 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMITS-GAN: Safeguarding Medical Imaging from Tampering with Generative Adversarial Networks
Jan 17, 2024



The progress in generative models, particularly Generative Adversarial Networks (GANs), opened new possibilities for image generation but raised concerns about potential malicious uses, especially in sensitive areas like medical imaging. This study introduces MITS-GAN, a novel approach to prevent tampering in medical images, with a specific focus on CT scans. The approach disrupts the output of the attacker's CT-GAN architecture by introducing imperceptible but yet precise perturbations. Specifically, the proposed approach involves the introduction of appropriate Gaussian noise to the input as a protective measure against various attacks. Our method aims to enhance tamper resistance, comparing favorably to existing techniques. Experimental results on a CT scan dataset demonstrate MITS-GAN's superior performance, emphasizing its ability to generate tamper-resistant images with negligible artifacts. As image tampering in medical domains poses life-threatening risks, our proactive approach contributes to the responsible and ethical use of generative models. This work provides a foundation for future research in countering cyber threats in medical imaging. Models and codes are publicly available at the following link \url{https://iplab.dmi.unict.it/MITS-GAN-2024/}.
A Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training
Oct 03, 2022
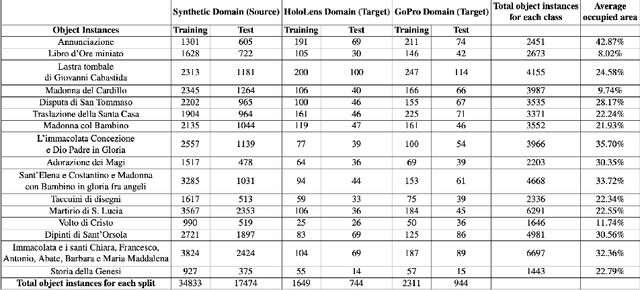

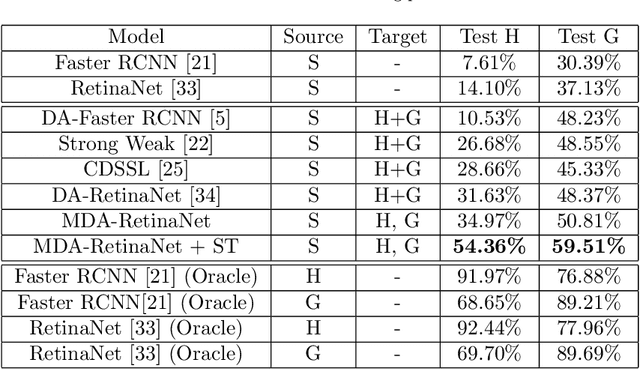
Object detection algorithms allow to enable many interesting applications which can be implemented in different devices, such as smartphones and wearable devices. In the context of a cultural site, implementing these algorithms in a wearable device, such as a pair of smart glasses, allow to enable the use of augmented reality (AR) to show extra information about the artworks and enrich the visitors' experience during their tour. However, object detection algorithms require to be trained on many well annotated examples to achieve reasonable results. This brings a major limitation since the annotation process requires human supervision which makes it expensive in terms of time and costs. A possible solution to reduce these costs consist in exploiting tools to automatically generate synthetic labeled images from a 3D model of the site. However, models trained with synthetic data do not generalize on real images acquired in the target scenario in which they are supposed to be used. Furthermore, object detectors should be able to work with different wearable devices or different mobile devices, which makes generalization even harder. In this paper, we present a new dataset collected in a cultural site to study the problem of domain adaptation for object detection in the presence of multiple unlabeled target domains corresponding to different cameras and a labeled source domain obtained considering synthetic images for training purposes. We present a new domain adaptation method which outperforms current state-of-the-art approaches combining the benefits of aligning the domains at the feature and pixel level with a self-training process. We release the dataset at the following link https://iplab.dmi.unict.it/OBJ-MDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/STMDA-RetinaNet.
Synthetic to Real Unsupervised Domain Adaptation for Single-Stage Artwork Recognition in Cultural Sites
Aug 04, 2020
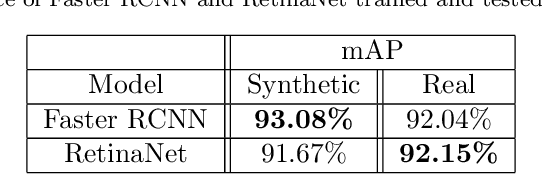

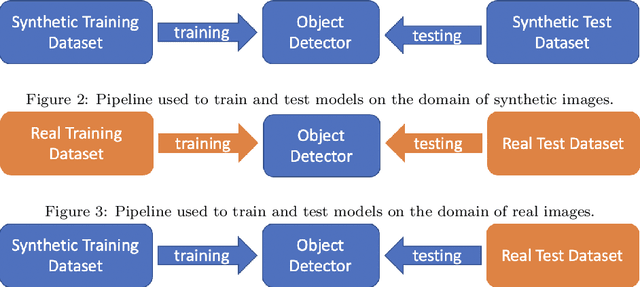
Recognizing artworks in a cultural site using images acquired from the user's point of view (First Person Vision) allows to build interesting applications for both the visitors and the site managers. However, current object detection algorithms working in fully supervised settings need to be trained with large quantities of labeled data, whose collection requires a lot of times and high costs in order to achieve good performance. Using synthetic data generated from the 3D model of the cultural site to train the algorithms can reduce these costs. On the other hand, when these models are tested with real images, a significant drop in performance is observed due to the differences between real and synthetic images. In this study we consider the problem of Unsupervised Domain Adaptation for object detection in cultural sites. To address this problem, we created a new dataset containing both synthetic and real images of 16 different artworks. We hence investigated different domain adaptation techniques based on one-stage and two-stage object detector, image-to-image translation and feature alignment. Based on the observation that single-stage detectors are more robust to the domain shift in the considered settings, we proposed a new method based on RetinaNet and feature alignment that we called DA-RetinaNet. The proposed approach achieves better results than compared methods. To support research in this field we release the dataset at the following link https://iplab.dmi.unict.it/EGO-CH-OBJ-UDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/DA-RetinaNet.