 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWILD: a new in-the-Wild Image Linkage Dataset for synthetic image attribution
Apr 29, 2025Synthetic image source attribution is an open challenge, with an increasing number of image generators being released yearly. The complexity and the sheer number of available generative techniques, as well as the scarcity of high-quality open source datasets of diverse nature for this task, make training and benchmarking synthetic image source attribution models very challenging. WILD is a new in-the-Wild Image Linkage Dataset designed to provide a powerful training and benchmarking tool for synthetic image attribution models. The dataset is built out of a closed set of 10 popular commercial generators, which constitutes the training base of attribution models, and an open set of 10 additional generators, simulating a real-world in-the-wild scenario. Each generator is represented by 1,000 images, for a total of 10,000 images in the closed set and 10,000 images in the open set. Half of the images are post-processed with a wide range of operators. WILD allows benchmarking attribution models in a wide range of tasks, including closed and open set identification and verification, and robust attribution with respect to post-processing and adversarial attacks. Models trained on WILD are expected to benefit from the challenging scenario represented by the dataset itself. Moreover, an assessment of seven baseline methodologies on closed and open set attribution is presented, including robustness tests with respect to post-processing.
Leveraging Land Cover Priors for Isoprene Emission Super-Resolution
Mar 24, 2025Remote sensing plays a crucial role in monitoring Earth's ecosystems, yet satellite-derived data often suffer from limited spatial resolution, restricting their applicability in atmospheric modeling and climate research. In this work, we propose a deep learning-based Super-Resolution (SR) framework that leverages land cover information to enhance the spatial accuracy of Biogenic Volatile Organic Compounds (BVOCs) emissions, with a particular focus on isoprene. Our approach integrates land cover priors as emission drivers, capturing spatial patterns more effectively than traditional methods. We evaluate the model's performance across various climate conditions and analyze statistical correlations between isoprene emissions and key environmental information such as cropland and tree cover data. Additionally, we assess the generalization capabilities of our SR model by applying it to unseen climate zones and geographical regions. Experimental results demonstrate that incorporating land cover data significantly improves emission SR accuracy, particularly in heterogeneous landscapes. This study contributes to atmospheric chemistry and climate modeling by providing a cost-effective, data-driven approach to refining BVOC emission maps. The proposed method enhances the usability of satellite-based emissions data, supporting applications in air quality forecasting, climate impact assessments, and environmental studies.
Is JPEG AI going to change image forensics?
Dec 04, 2024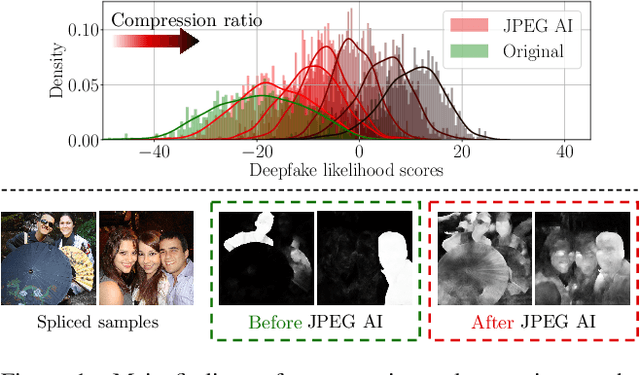
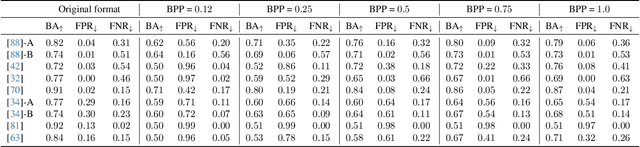
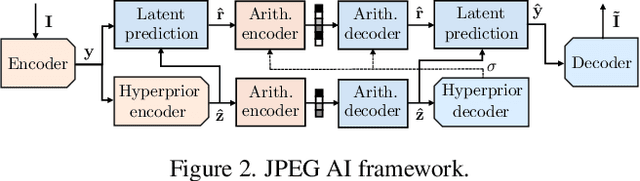
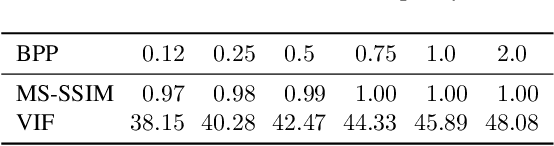
