 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic detection of Gen-AI texts: A comparative framework of neural models
Mar 19, 2026The rapid proliferation of Large Language Models has significantly increased the difficulty of distinguishing between human-written and AI generated texts, raising critical issues across academic, editorial, and social domains. This paper investigates the problem of AI generated text detection through the design, implementation, and comparative evaluation of multiple machine learning based detectors. Four neural architectures are developed and analyzed: a Multilayer Perceptron, a one-dimensional Convolutional Neural Network, a MobileNet-based CNN, and a Transformer model. The proposed models are benchmarked against widely used online detectors, including ZeroGPT, GPTZero, QuillBot, Originality.AI, Sapling, IsGen, Rephrase, and Writer. Experiments are conducted on the COLING Multilingual Dataset, considering both English and Italian configurations, as well as on an original thematic dataset focused on Art and Mental Health. Results show that supervised detectors achieve more stable and robust performance than commercial tools across different languages and domains, highlighting key strengths and limitations of current detection strategies.
LADLE-MM: Limited Annotation based Detector with Learned Ensembles for Multimodal Misinformation
Dec 23, 2025With the rise of easily accessible tools for generating and manipulating multimedia content, realistic synthetic alterations to digital media have become a widespread threat, often involving manipulations across multiple modalities simultaneously. Recently, such techniques have been increasingly employed to distort narratives of important events and to spread misinformation on social media, prompting the development of misinformation detectors. In the context of misinformation conveyed through image-text pairs, several detection methods have been proposed. However, these approaches typically rely on computationally intensive architectures or require large amounts of annotated data. In this work we introduce LADLE-MM: Limited Annotation based Detector with Learned Ensembles for Multimodal Misinformation, a model-soup initialized multimodal misinformation detector designed to operate under a limited annotation setup and constrained training resources. LADLE-MM is composed of two unimodal branches and a third multimodal one that enhances image and text representations with additional multimodal embeddings extracted from BLIP, serving as fixed reference space. Despite using 60.3% fewer trainable parameters than previous state-of-the-art models, LADLE-MM achieves competitive performance on both binary and multi-label classification tasks on the DGM4 benchmark, outperforming existing methods when trained without grounding annotations. Moreover, when evaluated on the VERITE dataset, LADLE-MM outperforms current state-of-the-art approaches that utilize more complex architectures involving Large Vision-Language-Models, demonstrating the effective generalization ability in an open-set setting and strong robustness to unimodal bias.
R3ST: A Synthetic 3D Dataset With Realistic Trajectories
Dec 18, 2025Datasets are essential to train and evaluate computer vision models used for traffic analysis and to enhance road safety. Existing real datasets fit real-world scenarios, capturing authentic road object behaviors, however, they typically lack precise ground-truth annotations. In contrast, synthetic datasets play a crucial role, allowing for the annotation of a large number of frames without additional costs or extra time. However, a general drawback of synthetic datasets is the lack of realistic vehicle motion, since trajectories are generated using AI models or rule-based systems. In this work, we introduce R3ST (Realistic 3D Synthetic Trajectories), a synthetic dataset that overcomes this limitation by generating a synthetic 3D environment and integrating real-world trajectories derived from SinD, a bird's-eye-view dataset recorded from drone footage. The proposed dataset closes the gap between synthetic data and realistic trajectories, advancing the research in trajectory forecasting of road vehicles, offering both accurate multimodal ground-truth annotations and authentic human-driven vehicle trajectories.
