 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-SASLM: Zero-Shot Style-Aligned SLI Blending Latent Manipulation
Mar 29, 2025
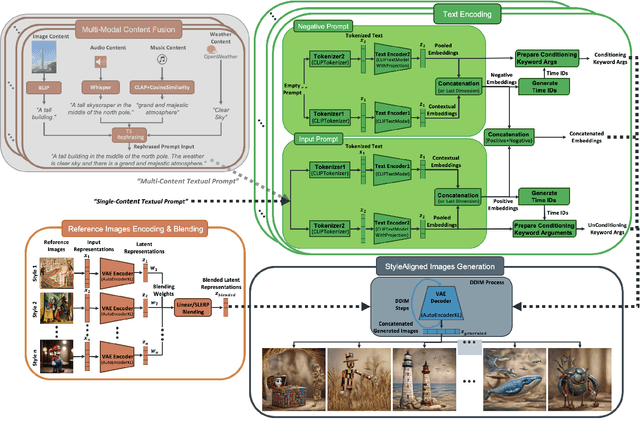


We introduce Z-SASLM, a Zero-Shot Style-Aligned SLI (Spherical Linear Interpolation) Blending Latent Manipulation pipeline that overcomes the limitations of current multi-style blending methods. Conventional approaches rely on linear blending, assuming a flat latent space leading to suboptimal results when integrating multiple reference styles. In contrast, our framework leverages the non-linear geometry of the latent space by using SLI Blending to combine weighted style representations. By interpolating along the geodesic on the hypersphere, Z-SASLM preserves the intrinsic structure of the latent space, ensuring high-fidelity and coherent blending of diverse styles - all without the need for fine-tuning. We further propose a new metric, Weighted Multi-Style DINO ViT-B/8, designed to quantitatively evaluate the consistency of the blended styles. While our primary focus is on the theoretical and practical advantages of SLI Blending for style manipulation, we also demonstrate its effectiveness in a multi-modal content fusion setting through comprehensive experimental studies. Experimental results show that Z-SASLM achieves enhanced and robust style alignment. The implementation code can be found at: https://github.com/alessioborgi/Z-SASLM.
Enhancing Ground-to-Aerial Image Matching for Visual Misinformation Detection Using Semantic Segmentation
Feb 10, 2025



The recent advancements in generative AI techniques, which have significantly increased the online dissemination of altered images and videos, have raised serious concerns about the credibility of digital media available on the Internet and distributed through information channels and social networks. This issue particularly affects domains that rely heavily on trustworthy data, such as journalism, forensic analysis, and Earth observation. To address these concerns, the ability to geolocate a non-geo-tagged ground-view image without external information, such as GPS coordinates, has become increasingly critical. This study tackles the challenge of linking a ground-view image, potentially exhibiting varying fields of view (FoV), to its corresponding satellite image without the aid of GPS data. To achieve this, we propose a novel four-stream Siamese-like architecture, the Quadruple Semantic Align Net (SAN-QUAD), which extends previous state-of-the-art (SOTA) approaches by leveraging semantic segmentation applied to both ground and satellite imagery. Experimental results on a subset of the CVUSA dataset demonstrate significant improvements of up to 9.8\% over prior methods across various FoV settings.
Continuous fake media detection: adapting deepfake detectors to new generative techniques
Jun 12, 2024Generative techniques continue to evolve at an impressively high rate, driven by the hype about these technologies. This rapid advancement severely limits the application of deepfake detectors, which, despite numerous efforts by the scientific community, struggle to achieve sufficiently robust performance against the ever-changing content. To address these limitations, in this paper, we propose an analysis of two continuous learning techniques on a Short and a Long sequence of fake media. Both sequences include a complex and heterogeneous range of deepfakes generated from GANs, computer graphics techniques, and unknown sources. Our study shows that continual learning could be important in mitigating the need for generalizability. In fact, we show that, although with some limitations, continual learning methods help to maintain good performance across the entire training sequence. For these techniques to work in a sufficiently robust way, however, it is necessary that the tasks in the sequence share similarities. In fact, according to our experiments, the order and similarity of the tasks can affect the performance of the models over time. To address this problem, we show that it is possible to group tasks based on their similarity. This small measure allows for a significant improvement even in longer sequences. This result suggests that continual techniques can be combined with the most promising detection methods, allowing them to catch up with the latest generative techniques. In addition to this, we propose an overview of how this learning approach can be integrated into a deepfake detection pipeline for continuous integration and continuous deployment (CI/CD). This allows you to keep track of different funds, such as social networks, new generative tools, or third-party datasets, and through the integration of continuous learning, allows constant maintenance of the detectors.