In this paper, we investigate the counter-forensic effects of the forthcoming JPEG AI standard based on neural image compression, focusing on two critical areas: deepfake image detection and image splicing localization. Neural image compression leverages advanced neural network algorithms to achieve higher compression rates while maintaining image quality. However, it introduces artifacts that closely resemble those generated by image synthesis techniques and image splicing pipelines, complicating the work of researchers when discriminating pristine from manipulated content. We comprehensively analyze JPEG AI's counter-forensic effects through extensive experiments on several state-of-the-art detectors and datasets. Our results demonstrate that an increase in false alarms impairs the performance of leading forensic detectors when analyzing genuine content processed through JPEG AI. By exposing the vulnerabilities of the available forensic tools we aim to raise the urgent need for multimedia forensics researchers to include JPEG AI images in their experimental setups and develop robust forensic techniques to distinguish between neural compression artifacts and actual manipulations.
POLIPHONE: A Dataset for Smartphone Model Identification from Audio Recordings
Oct 08, 2024When dealing with multimedia data, source attribution is a key challenge from a forensic perspective. This task aims to determine how a given content was captured, providing valuable insights for various applications, including legal proceedings and integrity investigations. The source attribution problem has been addressed in different domains, from identifying the camera model used to capture specific photographs to detecting the synthetic speech generator or microphone model used to create or record given audio tracks. Recent advancements in this area rely heavily on machine learning and data-driven techniques, which often outperform traditional signal processing-based methods. However, a drawback of these systems is their need for large volumes of training data, which must reflect the latest technological trends to produce accurate and reliable predictions. This presents a significant challenge, as the rapid pace of technological progress makes it difficult to maintain datasets that are up-to-date with real-world conditions. For instance, in the task of smartphone model identification from audio recordings, the available datasets are often outdated or acquired inconsistently, making it difficult to develop solutions that are valid beyond a research environment. In this paper we present POLIPHONE, a dataset for smartphone model identification from audio recordings. It includes data from 20 recent smartphones recorded in a controlled environment to ensure reproducibility and scalability for future research. The released tracks contain audio data from various domains (i.e., speech, music, environmental sounds), making the corpus versatile and applicable to a wide range of use cases. We also present numerous experiments to benchmark the proposed dataset using a state-of-the-art classifier for smartphone model identification from audio recordings.
Explainable Artifacts for Synthetic Western Blot Source Attribution
Sep 27, 2024



Recent advancements in artificial intelligence have enabled generative models to produce synthetic scientific images that are indistinguishable from pristine ones, posing a challenge even for expert scientists habituated to working with such content. When exploited by organizations known as paper mills, which systematically generate fraudulent articles, these technologies can significantly contribute to the spread of misinformation about ungrounded science, potentially undermining trust in scientific research. While previous studies have explored black-box solutions, such as Convolutional Neural Networks, for identifying synthetic content, only some have addressed the challenge of generalizing across different models and providing insight into the artifacts in synthetic images that inform the detection process. This study aims to identify explainable artifacts generated by state-of-the-art generative models (e.g., Generative Adversarial Networks and Diffusion Models) and leverage them for open-set identification and source attribution (i.e., pointing to the model that created the image).
