 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClust-PSI-PFL: A Population Stability Index Approach for Clustered Non-IID Personalized Federated Learning
Dec 23, 2025Federated learning (FL) supports privacy-preserving, decentralized machine learning (ML) model training by keeping data on client devices. However, non-independent and identically distributed (non-IID) data across clients biases updates and degrades performance. To alleviate these issues, we propose Clust-PSI-PFL, a clustering-based personalized FL framework that uses the Population Stability Index (PSI) to quantify the level of non-IID data. We compute a weighted PSI metric, $WPSI^L$, which we show to be more informative than common non-IID metrics (Hellinger, Jensen-Shannon, and Earth Mover's distance). Using PSI features, we form distributionally homogeneous groups of clients via K-means++; the number of optimal clusters is chosen by a systematic silhouette-based procedure, typically yielding few clusters with modest overhead. Across six datasets (tabular, image, and text modalities), two partition protocols (Dirichlet with parameter $α$ and Similarity with parameter S), and multiple client sizes, Clust-PSI-PFL delivers up to 18% higher global accuracy than state-of-the-art baselines and markedly improves client fairness by a relative improvement of 37% under severe non-IID data. These results establish PSI-guided clustering as a principled, lightweight mechanism for robust PFL under label skew.
VitaGraph: Building a Knowledge Graph for Biologically Relevant Learning Tasks
May 16, 2025The intrinsic complexity of human biology presents ongoing challenges to scientific understanding. Researchers collaborate across disciplines to expand our knowledge of the biological interactions that define human life. AI methodologies have emerged as powerful tools across scientific domains, particularly in computational biology, where graph data structures effectively model biological entities such as protein-protein interaction (PPI) networks and gene functional networks. Those networks are used as datasets for paramount network medicine tasks, such as gene-disease association prediction, drug repurposing, and polypharmacy side effect studies. Reliable predictions from machine learning models require high-quality foundational data. In this work, we present a comprehensive multi-purpose biological knowledge graph constructed by integrating and refining multiple publicly available datasets. Building upon the Drug Repurposing Knowledge Graph (DRKG), we define a pipeline tasked with a) cleaning inconsistencies and redundancies present in DRKG, b) coalescing information from the main available public data sources, and c) enriching the graph nodes with expressive feature vectors such as molecular fingerprints and gene ontologies. Biologically and chemically relevant features improve the capacity of machine learning models to generate accurate and well-structured embedding spaces. The resulting resource represents a coherent and reliable biological knowledge graph that serves as a state-of-the-art platform to advance research in computational biology and precision medicine. Moreover, it offers the opportunity to benchmark graph-based machine learning and network medicine models on relevant tasks. We demonstrate the effectiveness of the proposed dataset by benchmarking it against the task of drug repurposing, PPI prediction, and side-effect prediction, modeled as link prediction problems.
Non-IID data in Federated Learning: A Systematic Review with Taxonomy, Metrics, Methods, Frameworks and Future Directions
Nov 19, 2024Recent advances in machine learning have highlighted Federated Learning (FL) as a promising approach that enables multiple distributed users (so-called clients) to collectively train ML models without sharing their private data. While this privacy-preserving method shows potential, it struggles when data across clients is not independent and identically distributed (non-IID) data. The latter remains an unsolved challenge that can result in poorer model performance and slower training times. Despite the significance of non-IID data in FL, there is a lack of consensus among researchers about its classification and quantification. This systematic review aims to fill that gap by providing a detailed taxonomy for non-IID data, partition protocols, and metrics to quantify data heterogeneity. Additionally, we describe popular solutions to address non-IID data and standardized frameworks employed in FL with heterogeneous data. Based on our state-of-the-art review, we present key lessons learned and suggest promising future research directions.