Shedding Light on Depth: Explainability Assessment in Monocular Depth Estimation
Sep 19, 2025
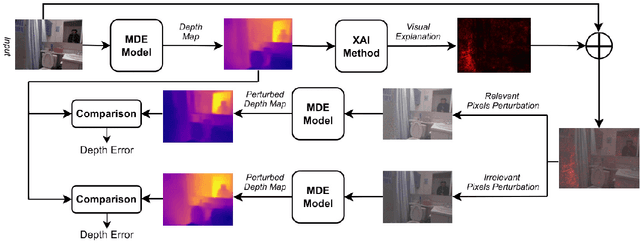

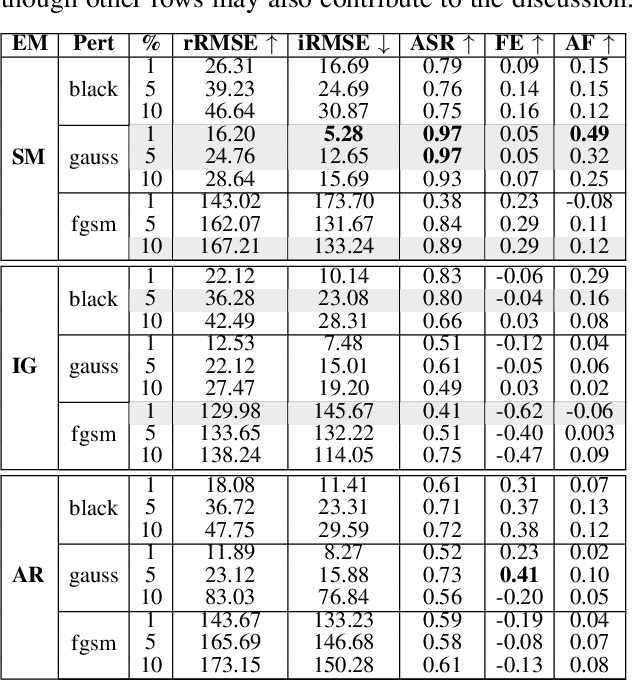
Explainable artificial intelligence is increasingly employed to understand the decision-making process of deep learning models and create trustworthiness in their adoption. However, the explainability of Monocular Depth Estimation (MDE) remains largely unexplored despite its wide deployment in real-world applications. In this work, we study how to analyze MDE networks to map the input image to the predicted depth map. More in detail, we investigate well-established feature attribution methods, Saliency Maps, Integrated Gradients, and Attention Rollout on different computationally complex models for MDE: METER, a lightweight network, and PixelFormer, a deep network. We assess the quality of the generated visual explanations by selectively perturbing the most relevant and irrelevant pixels, as identified by the explainability methods, and analyzing the impact of these perturbations on the model's output. Moreover, since existing evaluation metrics can have some limitations in measuring the validity of visual explanations for MDE, we additionally introduce the Attribution Fidelity. This metric evaluates the reliability of the feature attribution by assessing their consistency with the predicted depth map. Experimental results demonstrate that Saliency Maps and Integrated Gradients have good performance in highlighting the most important input features for MDE lightweight and deep models, respectively. Furthermore, we show that Attribution Fidelity effectively identifies whether an explainability method fails to produce reliable visual maps, even in scenarios where conventional metrics might suggest satisfactory results.
WILD: a new in-the-Wild Image Linkage Dataset for synthetic image attribution
Apr 29, 2025Synthetic image source attribution is an open challenge, with an increasing number of image generators being released yearly. The complexity and the sheer number of available generative techniques, as well as the scarcity of high-quality open source datasets of diverse nature for this task, make training and benchmarking synthetic image source attribution models very challenging. WILD is a new in-the-Wild Image Linkage Dataset designed to provide a powerful training and benchmarking tool for synthetic image attribution models. The dataset is built out of a closed set of 10 popular commercial generators, which constitutes the training base of attribution models, and an open set of 10 additional generators, simulating a real-world in-the-wild scenario. Each generator is represented by 1,000 images, for a total of 10,000 images in the closed set and 10,000 images in the open set. Half of the images are post-processed with a wide range of operators. WILD allows benchmarking attribution models in a wide range of tasks, including closed and open set identification and verification, and robust attribution with respect to post-processing and adversarial attacks. Models trained on WILD are expected to benefit from the challenging scenario represented by the dataset itself. Moreover, an assessment of seven baseline methodologies on closed and open set attribution is presented, including robustness tests with respect to post-processing.
Z-SASLM: Zero-Shot Style-Aligned SLI Blending Latent Manipulation
Mar 29, 2025
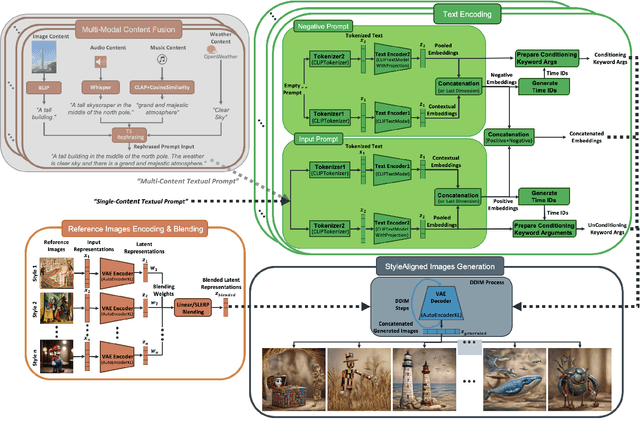


We introduce Z-SASLM, a Zero-Shot Style-Aligned SLI (Spherical Linear Interpolation) Blending Latent Manipulation pipeline that overcomes the limitations of current multi-style blending methods. Conventional approaches rely on linear blending, assuming a flat latent space leading to suboptimal results when integrating multiple reference styles. In contrast, our framework leverages the non-linear geometry of the latent space by using SLI Blending to combine weighted style representations. By interpolating along the geodesic on the hypersphere, Z-SASLM preserves the intrinsic structure of the latent space, ensuring high-fidelity and coherent blending of diverse styles - all without the need for fine-tuning. We further propose a new metric, Weighted Multi-Style DINO ViT-B/8, designed to quantitatively evaluate the consistency of the blended styles. While our primary focus is on the theoretical and practical advantages of SLI Blending for style manipulation, we also demonstrate its effectiveness in a multi-modal content fusion setting through comprehensive experimental studies. Experimental results show that Z-SASLM achieves enhanced and robust style alignment. The implementation code can be found at: https://github.com/alessioborgi/Z-SASLM.
