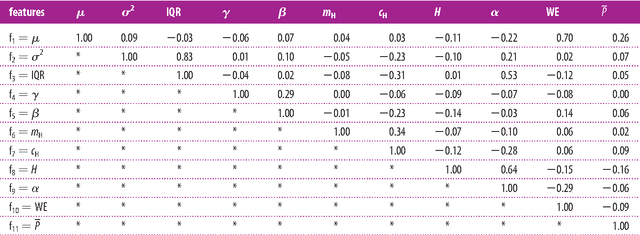
Plants sense their environment by producing electrical signals which in essence represent changes in underlying physiological processes. These electrical signals, when monitored, show both stochastic and deterministic dynamics. In this paper, we compute 11 statistical features from the raw non-stationary plant electrical signal time series to classify the stimulus applied (causing the electrical signal). By using different discriminant analysis based classification techniques, we successfully establish that there is enough information in the raw electrical signal to classify the stimuli. In the process, we also propose two standard features which consistently give good classification results for three types of stimuli - Sodium Chloride (NaCl), Sulphuric Acid (H2SO4) and Ozone (O3). This may facilitate reduction in the complexity involved in computing all the features for online classification of similar external stimuli in future.
* 22 pages, 7 figures, 9 tables