 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Attended Object Detection Using Gaze Data as Annotations
Apr 14, 2022



We consider the problem of detecting and recognizing the objects observed by visitors (i.e., attended objects) in cultural sites from egocentric vision. A standard approach to the problem involves detecting all objects and selecting the one which best overlaps with the gaze of the visitor, measured through a gaze tracker. Since labeling large amounts of data to train a standard object detector is expensive in terms of costs and time, we propose a weakly supervised version of the task which leans only on gaze data and a frame-level label indicating the class of the attended object. To study the problem, we present a new dataset composed of egocentric videos and gaze coordinates of subjects visiting a museum. We hence compare three different baselines for weakly supervised attended object detection on the collected data. Results show that the considered approaches achieve satisfactory performance in a weakly supervised manner, which allows for significant time savings with respect to a fully supervised detector based on Faster R-CNN. To encourage research on the topic, we publicly release the code and the dataset at the following url: https://iplab.dmi.unict.it/WS_OBJ_DET/
Synthetic to Real Unsupervised Domain Adaptation for Single-Stage Artwork Recognition in Cultural Sites
Aug 04, 2020
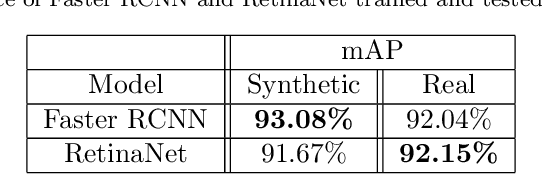

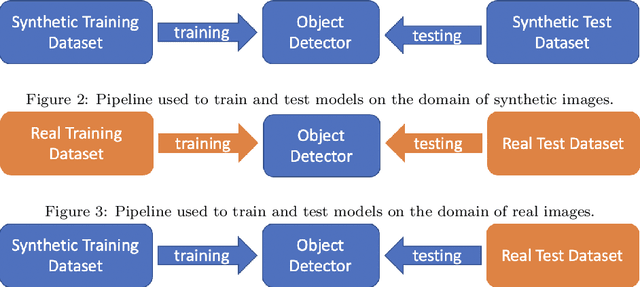
Recognizing artworks in a cultural site using images acquired from the user's point of view (First Person Vision) allows to build interesting applications for both the visitors and the site managers. However, current object detection algorithms working in fully supervised settings need to be trained with large quantities of labeled data, whose collection requires a lot of times and high costs in order to achieve good performance. Using synthetic data generated from the 3D model of the cultural site to train the algorithms can reduce these costs. On the other hand, when these models are tested with real images, a significant drop in performance is observed due to the differences between real and synthetic images. In this study we consider the problem of Unsupervised Domain Adaptation for object detection in cultural sites. To address this problem, we created a new dataset containing both synthetic and real images of 16 different artworks. We hence investigated different domain adaptation techniques based on one-stage and two-stage object detector, image-to-image translation and feature alignment. Based on the observation that single-stage detectors are more robust to the domain shift in the considered settings, we proposed a new method based on RetinaNet and feature alignment that we called DA-RetinaNet. The proposed approach achieves better results than compared methods. To support research in this field we release the dataset at the following link https://iplab.dmi.unict.it/EGO-CH-OBJ-UDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/DA-RetinaNet.
EGO-CH: Dataset and Fundamental Tasks for Visitors BehavioralUnderstanding using Egocentric Vision
Feb 03, 2020
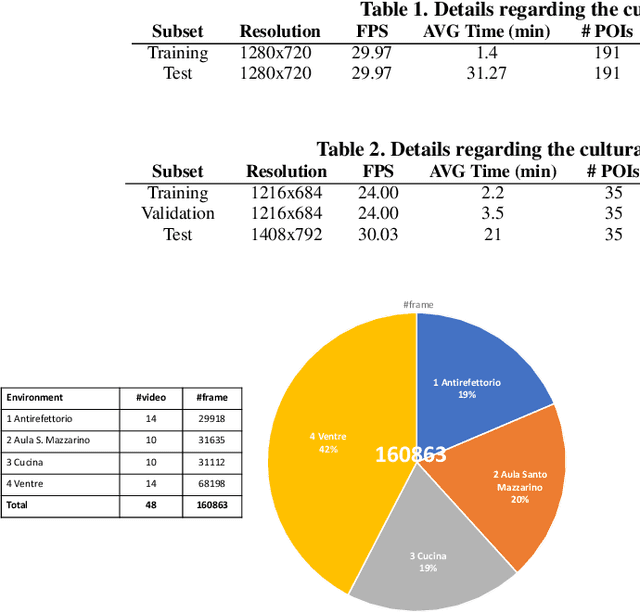
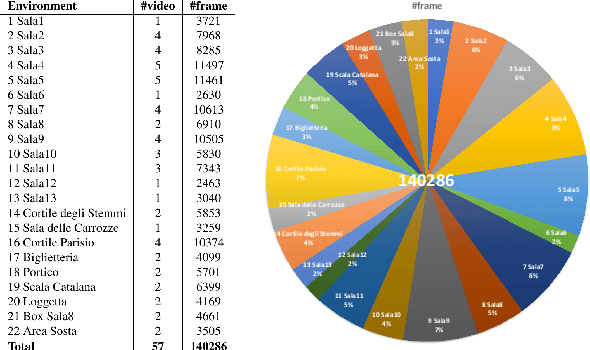