Kolmogorov-Arnold Graph Neural Networks
Jun 26, 2024Graph neural networks (GNNs) excel in learning from network-like data but often lack interpretability, making their application challenging in domains requiring transparent decision-making. We propose the Graph Kolmogorov-Arnold Network (GKAN), a novel GNN model leveraging spline-based activation functions on edges to enhance both accuracy and interpretability. Our experiments on five benchmark datasets demonstrate that GKAN outperforms state-of-the-art GNN models in node classification, link prediction, and graph classification tasks. In addition to the improved accuracy, GKAN's design inherently provides clear insights into the model's decision-making process, eliminating the need for post-hoc explainability techniques. This paper discusses the methodology, performance, and interpretability of GKAN, highlighting its potential for applications in domains where interpretability is crucial.
Learning Double-Compression Video Fingerprints Left from Social-Media Platforms
Dec 07, 2022



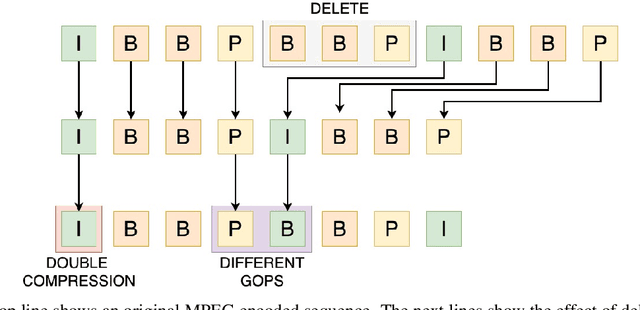
Social media and messaging apps have become major communication platforms. Multimedia contents promote improved user engagement and have thus become a very important communication tool. However, fake news and manipulated content can easily go viral, so, being able to verify the source of videos and images as well as to distinguish between native and downloaded content becomes essential. Most of the work performed so far on social media provenance has concentrated on images; in this paper, we propose a CNN architecture that analyzes video content to trace videos back to their social network of origin. The experiments demonstrate that stating platform provenance is possible for videos as well as images with very good accuracy.
AI-based Data Preparation and Data Analytics in Healthcare: The Case of Diabetes
Jun 13, 2022
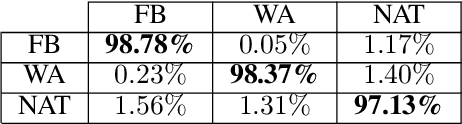
The Associazione Medici Diabetologi (AMD) collects and manages one of the largest worldwide-available collections of diabetic patient records, also known as the AMD database. This paper presents the initial results of an ongoing project whose focus is the application of Artificial Intelligence and Machine Learning techniques for conceptualizing, cleaning, and analyzing such an important and valuable dataset, with the goal of providing predictive insights to better support diabetologists in their diagnostic and therapeutic choices.
Identification of Social-Media Platform of Videos through the Use of Shared Features
Sep 08, 2021
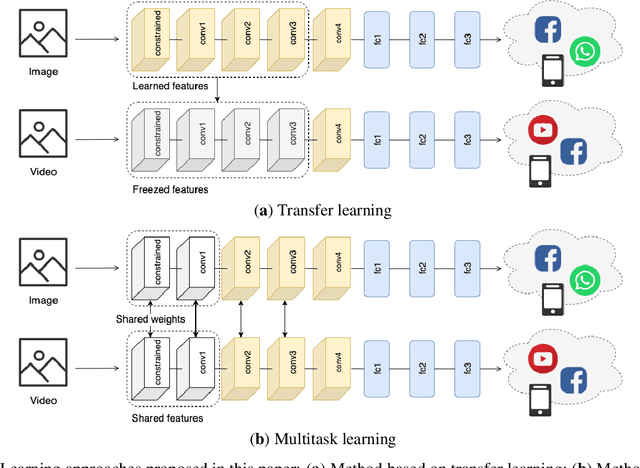
Videos have become a powerful tool for spreading illegal content such as military propaganda, revenge porn, or bullying through social networks. To counter these illegal activities, it has become essential to try new methods to verify the origin of videos from these platforms. However, collecting datasets large enough to train neural networks for this task has become difficult because of the privacy regulations that have been enacted in recent years. To mitigate this limitation, in this work we propose two different solutions based on transfer learning and multitask learning to determine whether a video has been uploaded from or downloaded to a specific social platform through the use of shared features with images trained on the same task. By transferring features from the shallowest to the deepest levels of the network from the image task to videos, we measure the amount of information shared between these two tasks. Then, we introduce a model based on multitask learning, which learns from both tasks simultaneously. The promising experimental results show, in particular, the effectiveness of the multitask approach. According to our knowledge, this is the first work that addresses the problem of social media platform identification of videos through the use of shared features.
