 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training
Paper and Code

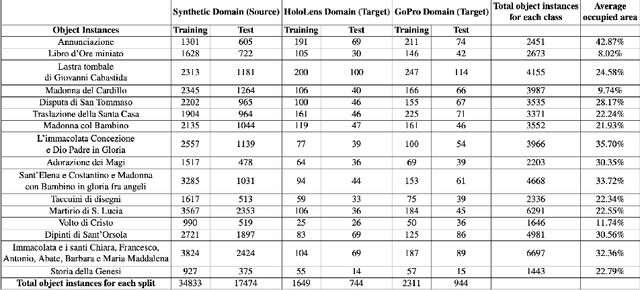

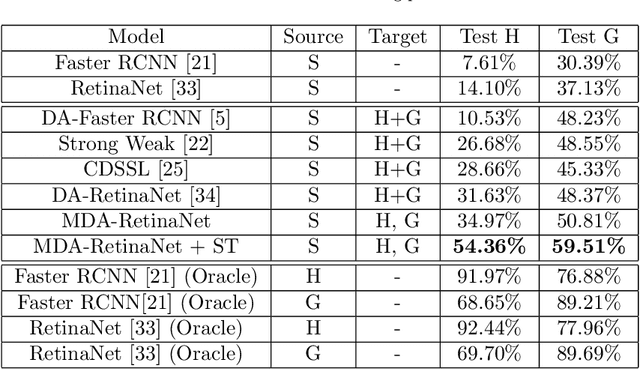
Object detection algorithms allow to enable many interesting applications which can be implemented in different devices, such as smartphones and wearable devices. In the context of a cultural site, implementing these algorithms in a wearable device, such as a pair of smart glasses, allow to enable the use of augmented reality (AR) to show extra information about the artworks and enrich the visitors' experience during their tour. However, object detection algorithms require to be trained on many well annotated examples to achieve reasonable results. This brings a major limitation since the annotation process requires human supervision which makes it expensive in terms of time and costs. A possible solution to reduce these costs consist in exploiting tools to automatically generate synthetic labeled images from a 3D model of the site. However, models trained with synthetic data do not generalize on real images acquired in the target scenario in which they are supposed to be used. Furthermore, object detectors should be able to work with different wearable devices or different mobile devices, which makes generalization even harder. In this paper, we present a new dataset collected in a cultural site to study the problem of domain adaptation for object detection in the presence of multiple unlabeled target domains corresponding to different cameras and a labeled source domain obtained considering synthetic images for training purposes. We present a new domain adaptation method which outperforms current state-of-the-art approaches combining the benefits of aligning the domains at the feature and pixel level with a self-training process. We release the dataset at the following link https://iplab.dmi.unict.it/OBJ-MDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/STMDA-RetinaNet.