Equipping visitors of a cultural site with a wearable device allows to easily collect information about their preferences which can be exploited to improve the fruition of cultural goods with augmented reality. Moreover, egocentric video can be processed using computer vision and machine learning to enable an automated analysis of visitors' behavior. The inferred information can be used both online to assist the visitor and offline to support the manager of the site. Despite the positive impact such technologies can have in cultural heritage, the topic is currently understudied due to the limited number of public datasets suitable to study the considered problems. To address this issue, in this paper we propose EGOcentric-Cultural Heritage (EGO-CH), the first dataset of egocentric videos for visitors' behavior understanding in cultural sites. The dataset has been collected in two cultural sites and includes more than $27$ hours of video acquired by $70$ subjects, with labels for $26$ environments and over $200$ different Points of Interest. A large subset of the dataset, consisting of $60$ videos, is associated with surveys filled out by real visitors. To encourage research on the topic, we propose $4$ challenging tasks (room-based localization, point of interest/object recognition, object retrieval and survey prediction) useful to understand visitors' behavior and report baseline results on the dataset.
Egocentric Visitors Localization in Cultural Sites
Apr 10, 2019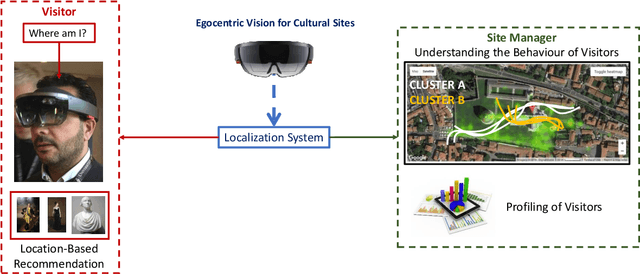


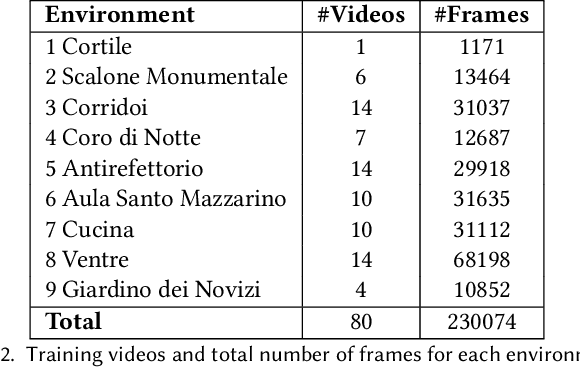
We consider the problem of localizing visitors in a cultural site from egocentric (first person) images. Localization information can be useful both to assist the user during his visit (e.g., by suggesting where to go and what to see next) and to provide behavioral information to the manager of the cultural site (e.g., how much time has been spent by visitors at a given location? What has been liked most?). To tackle the problem, we collected a large dataset of egocentric videos using two cameras: a head-mounted HoloLens device and a chest-mounted GoPro. Each frame has been labeled according to the location of the visitor and to what he was looking at. The dataset is freely available in order to encourage research in this domain. The dataset is complemented with baseline experiments performed considering a state-of-the-art method for location-based temporal segmentation of egocentric videos. Experiments show that compelling results can be achieved to extract useful information for both the visitor and the site-manager.
* To appear in ACM Journal on Computing and Cultural Heritage (JOCCH), 2019