Localization of Synthetic Manipulations in Western Blot Images
Aug 25, 2024



Recent breakthroughs in deep learning and generative systems have significantly fostered the creation of synthetic media, as well as the local alteration of real content via the insertion of highly realistic synthetic manipulations. Local image manipulation, in particular, poses serious challenges to the integrity of digital content and societal trust. This problem is not only confined to multimedia data, but also extends to biological images included in scientific publications, like images depicting Western blots. In this work, we address the task of localizing synthetic manipulations in Western blot images. To discriminate between pristine and synthetic pixels of an analyzed image, we propose a synthetic detector that operates on small patches extracted from the image. We aggregate patch contributions to estimate a tampering heatmap, highlighting synthetic pixels out of pristine ones. Our methodology proves effective when tested over two manipulated Western blot image datasets, one altered automatically and the other manually by exploiting advanced AI-based image manipulation tools that are unknown at our training stage. We also explore the robustness of our method over an external dataset of other scientific images depicting different semantics, manipulated through unseen generation techniques.
Deepfake Media Forensics: State of the Art and Challenges Ahead
Aug 01, 2024AI-generated synthetic media, also called Deepfakes, have significantly influenced so many domains, from entertainment to cybersecurity. Generative Adversarial Networks (GANs) and Diffusion Models (DMs) are the main frameworks used to create Deepfakes, producing highly realistic yet fabricated content. While these technologies open up new creative possibilities, they also bring substantial ethical and security risks due to their potential misuse. The rise of such advanced media has led to the development of a cognitive bias known as Impostor Bias, where individuals doubt the authenticity of multimedia due to the awareness of AI's capabilities. As a result, Deepfake detection has become a vital area of research, focusing on identifying subtle inconsistencies and artifacts with machine learning techniques, especially Convolutional Neural Networks (CNNs). Research in forensic Deepfake technology encompasses five main areas: detection, attribution and recognition, passive authentication, detection in realistic scenarios, and active authentication. Each area tackles specific challenges, from tracing the origins of synthetic media and examining its inherent characteristics for authenticity. This paper reviews the primary algorithms that address these challenges, examining their advantages, limitations, and future prospects.
When Synthetic Traces Hide Real Content: Analysis of Stable Diffusion Image Laundering
Jul 15, 2024
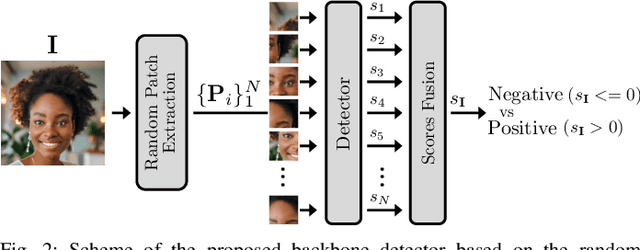
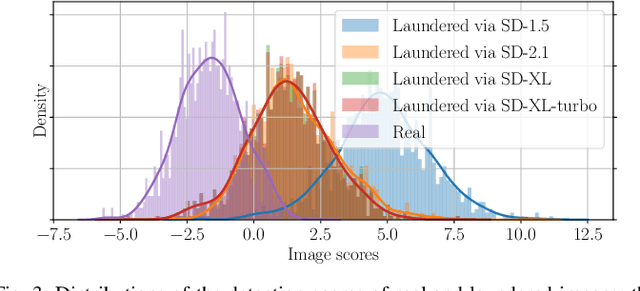
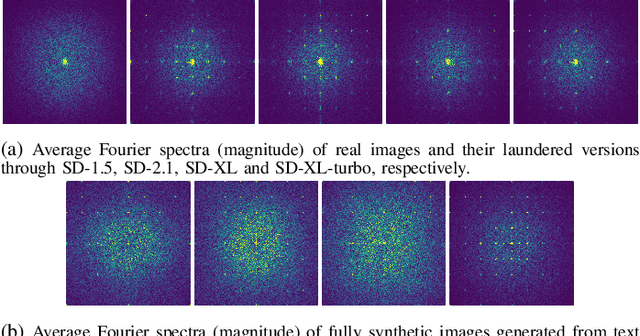
In recent years, methods for producing highly realistic synthetic images have significantly advanced, allowing the creation of high-quality images from text prompts that describe the desired content. Even more impressively, Stable Diffusion (SD) models now provide users with the option of creating synthetic images in an image-to-image translation fashion, modifying images in the latent space of advanced autoencoders. This striking evolution, however, brings an alarming consequence: it is possible to pass an image through SD autoencoders to reproduce a synthetic copy of the image with high realism and almost no visual artifacts. This process, known as SD image laundering, can transform real images into lookalike synthetic ones and risks complicating forensic analysis for content authenticity verification. Our paper investigates the forensic implications of image laundering, revealing a serious potential to obscure traces of real content, including sensitive and harmful materials that could be mistakenly classified as synthetic, thereby undermining the protection of individuals depicted. To address this issue, we propose a two-stage detection pipeline that effectively differentiates between pristine, laundered, and fully synthetic images (those generated from text prompts), showing robustness across various conditions. Finally, we highlight another alarming property of image laundering, which appears to mask the unique artifacts exploited by forensic detectors to solve the camera model identification task, strongly undermining their performance. Our experimental code is available at https://github.com/polimi-ispl/synthetic-image-detection.
