 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProto-LeakNet: Towards Signal-Leak Aware Attribution in Synthetic Human Face Imagery
Nov 15, 2025
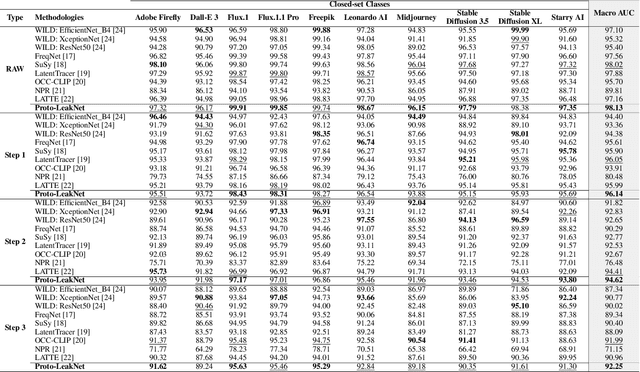


The growing sophistication of synthetic image and deepfake generation models has turned source attribution and authenticity verification into a critical challenge for modern computer vision systems. Recent studies suggest that diffusion pipelines unintentionally imprint persistent statistical traces, known as signal-leaks, within their outputs, particularly in latent representations. Building on this observation, we propose Proto-LeakNet, a signal-leak-aware and interpretable attribution framework that integrates closed-set classification with a density-based open-set evaluation on the learned embeddings, enabling analysis of unseen generators without retraining. Acting in the latent domain of diffusion models, our method re-simulates partial forward diffusion to expose residual generator-specific cues. A temporal attention encoder aggregates multi-step latent features, while a feature-weighted prototype head structures the embedding space and enables transparent attribution. Trained solely on closed data and achieving a Macro AUC of 98.13%, Proto-LeakNet learns a latent geometry that remains robust under post-processing, surpassing state-of-the-art methods, and achieves strong separability both between real images and known generators, and between known and unseen ones. The codebase will be available after acceptance.
Deepfake Forensic Analysis: Source Dataset Attribution and Legal Implications of Synthetic Media Manipulation
May 16, 2025Synthetic media generated by Generative Adversarial Networks (GANs) pose significant challenges in verifying authenticity and tracing dataset origins, raising critical concerns in copyright enforcement, privacy protection, and legal compliance. This paper introduces a novel forensic framework for identifying the training dataset (e.g., CelebA or FFHQ) of GAN-generated images through interpretable feature analysis. By integrating spectral transforms (Fourier/DCT), color distribution metrics, and local feature descriptors (SIFT), our pipeline extracts discriminative statistical signatures embedded in synthetic outputs. Supervised classifiers (Random Forest, SVM, XGBoost) achieve 98-99% accuracy in binary classification (real vs. synthetic) and multi-class dataset attribution across diverse GAN architectures (StyleGAN, AttGAN, GDWCT, StarGAN, and StyleGAN2). Experimental results highlight the dominance of frequency-domain features (DCT/FFT) in capturing dataset-specific artifacts, such as upsampling patterns and spectral irregularities, while color histograms reveal implicit regularization strategies in GAN training. We further examine legal and ethical implications, showing how dataset attribution can address copyright infringement, unauthorized use of personal data, and regulatory compliance under frameworks like GDPR and California's AB 602. Our framework advances accountability and governance in generative modeling, with applications in digital forensics, content moderation, and intellectual property litigation.
End-to-end Audio Deepfake Detection from RAW Waveforms: a RawNet-Based Approach with Cross-Dataset Evaluation
Apr 30, 2025