Learning from Unlabelled Data with Transformers: Domain Adaptation for Semantic Segmentation of High Resolution Aerial Images
Apr 17, 2024



Data from satellites or aerial vehicles are most of the times unlabelled. Annotating such data accurately is difficult, requires expertise, and is costly in terms of time. Even if Earth Observation (EO) data were correctly labelled, labels might change over time. Learning from unlabelled data within a semi-supervised learning framework for segmentation of aerial images is challenging. In this paper, we develop a new model for semantic segmentation of unlabelled images, the Non-annotated Earth Observation Semantic Segmentation (NEOS) model. NEOS performs domain adaptation as the target domain does not have ground truth semantic segmentation masks. The distribution inconsistencies between the target and source domains are due to differences in acquisition scenes, environment conditions, sensors, and times. Our model aligns the learned representations of the different domains to make them coincide. The evaluation results show that NEOS is successful and outperforms other models for semantic segmentation of unlabelled data.
A Semantic Segmentation-guided Approach for Ground-to-Aerial Image Matching
Apr 17, 2024



Nowadays the accurate geo-localization of ground-view images has an important role across domains as diverse as journalism, forensics analysis, transports, and Earth Observation. This work addresses the problem of matching a query ground-view image with the corresponding satellite image without GPS data. This is done by comparing the features from a ground-view image and a satellite one, innovatively leveraging the corresponding latter's segmentation mask through a three-stream Siamese-like network. The proposed method, Semantic Align Net (SAN), focuses on limited Field-of-View (FoV) and ground panorama images (images with a FoV of 360{\deg}). The novelty lies in the fusion of satellite images in combination with their semantic segmentation masks, aimed at ensuring that the model can extract useful features and focus on the significant parts of the images. This work shows how SAN through semantic analysis of images improves the performance on the unlabelled CVUSA dataset for all the tested FoVs.
Adversarial Data Poisoning for Fake News Detection: How to Make a Model Misclassify a Target News without Modifying It
Jan 04, 2024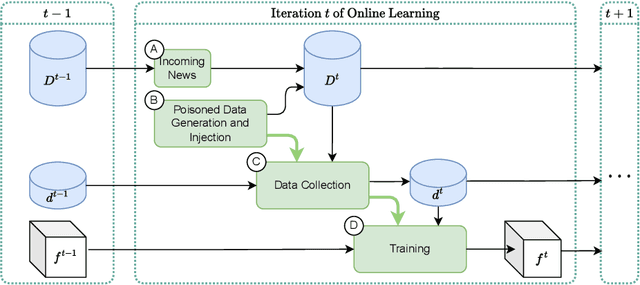
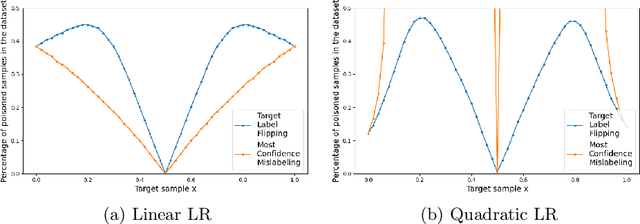
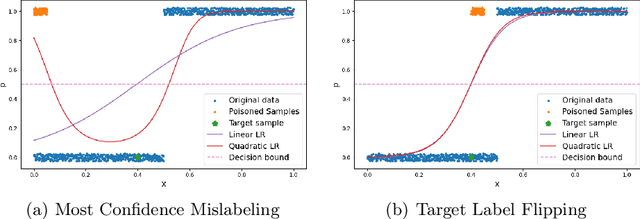
Fake news detection models are critical to countering disinformation but can be manipulated through adversarial attacks. In this position paper, we analyze how an attacker can compromise the performance of an online learning detector on specific news content without being able to manipulate the original target news. In some contexts, such as social networks, where the attacker cannot exert complete control over all the information, this scenario can indeed be quite plausible. Therefore, we show how an attacker could potentially introduce poisoning data into the training data to manipulate the behavior of an online learning method. Our initial findings reveal varying susceptibility of logistic regression models based on complexity and attack type.