Enhancing Ground-to-Aerial Image Matching for Visual Misinformation Detection Using Semantic Segmentation
Feb 10, 2025



The recent advancements in generative AI techniques, which have significantly increased the online dissemination of altered images and videos, have raised serious concerns about the credibility of digital media available on the Internet and distributed through information channels and social networks. This issue particularly affects domains that rely heavily on trustworthy data, such as journalism, forensic analysis, and Earth observation. To address these concerns, the ability to geolocate a non-geo-tagged ground-view image without external information, such as GPS coordinates, has become increasingly critical. This study tackles the challenge of linking a ground-view image, potentially exhibiting varying fields of view (FoV), to its corresponding satellite image without the aid of GPS data. To achieve this, we propose a novel four-stream Siamese-like architecture, the Quadruple Semantic Align Net (SAN-QUAD), which extends previous state-of-the-art (SOTA) approaches by leveraging semantic segmentation applied to both ground and satellite imagery. Experimental results on a subset of the CVUSA dataset demonstrate significant improvements of up to 9.8\% over prior methods across various FoV settings.
Beyond adaptive gradient: Fast-Controlled Minibatch Algorithm for large-scale optimization
Nov 24, 2024

Adaptive gradient methods have been increasingly adopted by deep learning community due to their fast convergence and reduced sensitivity to hyper-parameters. However, these methods come with limitations, such as increased memory requirements for elements like moving averages and a poorly understood convergence theory. To overcome these challenges, we introduce F-CMA, a Fast-Controlled Mini-batch Algorithm with a random reshuffling method featuring a sufficient decrease condition and a line-search procedure to ensure loss reduction per epoch, along with its deterministic proof of global convergence to a stationary point. To evaluate the F-CMA, we integrate it into conventional training protocols for classification tasks involving both convolutional neural networks and vision transformer models, allowing for a direct comparison with popular optimizers. Computational tests show significant improvements, including a decrease in the overall training time by up to 68%, an increase in per-epoch efficiency by up to 20%, and in model accuracy by up to 5%.
STLight: a Fully Convolutional Approach for Efficient Predictive Learning by Spatio-Temporal joint Processing
Nov 15, 2024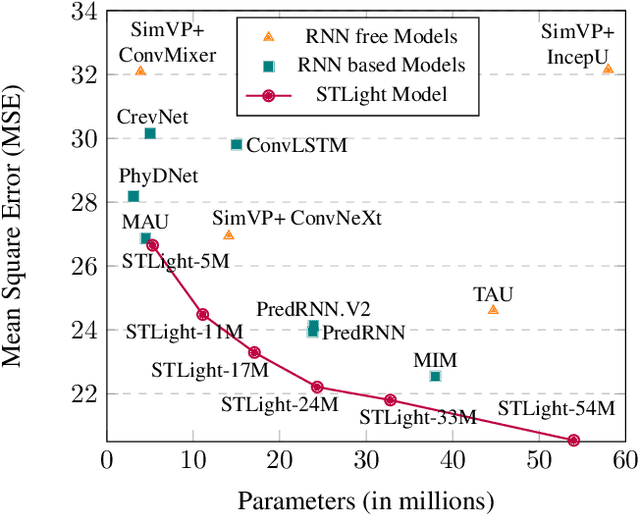

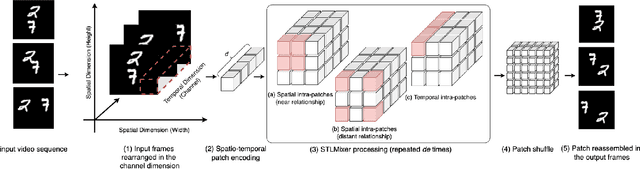