Audio deepfakes represent a growing threat to digital security and trust, leveraging advanced generative models to produce synthetic speech that closely mimics real human voices. Detecting such manipulations is especially challenging under open-world conditions, where spoofing methods encountered during testing may differ from those seen during training. In this work, we propose an end-to-end deep learning framework for audio deepfake detection that operates directly on raw waveforms. Our model, RawNetLite, is a lightweight convolutional-recurrent architecture designed to capture both spectral and temporal features without handcrafted preprocessing. To enhance robustness, we introduce a training strategy that combines data from multiple domains and adopts Focal Loss to emphasize difficult or ambiguous samples. We further demonstrate that incorporating codec-based manipulations and applying waveform-level audio augmentations (e.g., pitch shifting, noise, and time stretching) leads to significant generalization improvements under realistic acoustic conditions. The proposed model achieves over 99.7% F1 and 0.25% EER on in-domain data (FakeOrReal), and up to 83.4% F1 with 16.4% EER on a challenging out-of-distribution test set (AVSpoof2021 + CodecFake). These findings highlight the importance of diverse training data, tailored objective functions and audio augmentations in building resilient and generalizable audio forgery detectors. Code and pretrained models are available at https://iplab.dmi.unict.it/mfs/Deepfakes/PaperRawNet2025/.
WILD: a new in-the-Wild Image Linkage Dataset for synthetic image attribution
Apr 29, 2025Synthetic image source attribution is an open challenge, with an increasing number of image generators being released yearly. The complexity and the sheer number of available generative techniques, as well as the scarcity of high-quality open source datasets of diverse nature for this task, make training and benchmarking synthetic image source attribution models very challenging. WILD is a new in-the-Wild Image Linkage Dataset designed to provide a powerful training and benchmarking tool for synthetic image attribution models. The dataset is built out of a closed set of 10 popular commercial generators, which constitutes the training base of attribution models, and an open set of 10 additional generators, simulating a real-world in-the-wild scenario. Each generator is represented by 1,000 images, for a total of 10,000 images in the closed set and 10,000 images in the open set. Half of the images are post-processed with a wide range of operators. WILD allows benchmarking attribution models in a wide range of tasks, including closed and open set identification and verification, and robust attribution with respect to post-processing and adversarial attacks. Models trained on WILD are expected to benefit from the challenging scenario represented by the dataset itself. Moreover, an assessment of seven baseline methodologies on closed and open set attribution is presented, including robustness tests with respect to post-processing.
Enhancing Crime Scene Investigations through Virtual Reality and Deep Learning Techniques
Sep 27, 2024



The analysis of a crime scene is a pivotal activity in forensic investigations. Crime Scene Investigators and forensic science practitioners rely on best practices, standard operating procedures, and critical thinking, to produce rigorous scientific reports to document the scenes of interest and meet the quality standards expected in the courts. However, crime scene examination is a complex and multifaceted task often performed in environments susceptible to deterioration, contamination, and alteration, despite the use of contact-free and non-destructive methods of analysis. In this context, the documentation of the sites, and the identification and isolation of traces of evidential value remain challenging endeavours. In this paper, we propose a photogrammetric reconstruction of the crime scene for inspection in virtual reality (VR) and focus on fully automatic object recognition with deep learning (DL) algorithms through a client-server architecture. A pre-trained Faster-RCNN model was chosen as the best method that can best categorize relevant objects at the scene, selected by experts in the VR environment. These operations can considerably improve and accelerate crime scene analysis and help the forensic expert in extracting measurements and analysing in detail the objects under analysis. Experimental results on a simulated crime scene have shown that the proposed method can be effective in finding and recognizing objects with potential evidentiary value, enabling timely analyses of crime scenes, particularly those with health and safety risks (e.g. fires, explosions, chemicals, etc.), while minimizing subjective bias and contamination of the scene.
Deepfake Media Forensics: State of the Art and Challenges Ahead
Aug 01, 2024AI-generated synthetic media, also called Deepfakes, have significantly influenced so many domains, from entertainment to cybersecurity. Generative Adversarial Networks (GANs) and Diffusion Models (DMs) are the main frameworks used to create Deepfakes, producing highly realistic yet fabricated content. While these technologies open up new creative possibilities, they also bring substantial ethical and security risks due to their potential misuse. The rise of such advanced media has led to the development of a cognitive bias known as Impostor Bias, where individuals doubt the authenticity of multimedia due to the awareness of AI's capabilities. As a result, Deepfake detection has become a vital area of research, focusing on identifying subtle inconsistencies and artifacts with machine learning techniques, especially Convolutional Neural Networks (CNNs). Research in forensic Deepfake technology encompasses five main areas: detection, attribution and recognition, passive authentication, detection in realistic scenarios, and active authentication. Each area tackles specific challenges, from tracing the origins of synthetic media and examining its inherent characteristics for authenticity. This paper reviews the primary algorithms that address these challenges, examining their advantages, limitations, and future prospects.
DeepFeatureX Net: Deep Features eXtractors based Network for discriminating synthetic from real images
Apr 24, 2024