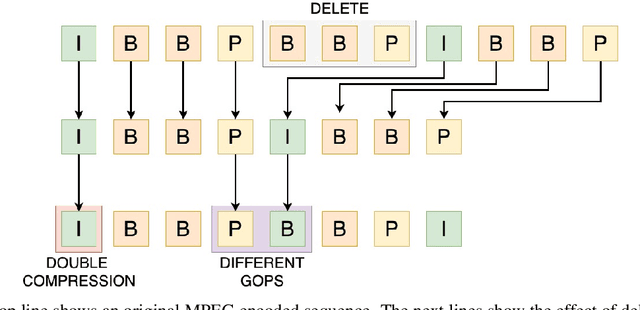
Learning Double-Compression Video Fingerprints Left from Social-Media Platforms
Dec 07, 2022



Social media and messaging apps have become major communication platforms. Multimedia contents promote improved user engagement and have thus become a very important communication tool. However, fake news and manipulated content can easily go viral, so, being able to verify the source of videos and images as well as to distinguish between native and downloaded content becomes essential. Most of the work performed so far on social media provenance has concentrated on images; in this paper, we propose a CNN architecture that analyzes video content to trace videos back to their social network of origin. The experiments demonstrate that stating platform provenance is possible for videos as well as images with very good accuracy.
DepthFake: a depth-based strategy for detecting Deepfake videos
Aug 23, 2022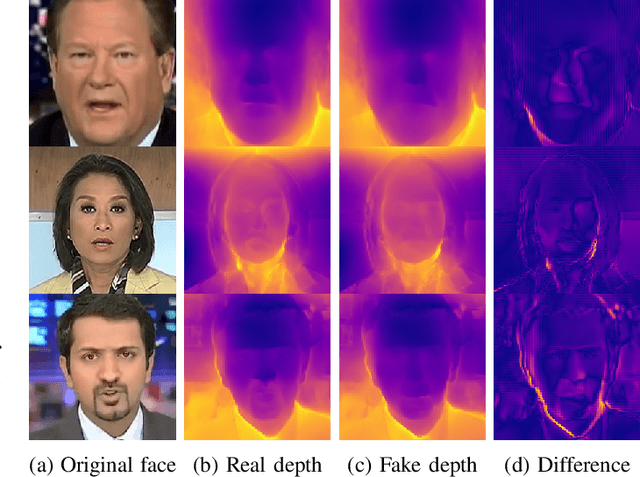
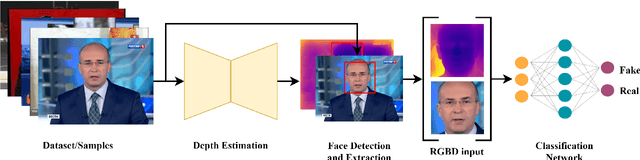
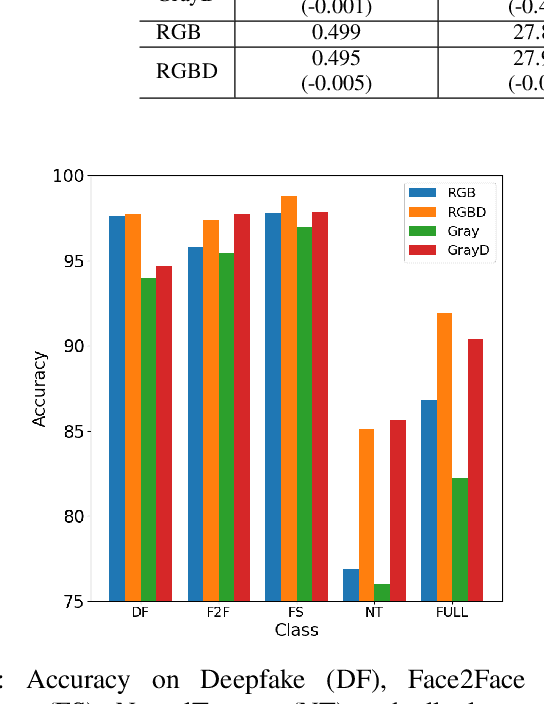
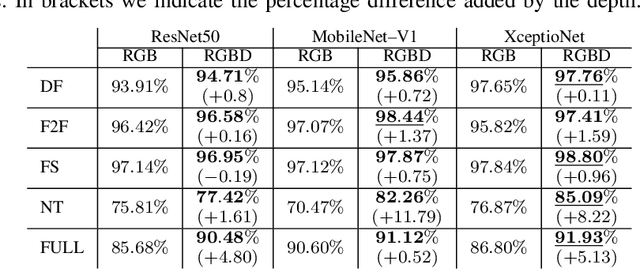
Fake content has grown at an incredible rate over the past few years. The spread of social media and online platforms makes their dissemination on a large scale increasingly accessible by malicious actors. In parallel, due to the growing diffusion of fake image generation methods, many Deep Learning-based detection techniques have been proposed. Most of those methods rely on extracting salient features from RGB images to detect through a binary classifier if the image is fake or real. In this paper, we proposed DepthFake, a study on how to improve classical RGB-based approaches with depth-maps. The depth information is extracted from RGB images with recent monocular depth estimation