Firms Default Prediction with Machine Learning
Feb 17, 2020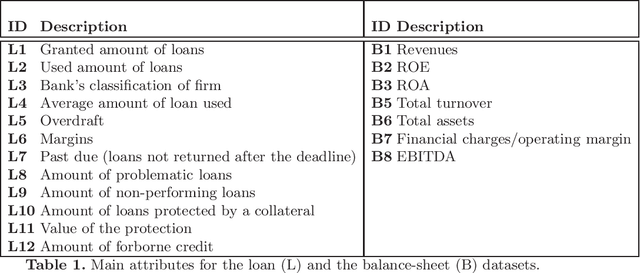

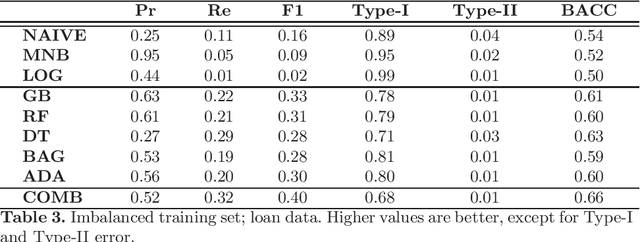

Academics and practitioners have studied over the years models for predicting firms bankruptcy, using statistical and machine-learning approaches. An earlier sign that a company has financial difficulties and may eventually bankrupt is going in \emph{default}, which, loosely speaking means that the company has been having difficulties in repaying its loans towards the banking system. Firms default status is not technically a failure but is very relevant for bank lending policies and often anticipates the failure of the company. Our study uses, for the first time according to our knowledge, a very large database of granular credit data from the Italian Central Credit Register of Bank of Italy that contain information on all Italian companies' past behavior towards the entire Italian banking system to predict their default using machine-learning techniques. Furthermore, we combine these data with other information regarding companies' public balance sheet data. We find that ensemble techniques and random forest provide the best results, corroborating the findings of Barboza et al. (Expert Syst. Appl., 2017).
Algorithms for Hiring and Outsourcing in the Online Labor Market
Feb 16, 2020
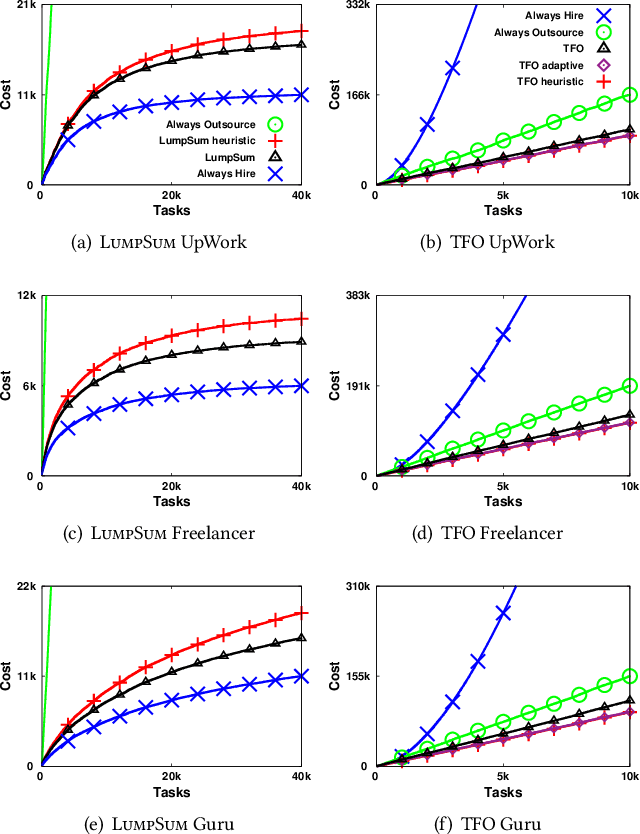
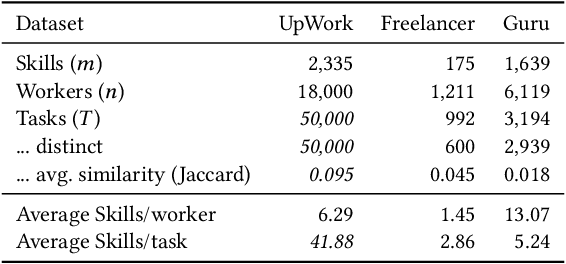
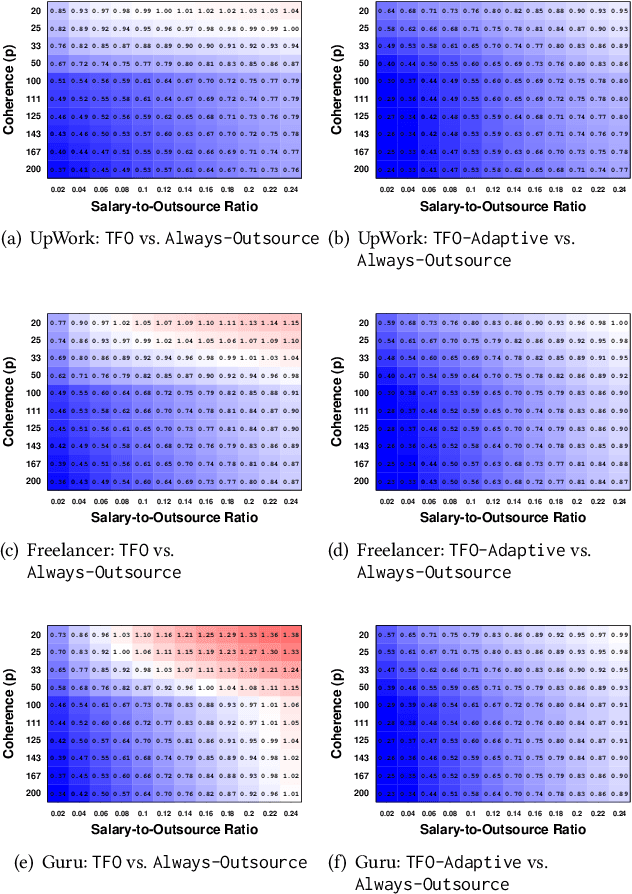
Although freelancing work has grown substantially in recent years, in part facilitated by a number of online labor marketplaces, (e.g., Guru, Freelancer, Amazon Mechanical Turk), traditional forms of "in-sourcing" work continue being the dominant form of employment. This means that, at least for the time being, freelancing and salaried employment will continue to co-exist. In this paper, we provide algorithms for outsourcing and hiring workers in a general setting, where workers form a team and contribute different skills to perform a task. We call this model team formation with outsourcing. In our model, tasks arrive in an online fashion: neither the number nor the composition of the tasks is known a-priori. At any point in time, there is a team of hired workers who receive a fixed salary independently of the work they perform. This team is dynamic: new members can be hired and existing members can be fired, at some cost. Additionally, some parts of the arriving tasks can be outsourced and thus completed by non-team members, at a premium. Our contribution is an efficient online cost-minimizing algorithm for hiring and firing team members and outsourcing tasks. We present theoretical bounds obtained using a primal-dual scheme proving that our algorithms have a logarithmic competitive approximation ratio. We complement these results with experiments using semi-synthetic datasets based on actual task requirements and worker skills from three large online labor marketplaces.