Hiding Local Manipulations on SAR Images: a Counter-Forensic Attack
Jul 09, 2024


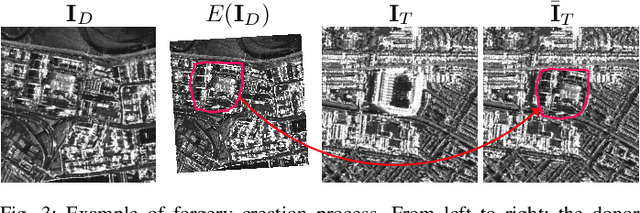
The vast accessibility of Synthetic Aperture Radar (SAR) images through online portals has propelled the research across various fields. This widespread use and easy availability have unfortunately made SAR data susceptible to malicious alterations, such as local editing applied to the images for inserting or covering the presence of sensitive targets. Vulnerability is further emphasized by the fact that most SAR products, despite their original complex nature, are often released as amplitude-only information, allowing even inexperienced attackers to edit and easily alter the pixel content. To contrast malicious manipulations, in the last years the forensic community has begun to dig into the SAR manipulation issue, proposing detectors that effectively localize the tampering traces in amplitude images. Nonetheless, in this paper we demonstrate that an expert practitioner can exploit the complex nature of SAR data to obscure any signs of manipulation within a locally altered amplitude image. We refer to this approach as a counter-forensic attack. To achieve the concealment of manipulation traces, the attacker can simulate a re-acquisition of the manipulated scene by the SAR system that initially generated the pristine image. In doing so, the attacker can obscure any evidence of manipulation, making it appear as if the image was legitimately produced by the system. We assess the effectiveness of the proposed counter-forensic approach across diverse scenarios, examining various manipulation operations. The obtained results indicate that our devised attack successfully eliminates traces of manipulation, deceiving even the most advanced forensic detectors.
Back to the Future: GNN-based NO$_2$ Forecasting via Future Covariates
Apr 08, 2024Due to the latest environmental concerns in keeping at bay contaminants emissions in urban areas, air pollution forecasting has been rising the forefront of all researchers around the world. When predicting pollutant concentrations, it is common to include the effects of environmental factors that influence these concentrations within an extended period, like traffic, meteorological conditions and geographical information. Most of the existing approaches exploit this information as past covariates, i.e., past exogenous variables that affected the pollutant but were not affected by it. In this paper, we present a novel forecasting methodology to predict NO$_2$ concentration via both past and future covariates. Future covariates are represented by weather forecasts and future calendar events, which are already known at prediction time. In particular, we deal with air quality observations in a city-wide network of ground monitoring stations, modeling the data structure and estimating the predictions with a Spatiotemporal Graph Neural Network (STGNN). We propose a conditioning block that embeds past and future covariates into the current observations. After extracting meaningful spatiotemporal representations, these are fused together and projected into the forecasting horizon to generate the final prediction. To the best of our knowledge, it is the first time that future covariates are included in time series predictions in a structured way. Remarkably, we find that conditioning on future weather information has a greater impact than considering past traffic conditions. We release our code implementation at https://github.com/polimi-ispl/MAGCRN.