 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic to Real Unsupervised Domain Adaptation for Single-Stage Artwork Recognition in Cultural Sites
Paper and Code

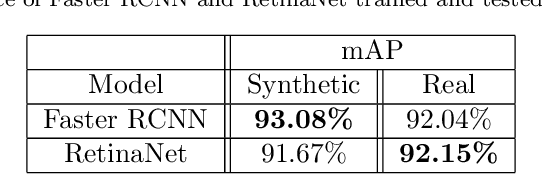

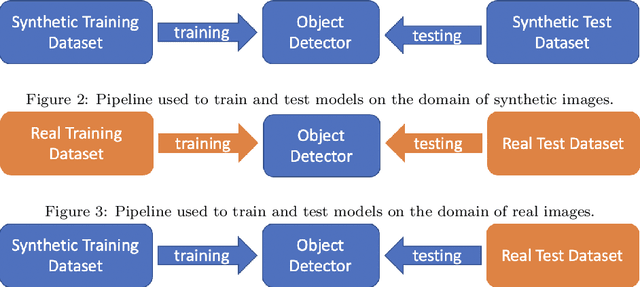
Recognizing artworks in a cultural site using images acquired from the user's point of view (First Person Vision) allows to build interesting applications for both the visitors and the site managers. However, current object detection algorithms working in fully supervised settings need to be trained with large quantities of labeled data, whose collection requires a lot of times and high costs in order to achieve good performance. Using synthetic data generated from the 3D model of the cultural site to train the algorithms can reduce these costs. On the other hand, when these models are tested with real images, a significant drop in performance is observed due to the differences between real and synthetic images. In this study we consider the problem of Unsupervised Domain Adaptation for object detection in cultural sites. To address this problem, we created a new dataset containing both synthetic and real images of 16 different artworks. We hence investigated different domain adaptation techniques based on one-stage and two-stage object detector, image-to-image translation and feature alignment. Based on the observation that single-stage detectors are more robust to the domain shift in the considered settings, we proposed a new method based on RetinaNet and feature alignment that we called DA-RetinaNet. The proposed approach achieves better results than compared methods. To support research in this field we release the dataset at the following link https://iplab.dmi.unict.it/EGO-CH-OBJ-UDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/DA-RetinaNet.