On Mining IoT Data for Evaluating the Operation of Public Educational Buildings
Jun 20, 2019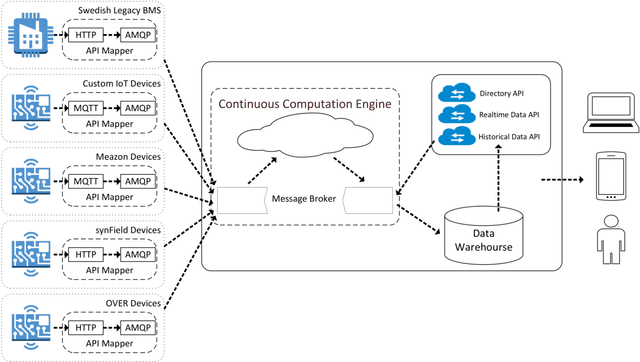
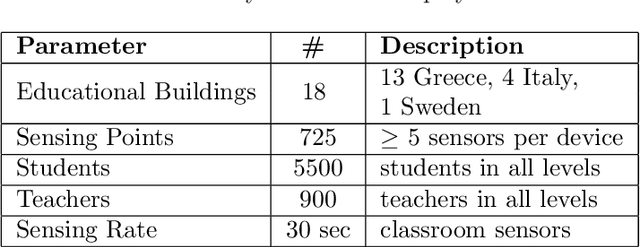
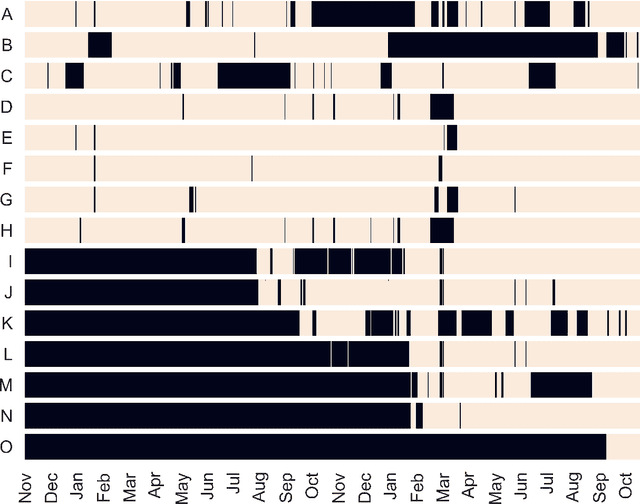
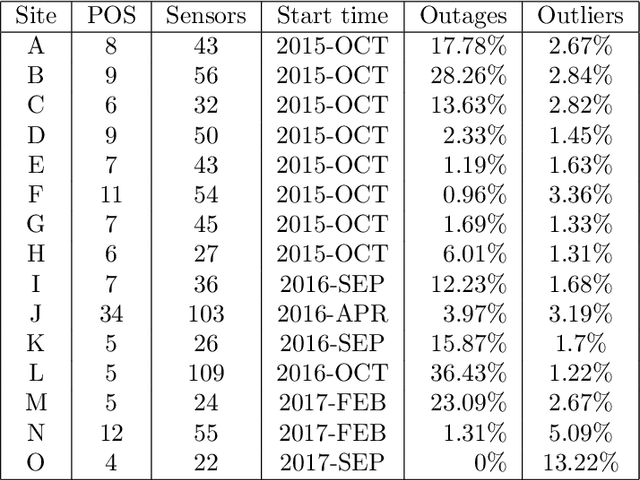
Public educational systems operate thousands of buildings with vastly different characteristics in terms of size, age, location, construction, thermal behavior and user communities. Their strategic planning and sustainable operation is an extremely complex and requires quantitative evidence on the performance of buildings such as the interaction of indoor-outdoor environment. Internet of Things (IoT) deployments can provide the necessary data to evaluate, redesign and eventually improve the organizational and managerial measures. In this work a data mining approach is presented to analyze the sensor data collected over a period of 2 years from an IoT infrastructure deployed over 18 school buildings spread in Greece, Italy and Sweden. The real-world evaluation indicates that data mining on sensor data can provide critical insights to building managers and custodial staff about ways to lower a building's energy footprint through effectively managing building operations.