Spatio-Temporal predictive Learning is a self-supervised learning paradigm that enables models to identify spatial and temporal patterns by predicting future frames based on past frames. Traditional methods, which use recurrent neural networks to capture temporal patterns, have proven their effectiveness but come with high system complexity and computational demand. Convolutions could offer a more efficient alternative but are limited by their characteristic of treating all previous frames equally, resulting in poor temporal characterization, and by their local receptive field, limiting the capacity to capture distant correlations among frames. In this paper, we propose STLight, a novel method for spatio-temporal learning that relies solely on channel-wise and depth-wise convolutions as learnable layers. STLight overcomes the limitations of traditional convolutional approaches by rearranging spatial and temporal dimensions together, using a single convolution to mix both types of features into a comprehensive spatio-temporal patch representation. This representation is then processed in a purely convolutional framework, capable of focusing simultaneously on the interaction among near and distant patches, and subsequently allowing for efficient reconstruction of the predicted frames. Our architecture achieves state-of-the-art performance on STL benchmarks across different datasets and settings, while significantly improving computational efficiency in terms of parameters and computational FLOPs. The code is publicly available
On the impact of key design aspects in simulated Hybrid Quantum Neural Networks for Earth Observation
Oct 11, 2024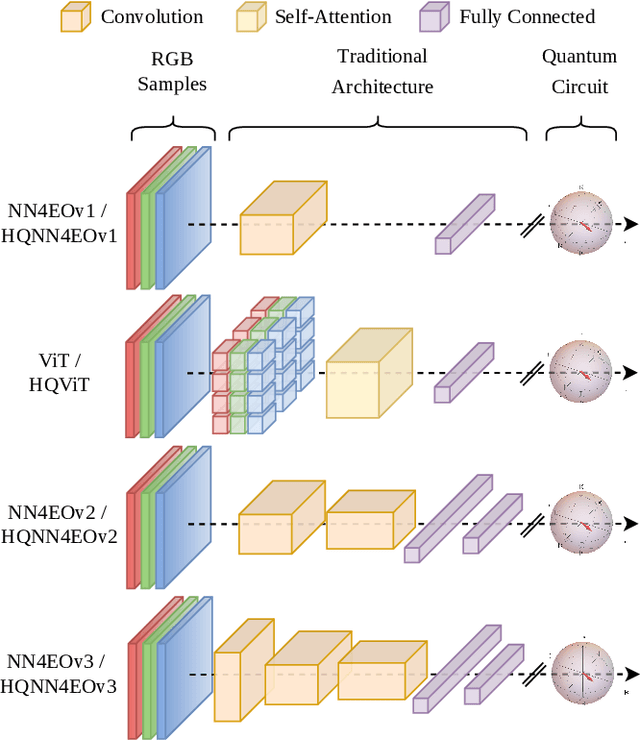
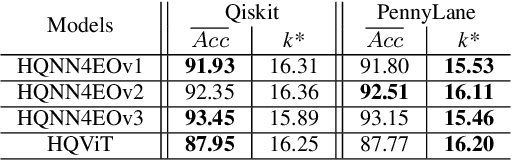
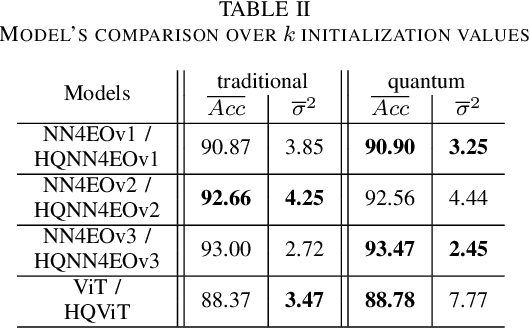
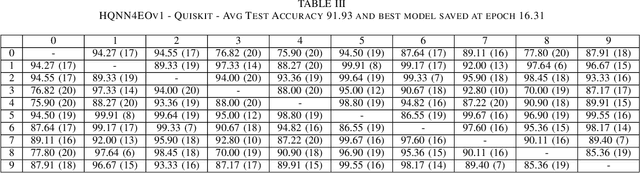
Quantum computing has introduced novel perspectives for tackling and improving machine learning tasks. Moreover, the integration of quantum technologies together with well-known deep learning (DL) architectures has emerged as a potential research trend gaining attraction across various domains, such as Earth Observation (EO) and many other research fields. However, prior related works in EO literature have mainly focused on convolutional architectural advancements, leaving several essential topics unexplored. Consequently, this research investigates through three cases of study fundamental aspects of hybrid quantum machine models for EO tasks aiming to provide a solid groundwork for future research studies towards more adequate simulations and looking at the post-NISQ era. More in detail, we firstly (1) investigate how different quantum libraries behave when training hybrid quantum models, assessing their computational efficiency and effectiveness. Secondly, (2) we analyze the stability/sensitivity to initialization values (i.e., seed values) in both traditional model and quantum-enhanced counterparts. Finally, (3) we explore the benefits of hybrid quantum attention-based models in EO applications, examining how integrating quantum circuits into ViTs can improve model performance.