techniques. Here, we demonstrate the effective contribution of depth-maps to the deepfake detection task on robust pre-trained architectures. The proposed RGBD approach is in fact able to achieve an average improvement of 3.20% and up to 11.7% for some deepfake attacks with respect to standard RGB architectures over the FaceForensic++ dataset.
Identification of Social-Media Platform of Videos through the Use of Shared Features
Sep 08, 2021
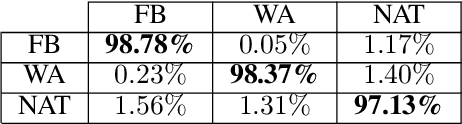
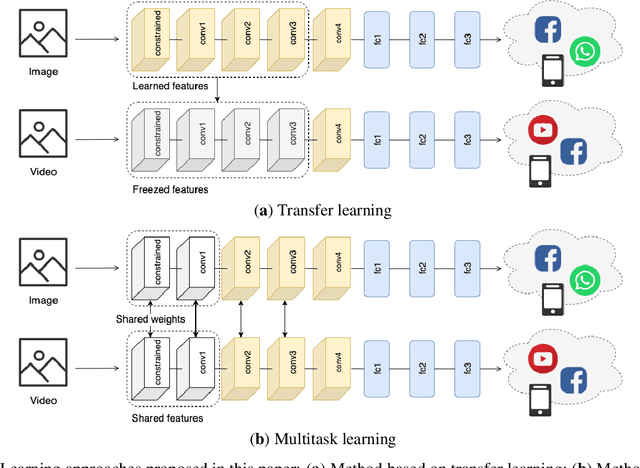
Videos have become a powerful tool for spreading illegal content such as military propaganda, revenge porn, or bullying through social networks. To counter these illegal activities, it has become essential to try new methods to verify the origin of videos from these platforms. However, collecting datasets large enough to train neural networks for this task has become difficult because of the privacy regulations that have been enacted in recent years. To mitigate this limitation, in this work we propose two different solutions based on transfer learning and multitask learning to determine whether a video has been uploaded from or downloaded to a specific social platform through the use of shared features with images trained on the same task. By transferring features from the shallowest to the deepest levels of the network from the image task to videos, we measure the amount of information shared between these two tasks. Then, we introduce a model based on multitask learning, which learns from both tasks simultaneously. The promising experimental results show, in particular, the effectiveness of the multitask approach. According to our knowledge, this is the first work that addresses the problem of social media platform identification of videos through the use of shared features.