Deepfakes, synthetic images generated by deep learning algorithms, represent one of the biggest challenges in the field of Digital Forensics. The scientific community is working to develop approaches that can discriminate the origin of digital images (real or AI-generated). However, these methodologies face the challenge of generalization, that is, the ability to discern the nature of an image even if it is generated by an architecture not seen during training. This usually leads to a drop in performance. In this context, we propose a novel approach based on three blocks called Base Models, each of which is responsible for extracting the discriminative features of a specific image class (Diffusion Model-generated, GAN-generated, or real) as it is trained by exploiting deliberately unbalanced datasets. The features extracted from each block are then concatenated and processed to discriminate the origin of the input image. Experimental results showed that this approach not only demonstrates good robust capabilities to JPEG compression but also outperforms state-of-the-art methods in several generalization tests. Code, models and dataset are available at https://github.com/opontorno/block-based_deepfake-detection.
On the Exploitation of DCT-Traces in the Generative-AI Domain
Feb 12, 2024



Deepfakes represent one of the toughest challenges in the world of Cybersecurity and Digital Forensics, especially considering the high-quality results obtained with recent generative AI-based solutions. Almost all generative models leave unique traces in synthetic data that, if analyzed and identified in detail, can be exploited to improve the generalization limitations of existing deepfake detectors. In this paper we analyzed deepfake images in the frequency domain generated by both GAN and Diffusion Model engines, examining in detail the underlying statistical distribution of Discrete Cosine Transform (DCT) coefficients. Recognizing that not all coefficients contribute equally to image detection, we hypothesize the existence of a unique "discriminative fingerprint", embedded in specific combinations of coefficients. To identify them, Machine Learning classifiers were trained on various combinations of coefficients. In addition, the Explainable AI (XAI) LIME algorithm was used to search for intrinsic discriminative combinations of coefficients. Finally, we performed a robustness test to analyze the persistence of traces by applying JPEG compression. The experimental results reveal the existence of traces left by the generative models that are more discriminative and persistent at JPEG attacks.
MITS-GAN: Safeguarding Medical Imaging from Tampering with Generative Adversarial Networks
Jan 17, 2024



The progress in generative models, particularly Generative Adversarial Networks (GANs), opened new possibilities for image generation but raised concerns about potential malicious uses, especially in sensitive areas like medical imaging. This study introduces MITS-GAN, a novel approach to prevent tampering in medical images, with a specific focus on CT scans. The approach disrupts the output of the attacker's CT-GAN architecture by introducing imperceptible but yet precise perturbations. Specifically, the proposed approach involves the introduction of appropriate Gaussian noise to the input as a protective measure against various attacks. Our method aims to enhance tamper resistance, comparing favorably to existing techniques. Experimental results on a CT scan dataset demonstrate MITS-GAN's superior performance, emphasizing its ability to generate tamper-resistant images with negligible artifacts. As image tampering in medical domains poses life-threatening risks, our proactive approach contributes to the responsible and ethical use of generative models. This work provides a foundation for future research in countering cyber threats in medical imaging. Models and codes are publicly available at the following link \url{https://iplab.dmi.unict.it/MITS-GAN-2024/}.
A Novel Dataset for Non-Destructive Inspection of Handwritten Documents
Jan 09, 2024Forensic handwriting examination is a branch of Forensic Science that aims to examine handwritten documents in order to properly define or hypothesize the manuscript's author. These analysis involves comparing two or more (digitized) documents through a comprehensive comparison of intrinsic local and global features. If a correlation exists and specific best practices are satisfied, then it will be possible to affirm that the documents under analysis were written by the same individual. The need to create sophisticated tools capable of extracting and comparing significant features has led to the development of cutting-edge software with almost entirely automated processes, improving the forensic examination of handwriting and achieving increasingly objective evaluations. This is made possible by algorithmic solutions based on purely mathematical concepts. Machine Learning and Deep Learning models trained with specific datasets could turn out to be the key elements to best solve the task at hand. In this paper, we proposed a new and challenging dataset consisting of two subsets: the first consists of 21 documents written either by the classic ``pen and paper" approach (and later digitized) and directly acquired on common devices such as tablets; the second consists of 362 handwritten manuscripts by 124 different people, acquired following a specific pipeline. Our study pioneered a comparison between traditionally handwritten documents and those produced with digital tools (e.g., tablets). Preliminary results on the proposed datasets show that 90% classification accuracy can be achieved on the first subset (documents written on both paper and pen and later digitized and on tablets) and 96% on the second portion of the data. The datasets are available at https://iplab.dmi.unict.it/mfs/forensic-handwriting-analysis/novel-dataset-2023/.